The paper proposes Hierarchical Causal Dropout (HCD), a novel Out-of-Distribution (OOD) generalization framework that uses channel-level sparsification and information-theoretic constraints to decouple causal features from spurious domain biases, achieving SOTA performance on benchmarks like Camelyon17 and iWildCam.
TL;DR
Deep learning models are notorious for "cheating" by picking up background cues instead of actual objects. Hierarchical Causal Dropout (HCD) introduces a surgical approach to this problem: instead of just augmenting data, it uses a learnable gating mechanism to physically block non-causal information flow at the channel level, guided by matrix-based mutual information and variance-covariance regularization.
Background: The Entanglement Trap
In the wild, distribution shifts (changes in lighting, sensor types, or backgrounds) cause models to collapse. The root cause is Shortcut Learning: the model finds a correlation between a specific "style" (e.g., a hospital's specific camera sensor) and the "label" (e.g., tumor presence).
Prior works tried pixel-level masking or data augmentation, but these methods are often too "blunt"—they don't account for how domain biases are encoded across high-dimensional feature channels. HCD shifts the focus from where the model looks to what the model represents.
Methodology: Representation-Level Intervention
The HCD framework operates on three critical pillars:
1. Channel-Level Sparsification
The authors argue that causal and spurious factors are entangled across channels. They introduce an Adaptive Feature Gater that generates a channel-wise mask. By forcing features through a bottleneck and applying an $L1$ sparsity penalty, the model is forced to discard redundant, noise-carrying channels and keep only the most robust semantic pathways.
2. Information-Theoretic Decoupling (Matrix MI)
To ensure the remaining channels are truly domain-invariant, HCD minimizes the Matrix-based Mutual Information (MMI) between the features and the domain labels. Unlike standard MI estimation which is computationally expensive, HCD uses the spectral properties of kernel matrices (Von Neumann entropy) to "bleach" domain-specific signatures from the latent manifold.
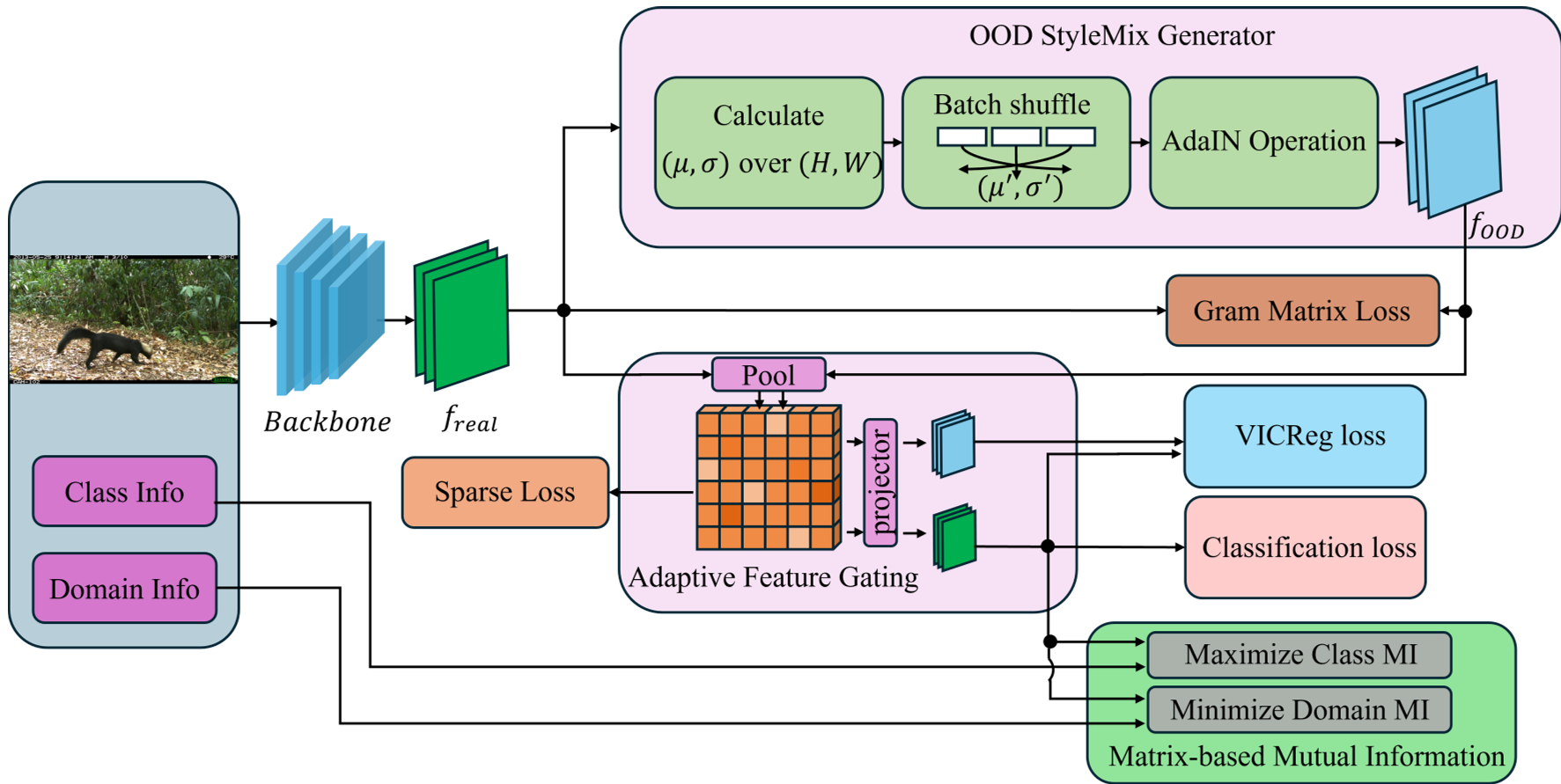 Fig 1. The HCD framework overview: integrating gating, StyleMix, and Information Bottleneck.
