The paper introduces AutoTune, a theoretical framework for language model reasoning that uses autocurriculum (adaptive data selection) to train Chain-of-Thought (CoT) models. It demonstrates that by focusing training on prompts where the model currently fails, one can achieve SOTA reasoning accuracy with exponentially fewer teacher demonstrations in Supervised Fine-Tuning (SFT) and significantly reduced compute in Reinforcement Learning (RL).
TL;DR
Training reasoning models like DeepSeek-R1 or OpenAI’s o1 normally requires an ocean of compute and expert data. This paper provides a mathematical proof that most of that effort is wasted. By using an autocurriculum—where the model uses a simple "answer checker" to decide which problems are worth practicing—we can reduce the need for expert demonstrations exponentially.
The Bottom Line: We don't need more data; we need more relevant data.
The "Waste" in Modern Training
In standard Supervised Fine-Tuning (SFT), we feed the model thousands of Chain-of-Thought (CoT) examples. However, if the model already knows how to solve 80% of those problems, the compute spent on those expert traces is essentially zero-value.
In Reinforcement Learning (RL), the situation is worse. If a model has a 1% chance of solving a hard problem, you have to sample 100 traces just to find one correct one to learn from. As you aim for higher accuracy, this "rejection sampling" cost explodes.
The Insight: Boosting the Reasoning Frontier
The authors draw on a classical idea from 1990s machine learning: Boosting. Instead of training on a static dataset, the algorithm (AutoTune) evolves through "phases."
- Test: Use a cheap verifier (e.g., a unit test for code) to see where the model fails.
- Filter: Only collect expensive expert CoT traces (SFT) or spend heavy sampling compute (RL) on those specific failure points.
- Update: Add the new knowledge to the "ensemble," shifting the frontier of what the model finds "easy."
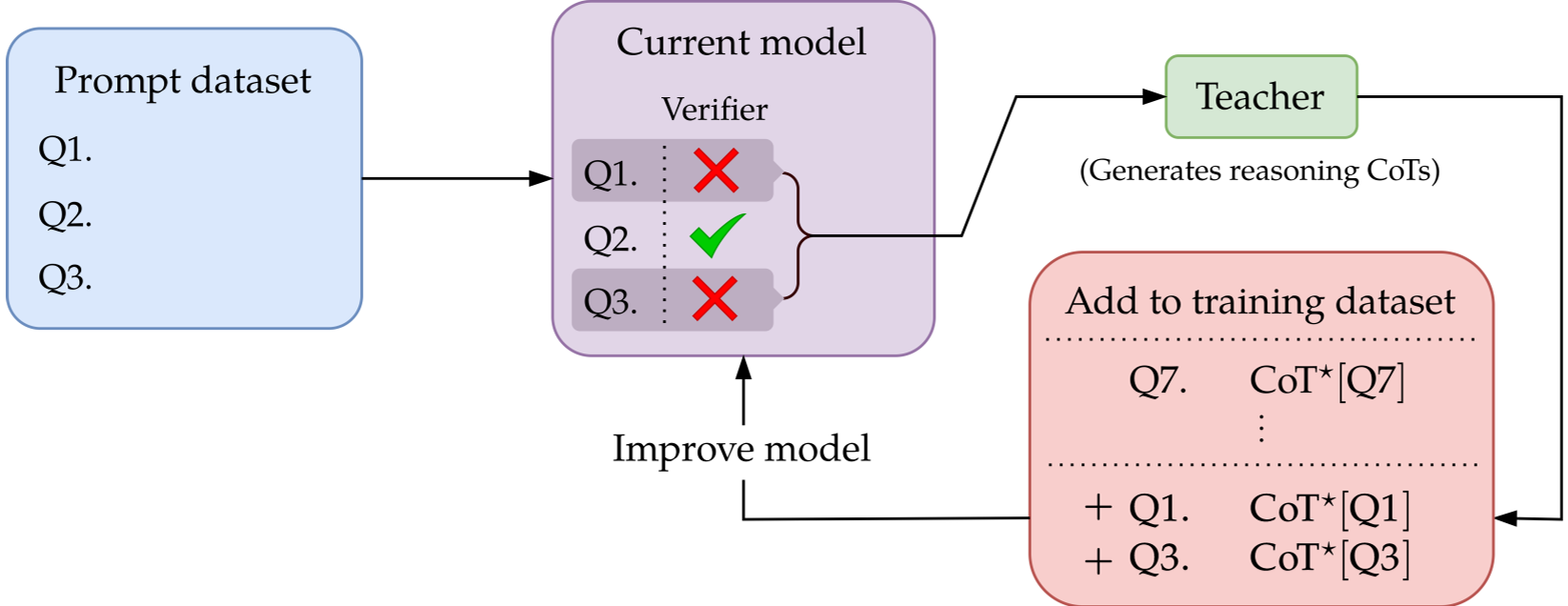
Methodology: The Math of Efficiency
The paper formalizes the complexity using the Natarajan Dimension (), a measure of the model's capacity.
