LatentFlowSR is a high-fidelity audio super-resolution framework that utilizes Conditional Flow Matching (CFM) within a continuous latent space. By leveraging a noise-robust autoencoder and a U-Net-based velocity field estimator, it achieves state-of-the-art performance across speech, music, and sound effects, effectively reconstructing high-frequency details with a single-step ODE solver.
TL;DR
LatentFlowSR redefines audio super-resolution (SR) by shifting the generative process from high-dimensional waveforms to a noise-robust continuous latent space. By combining Conditional Flow Matching (CFM) with a lightweight U-Net architecture, it achieves superior high-frequency reconstruction for speech, music, and sound effects. Remarkably, it delivers SOTA performance with a single-step inference, cutting computational complexity (FLOPs) by over 90% compared to previous diffusion-based SOTA models.
Motivation: The Complexity of the High-Frequency Void
Audio super-resolution is essentially the task of "hallucinating" missing high-frequency components lost during low-bandwidth transmission. While speech SR is relatively mature, moving to music and sound effects introduces diverse harmonic patterns and irregular textures that break traditional models.
Existing SOTA methods face a trilemma:
- Waveform methods: Prohibitively slow due to sample-by-sample processing.
- Spectral methods: Lose phase information, requiring a separate vocoder.
- Discrete Latent methods: Suffer from "quantization noise" and information loss.
The authors' insight was simple yet powerful: Can we perform flow matching in a compressed but continuous space that is robust enough to handle prediction errors?
Methodology: The LatentFlowSR Framework
1. The Noise-Robust Autoencoder (NRAE)
The foundation of the model is a noise-robust autoencoder. Unlike standard AEs, the authors inject Gaussian noise () into the latent representation during training. This forces the decoder to become invariant to the slight perturbations that naturally occur when a generative model (like CFM) predicts a latent vector during inference.
2. Latent-Space Flow Matching
Instead of the iterative denoising seen in Diffusion Models (which can take 50+ steps), LatentFlowSR uses Conditional Flow Matching (CFM).
- The Goal: Map a simple Gaussian prior to the high-resolution latent distribution.
- The Tool: A U-Net-based velocity field estimation network.
- Why it works: By utilizing Optimal Transport CFM (OT-CFM), the model learns a straight-line probability path, making a single-step ODE solver (Euler) sufficient for high-quality generation.
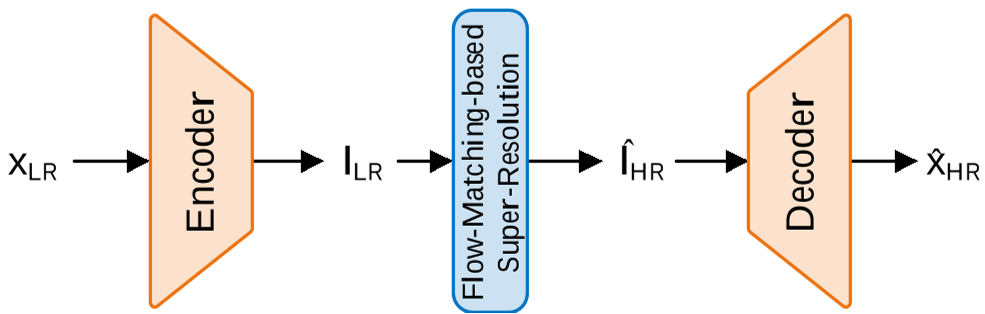 Figure 1: The holistic LatentFlowSR framework showing the transition from LR audio to the Latent space and back to HR audio.
Figure 1: The holistic LatentFlowSR framework showing the transition from LR audio to the Latent space and back to HR audio.
The velocity field network is a hybrid: ResNet blocks capture local temporal patterns, while Transformer blocks handle the long-range global dependencies of music.
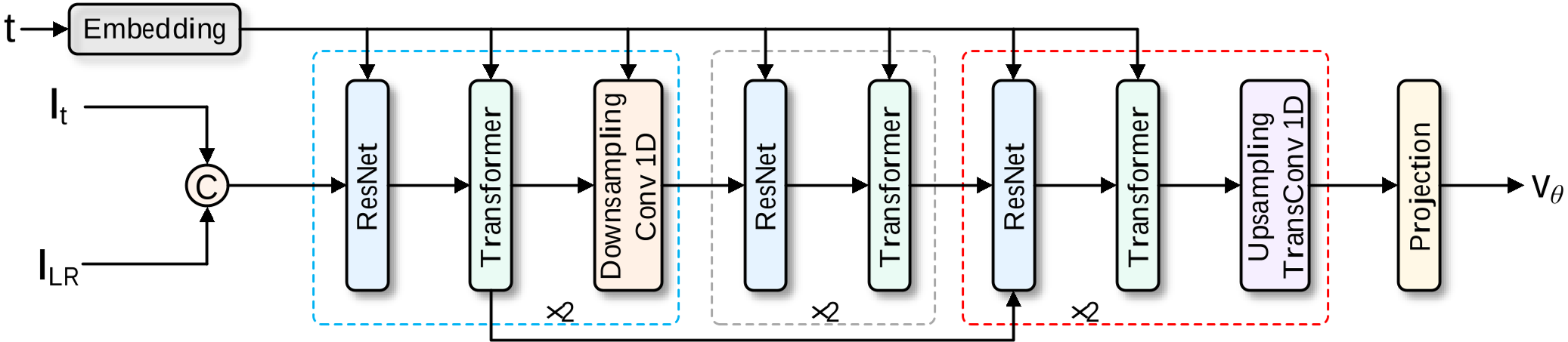 Figure 2: The U-Net style velocity field estimator combining local and global modeling.
