The paper introduces Learning to Self-Evolve (LSE), an RL framework that trains LLMs to iteratively refine their own prompts/contexts based on test-time performance feedback. Using a 4B-parameter model with tree-guided evolution, LSE achieves SOTA results on BIRD (Text-to-SQL) and MMLU-Redux (QA), outperforming frontier models like GPT-5 and Claude 4.5.
TL;DR
Current LLMs are "frozen in time" during deployment—they don't learn from the mistakes they made five minutes ago. Learning to Self-Evolve (LSE) changes this by training a 4B-parameter model to become a professional "prompt engineer" for itself. By treating self-improvement as a reinforcement learning (RL) task and using tree-search to navigate prompt versions, LSE allows a small model to outperform GPT-5 and Claude Sonnet 4.5 in complex domains like Text-to-SQL.
The Problem: The "Static Deployment" Trap
Most AI researchers treat models as static artifacts. Once training is over, the weights are locked. If a model encounters a specific database schema in a Text-to-SQL task, it applies the same generic strategy every time, even if it has just seen ten failures that suggest a better approach.
Existing solutions like TextGrad or GEPA use "on-the-fly" prompt optimization, but they rely on the model's inherent reasoning. The authors of LSE argue that self-evolution is a distinct reasoning challenge that requires its own optimization. The model needs to perform credit assignment (which part of my prompt failed?) and anticipation (how will a change affect the next batch?).
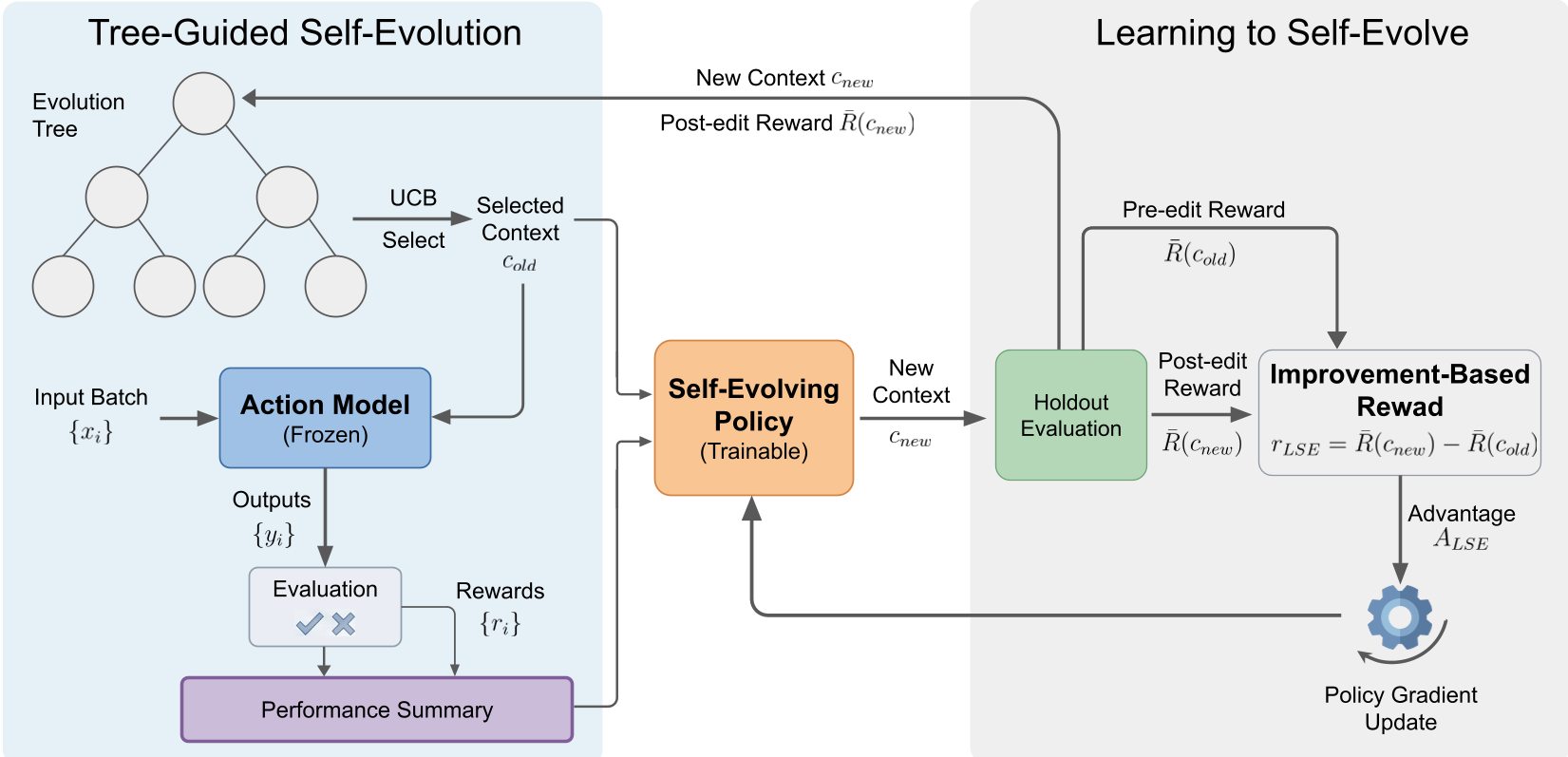
Methodology: Evolution as an RL Skill
The LSE framework reframes prompt editing as a Contextual Bandit problem.