Fig 1. The HCD framework overview: integrating gating, StyleMix, and Information Bottleneck.
3. StyleMix-driven VICReg
To prevent the gater from accidentally filtering out too much information, HCD uses StyleMix to synthesize "counterfactual" domains in the latent space (swapping feature statistics). These are then regularized using VICReg, ensuring that even under extreme stylistic changes, the invariant semantic core remains stable.
Experimental Mastery
HCD was tested on two heavy-duty benchmarks: Camelyon17 (Pathology) and iWildCam (Wildlife Monitoring).
Quantitative Results
The performance leap is significant. On Camelyon17, HCD reached 86.62% accuracy, crushing traditional IRM (75.68%) and ERM baselines. In the long-tailed iWildCam dataset, it avoided the typical "performance collapse" seen in rare classes, proving that sparse channel filtering is gentler and more effective than aggressive spatial augmentation.
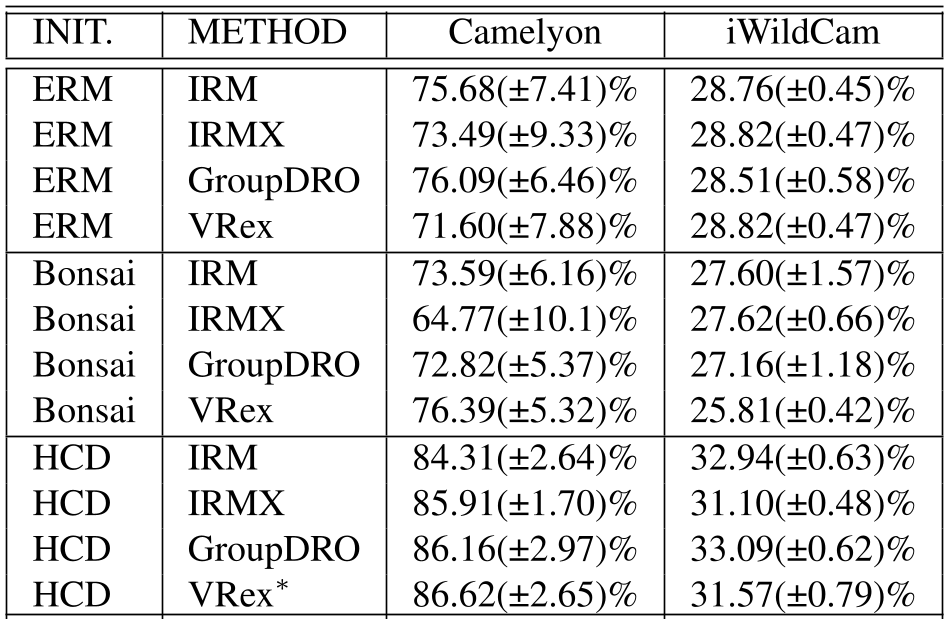 Performance Comparison: HCD consistently outperforms existing SOTA methods across diverse domains.
Performance Comparison: HCD consistently outperforms existing SOTA methods across diverse domains.
Visual Evidence: Locking onto the "Causal" Core
Grad-CAM visualizations (Fig 2) show HCD's clinical precision. While standard models get distracted by nocturnal noise or heavy foliage, HCD stays locked on the animal's silhouette.
 Fig 2. Grad-CAM comparison: HCD (left) ignores environmental artifacts that mislead ERM (right).
Fig 2. Grad-CAM comparison: HCD (left) ignores environmental artifacts that mislead ERM (right).
Critical Insight: The Geometry of Generalization
Beyond accuracy, the authors analyzed the Loss Landscape (Fig 3). HCD produces a much flatter and smoother optimization basin compared to other methods. In deep learning theory, a flat minimum indicates a solution that is less sensitive to perturbations—explaining why HCD generalizes so well to unseen sites and equipment.
 Fig 3. Visualization of Loss Landscapes showing the stability advantage of HCD.
Fig 3. Visualization of Loss Landscapes showing the stability advantage of HCD.
Conclusion & Future Outlook
HCD proves that structural surgery at the representation level is more powerful than external data manipulation. By combining sparsity with information theory, it provides a principled way to ignore "noise" while preserving "saliency."
Limitations: The matrix-based MI calculation has a $O(N^2)$ complexity relative to batch size. Future research into low-rank spectral entropy approximations will be key to scaling this to foundation-model-sized datasets.