1. SFT: From Linear to Logarithmic
In standard SFT, to get an error of , you need samples. If you want 99.9% accuracy, you need 1000x more data than for 90%. AutoTune changes this to a logarithmic relationship. The cost becomes nearly independent of how much accuracy you want—a massive win for "frontier" models.
2. RL: Decoupling Coverage
The "Coverage" () refers to how likely the initial model is to stumble upon the right answer. Usually, the cost is . AutoTune effectively turns into a "one-time registration fee" (burn-in cost). Once you pay it to get the model started, increasing the accuracy from 90% to 99% doesn't require scaling that cost further.

Visualizing the Shift
The algorithm's magic happens in the reweighting function. By tracking the "rank" of a prompt (how many models in the ensemble get it right), the system creates a probability "mask" that emphasizes the unknown.
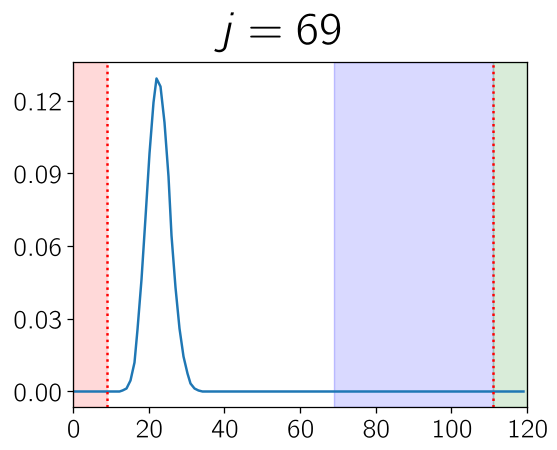 In the figure above, the algorithm shifts its focus from the "green" (known) zones to the "red/blue" (unknown) zones, ensuring maximum information gain per training step.
In the figure above, the algorithm shifts its focus from the "green" (known) zones to the "red/blue" (unknown) zones, ensuring maximum information gain per training step.
Why This Matters for the Industry
This isn't just theory—it explains why methods like ReST and DeepSeek-R1's distillation work so well. It suggests that the future of AI training isn't just "scaling laws" (throwing more GPUs at the problem), but algorithmic data routing.
Limitations
- Verifier Dependency: You need a way to check the answer (Math/Code). For "creative writing," this is much harder.
- Batch vs. Online: The current proof works for "batch" updates; real-world PPO is more fluid.
Conclusion
The paper provably demonstrates that "Autocurriculum" is as close to a formal "free lunch" as we get in LLM training. By letting models decide what to study, we can forge reasoning capabilities with a fraction of the traditional data and compute budget.
Next Step: The authors hint at Part II, where they will show how autocurriculum can help models learn to solve problems they never saw a correct answer for during the initial phase. Stay tuned.