Figure 2: The U-Net style velocity field estimator combining local and global modeling.
Experimental Performance: Small Model, Huge Sound
The evaluation spanned four tasks (8k, 12k, 16k, 24k 44.1k) across three diverse datasets including VCTK (speech), ESC-50 (environmental), and MUSDB18-HQ (music).
Key Metrics & SOTA Breakdown
- Objective Prowess: LatentFlowSR consistently achieves the lowest Log-Spectral Distance (LSD) and highest ViSQOL scores. In the music domain, it improved LSD by nearly 0.3 points over FlashSR.
- Efficiency Dominance:
- Parameters: 10.94M (vs. 258M for AudioSR/FlashSR).
- FLOPs: 0.96 G (vs. 12.13 G for FlashSR).
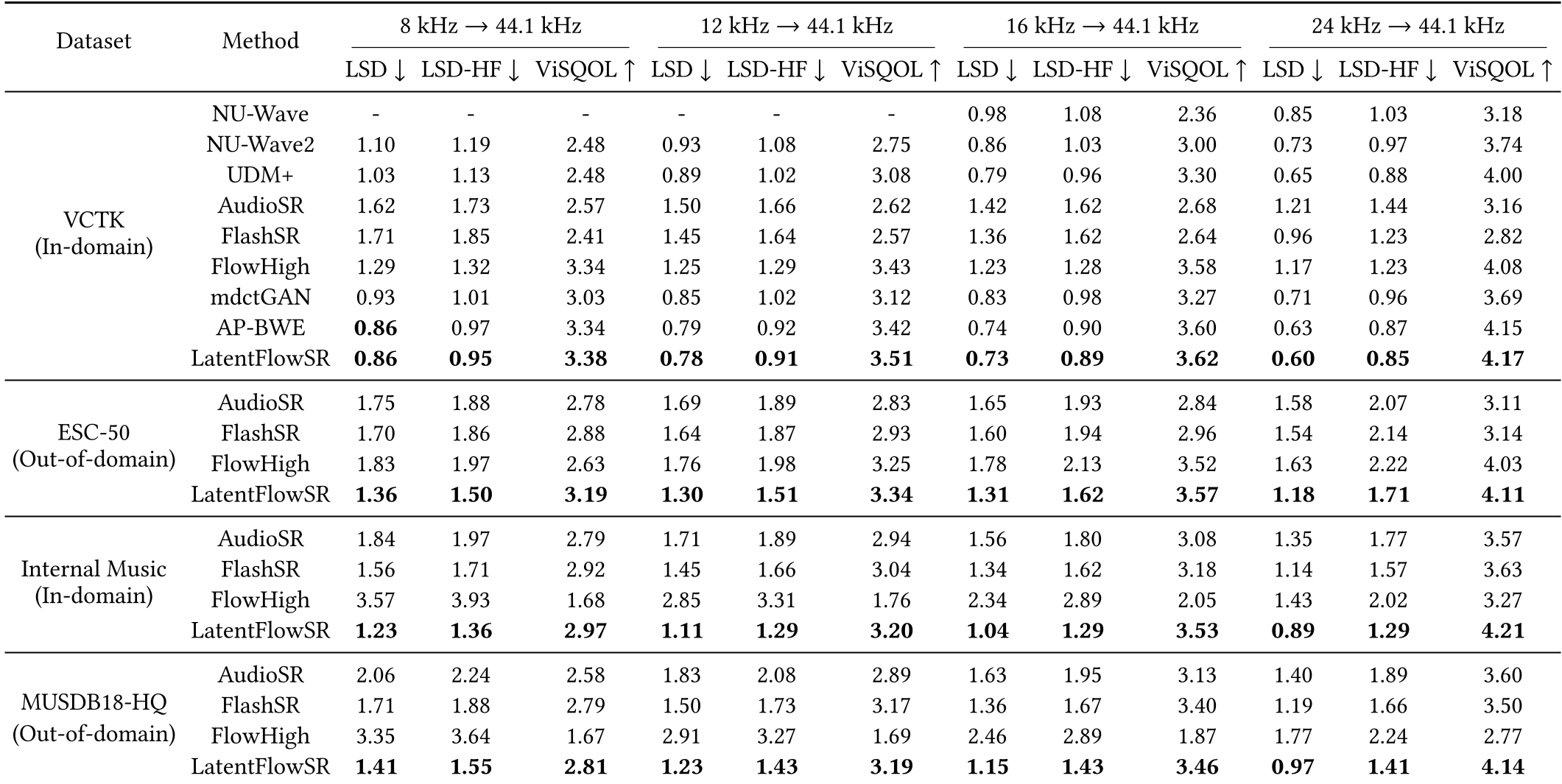 Table 1: Extensive performance comparison across audio types.
Table 1: Extensive performance comparison across audio types.
The Noise-Robustness Advantage
A critical ablation study showed that without the noise-injection strategy (NR), the ViSQOL score dropped significantly. This confirms that the "Noise-Robust" part of the NRAE is what allows the CFM to operate effectively in a one-step regime.
Critical Insight & Conclusion
LatentFlowSR proves that representation space matters more than model size. By moving from the "raw" domain to a compressed, continuous, and robust latent domain, the task of audio super-resolution becomes significantly simpler to learn.
Limitations: While the one-step inference is fast, the quality of the reconstruction is still tethered to the upper bound of the pretrained autoencoder. Future iterations could explore end-to-end refinement to push this boundary even further.
Takeaway: If you are building audio generative pipelines, stop modeling samples; start modeling noise-robust latent flows.