LagerNVS is a real-time, feed-forward neural network for Novel View Synthesis (NVS) that achieves state-of-the-art results (31.4 PSNR on RealEstate10k) without explicit 3D reconstruction. It utilizes a "highway" encoder-decoder architecture initialized with 3D-aware latent features to directly render target views at over 30 FPS on an H100 GPU.
TL;DR
LagerNVS represents a paradigm shift in Novel View Synthesis (NVS) by proving that you don't need explicit 3D reconstruction (like Gaussians or Voxels) to achieve SOTA results. By leveraging 3D-aware latent features and a high-speed "highway" transformer architecture, it delivers 512x512 renders at over 30 FPS, outperforming existing explicit methods by substantial margins (up to +1.7dB PSNR).
Background Positioning
In the landscape of 3D vision, we typically choose between Optimization-based methods (like NeRF/3DGS, which are slow) and Feed-forward methods (fast but often lower quality). Within feed-forward models, there is a sub-debate: do we need to reconstruct the scene explicitly? LagerNVS argues that we need the bias of 3D geometry but not the explicit representation itself, placing it at the frontier of high-efficiency, generalized NVS.
The Motivation: Why Bypass Reconstruction?
Explicit 3D reconstructions (like 3D Gaussian Splatting) often struggle with:
- Occlusions: Points that aren't seen aren't reconstructed, leading to "holes."
- View-dependent effects: Thin structures and mirrors are notoriously difficult to represent with static primitives.
- Complexity: Rasterizing or ray-marching explicit volumes adds latency.
The authors' key insight: Latent features can "imagine" better than explicit points. If a network is pre-trained to understand depth and geometry, its internal features (latents) already contain the necessary spatial logic. Why force those latents back into a 3D point cloud when you can decode them directly into a pixel-perfect image?
Methodology: The "Highway" to Latent Geometry
1. 3D-Aware Encoder
The core strength of LagerNVS is its 3D-aware initialization. Instead of starting from scratch or using 2D-only features (like DINOv2), the encoder is initialized from VGGT, a model trained for explicit 3D reconstruction. This ensures the latent tokens are grounded in geometric reality.
2. The Highway Architecture
Unlike "bottleneck" models that compress the scene into a fixed number of tokens, LagerNVS uses a Highway Encoder-Decoder. This allows information from any source image to flow directly to the decoder without being "choked" by a fixed-size representation.
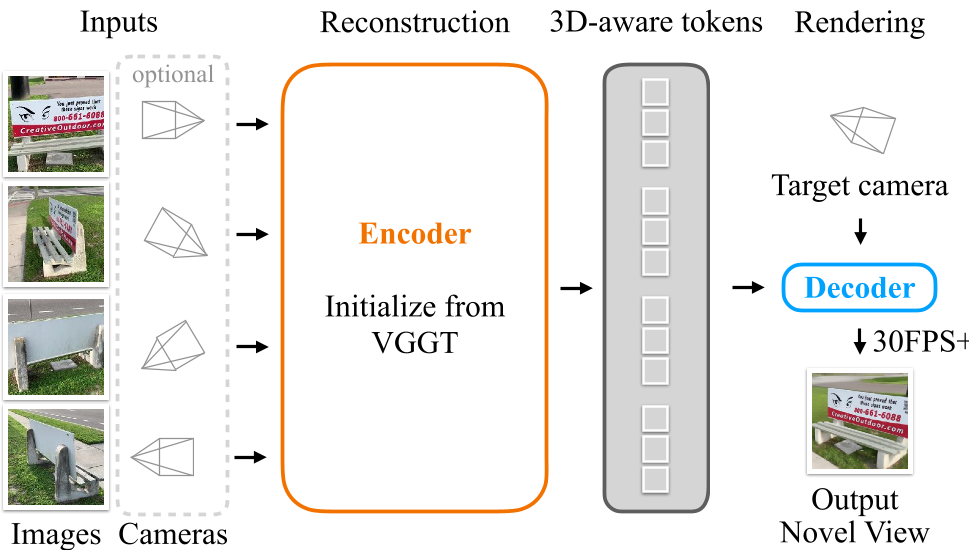 Figure: The pipeline takes multiple images, encodes them into 3D-aware tokens, and uses a lightweight transformer to query these tokens based on a target camera pose.
Figure: The pipeline takes multiple images, encodes them into 3D-aware tokens, and uses a lightweight transformer to query these tokens based on a target camera pose.
3. Bidirectional Cross-Attention
Efficient decoding is achieved through a transformer that uses target camera Plucker Ray Maps as queries. The authors use a specific bidirectional cross-attention mechanism that allows the target camera tokens and scene tokens to update each other, maintaining complexity relative to the number of source views.
Experiments: Crushing the Baselines
SOTA Performance
LagerNVS sets a new benchmark on RealEstate10k, effectively ending the reign of previous latent models like LVSM.
| Method | PSNR ↑ | SSIM ↑ | | :--- | :--- | :--- | | LVSM (Decoder-only) | 29.67 | 0.906 | | LagerNVS (Ours) | 31.39 | 0.928 |
Latent vs. Explicit
When compared to feed-forward 3DGS models (like AnySplat or DepthSplat), LagerNVS shows superior handling of reflective surfaces and thin structures—areas where point-based models typically fragment.
 Figure: LagerNVS vs. 3DGS. Notice how the latent representation maintains the integrity of thin metal rods and reflections that explicit splats lose.
Figure: LagerNVS vs. 3DGS. Notice how the latent representation maintains the integrity of thin metal rods and reflections that explicit splats lose.
Critical Analysis & Conclusion
Takeaway
The success of LagerNVS suggests that for many NVS tasks—especially those requiring speed and generalization—the community may have over-indexed on explicit geometry. Latent geometry, provided it is 3D-aware, offers a more flexible and robust "world model" for rendering.
Limitations
- Deterministic Blur: In cases of extreme extrapolation where info is missing, the model reverts to the "mean" (blur). The authors mitigate this by showing the decoder can be fine-tuned into a Diffusion Model for hallucination.
- Temporal Stability: While FPS is high, generating flicker-free video still requires the typical temporal consistency tricks not fully explored in the base deterministic version.
Future Outlook
LagerNVS paves the way for a "fully neural" viewport. By integrating a diffusion-based decoder (as shown in their preliminary experiments), we can expect future iterations to perfectly hallucinate the "back of the head" or unseen rooms with high-frequency detail.
For more details, check out the project page at szymanowiczs.github.io/lagernvs.