LeapAlign is a post-training fine-tuning framework designed to align Flow Matching (FM) models with human preferences. It introduces a "leap trajectory" that reduces the long generation process into a two-step differentiable path, enabling direct reward gradient backpropagation to early generation steps. LeapAlign achieves state-of-the-art results on benchmarks like GenEval and HPSv2.1, significantly improving image-text alignment and compositional quality for models like Flux.1.
TL;DR
LeapAlign is a novel post-training method for Flow Matching models (like Flux) that allows reward gradients to flow all the way back to the very first steps of image generation. By "leaping" through the trajectory in just two steps and using a clever gradient discounting mechanism, it solves the memory and stability issues of previous methods while significantly boosting image layout and text alignment.
Positioning: This work is a significant advancement in the Direct-Gradient family of alignment methods, moving beyond the limitations of single-step updates (ReFL) or truncated gradients (DRTune).
The Problem: The "Early Step" Paradox
In text-to-image generation, not all timesteps are created equal. Early steps (near the noise) define the global layout, object placement, and composition. Late steps (near the image) refine details and textures.
Current alignment methods face a dilemma:
- RL-based (GRPO/PPO): They can update all steps but suffer from high variance and slow convergence because they don't use the model's internal differentiability.
- Direct-Gradient: They are faster and more stable but backpropagating through 25-50 steps of a DiT (Diffusion Transformer) leads to Out-of-Memory (OOM) errors and Gradient Explosion. In practice, they only tune the last 1-2 steps, leaving the global layout untouched.
LeapAlign: Building the Shortcut
The core insight of LeapAlign is that we don't need to backpropagate through every step to reach the beginning.
1. The Leap Trajectory
Using the mathematical property of Rectified Flow, the model can predict a "latent leap" from any time $k$ to a future time $j$. LeapAlign samples a full trajectory, then picks two random points to create a two-step shortcut: $$x_k \xrightarrow{ ext{Leap 1}} \hat{x}{j|k} \xrightarrow{ ext{Connector}} x_j \xrightarrow{ ext{Leap 2}} \hat{x}{0|j} \xrightarrow{ ext{Connector}} x_0$$ This "Leap Trajectory" keeps the memory cost constant (only 2 steps) regardless of how early $x_k$ is.
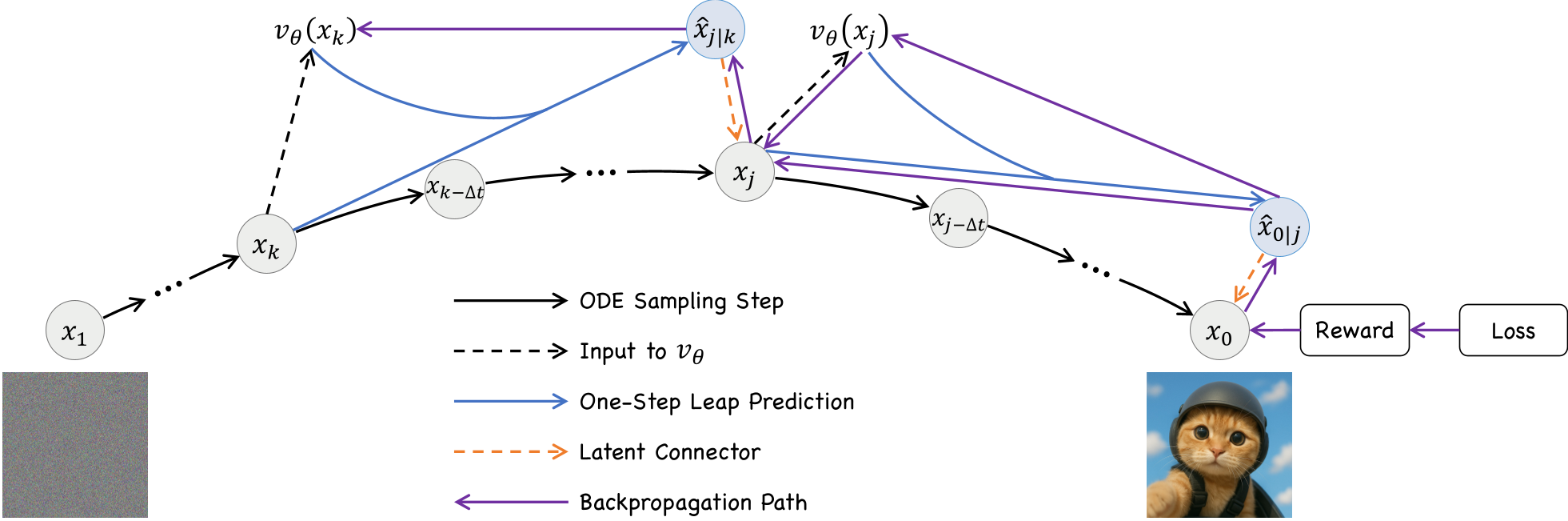
2. Gradient Discounting: Keeping the "Nested" Signal
When you backpropagate through multiple steps, you get a Nested Gradient. Previous works like DRTune simply cut this term to prevent explosion. LeapAlign argues this term is valuable for step-to-step dependency. Instead of cutting it, they apply a discounting factor $\alpha$ (e.g., 0.3): $$\frac{\partial x_0}{\partial heta} = ext{Single-Step Grads} + \alpha \cdot ext{Nested Gradient}$$ This provides a "best of both worlds": the stability of truncated gradients with the rich information of full backpropagation.