1. The Improvement-Based Reward
The core innovation is the reward function. Standard RL might reward a model based on its final accuracy (Post-edit score). However, if a model starts at 90% accuracy and stays there, is it a better "evolver" than a model that takes a 20% accuracy task and moves it to 60%? LSE uses a Delta-Reward: This forces the model to learn the process of improvement rather than simply memorizing high-performing prompts.
2. Tree-Guided Evolution
Linear "chains" of prompt edits are fragile—one bad edit can ruin the performance of all subsequent steps. LSE replaces this with an evolution tree using the Upper Confidence Bound (UCB) algorithm. This allows the system to:
- Explore: Try a radical new instruction style.
- Exploit: Refine a prompt that is already showing promise.
- Backtrack: If an edit causes a performance collapse, return to a previous high-performing "ancestor" node.
Experiments: Small Model, Big Impact
The researchers used a Qwen3-4B-Instruct model as the base. Despite its small size, once trained with LSE, it became a superior optimizer compared to the world's most powerful closed-source models.
Key Results:
- BIRD (Text-to-SQL): LSE (67.3%) vs. GPT-5 (65.2%).
- MMLU-Redux (QA): LSE matched GPT-5 and beat specialized optimizers like TextGrad.
- Generalization: An LSE policy trained on Qwen worked perfectly to guide an Arctic-7B model, proving it had learned a "meta-skill" of instruction optimization that isn't tied to a specific set of weights.
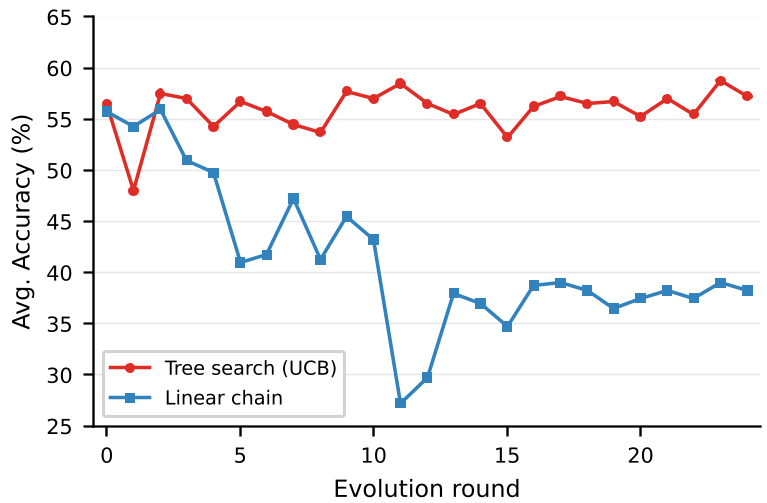 Figure: Comparison showing how UCB tree search (Blue) maintains performance stability compared to the linear chain (Orange), which often collapses after a single bad edit.
Figure: Comparison showing how UCB tree search (Blue) maintains performance stability compared to the linear chain (Orange), which often collapses after a single bad edit.
Critical Analysis: Why This Matters
LSE proves that system-level intelligence (how a model manages its context) is just as important as parameter-level intelligence (what is inside the weights).
The Limitation: Currently, LSE delegating exploration entirely to tree search at test time. Future work could involve training models to manage the tree search itself—deciding when to branch and when to prune.
The Future: We are moving toward "living" models. Imagine a coding assistant that doesn't just know Python but evolves its "personal manual" for your specific private codebase the more you use it. LSE provides the RL foundation to make that possible.
Conclusion
LSE demonstrates that even 4B-parameter models can act as world-class architects of their own reasoning environments. By training for improvement rather than static correctness, we can unlock a level of test-time adaptation that was previously reserved for human experts.