Experimental Performance
The authors tested LeapAlign on Flux.1-dev. The results on GenEval—a benchmark notorious for testing if a model actually follows complex instructions like "a red ball to the left of a blue square"—showed massive improvements.
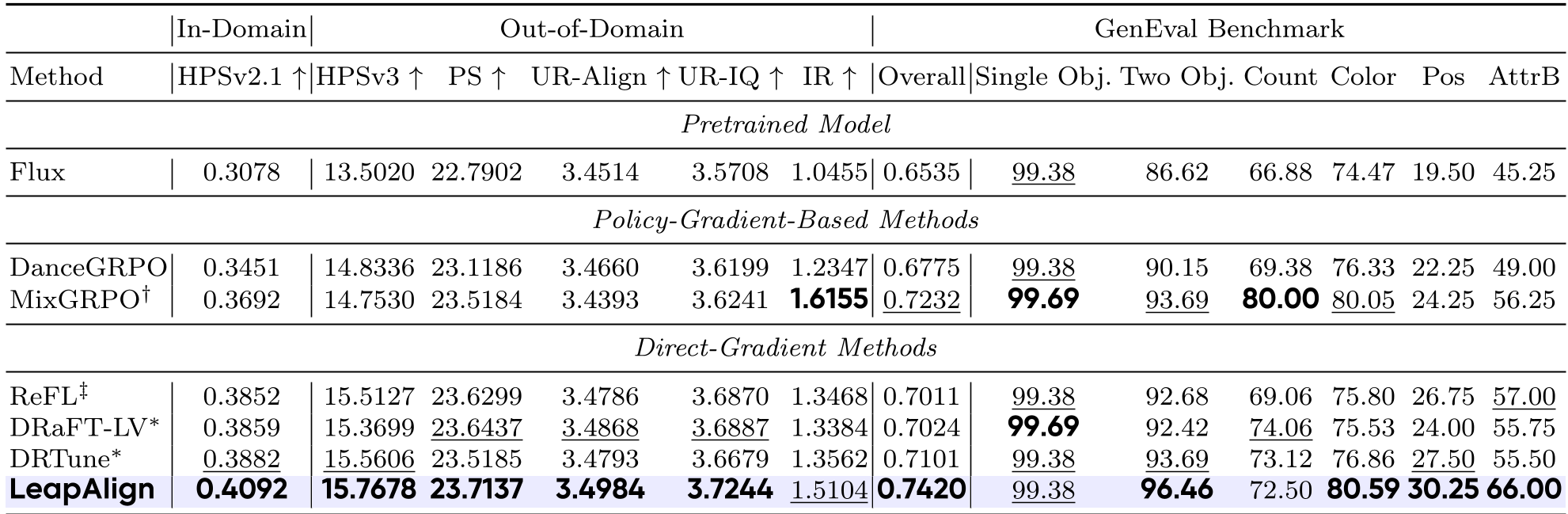
Key findings:
- Compositional Mastery: LeapAlign scored 0.7420 overall on GenEval, beating MixGRPO and DRTune.
- Visual Evidence: Qualitative samples show that while other methods keep the same layout as the base model, LeapAlign actually moves objects around to match the prompt.

Critical Insight
The success of LeapAlign hinges on the Trajectory-Similarity Weighting. Since the "leap" is an approximation, some leaps are "wilder" than others. By down-weighting leaps that deviate too much from the actual ODE path, the model avoids learning from noisy, non-physical gradients. This ensures that the two-step approximation remains a valid proxy for the multi-step reality.
Conclusion & Future Work
LeapAlign effectively bridges the gap between the efficiency of direct-gradient methods and the flexibility of RL-based methods. By making early-step fine-tuning practical, it opens the door for much more controllable and instruction-aligned generative models. The next frontier? Applying this "Leap" logic to Video Generation, where the temporal dimension makes long-trajectory backpropagation even more impossible.
Key Takeaway: Don't discard gradients just because they explode; discount them, and build shorter paths to the information you need.