本文提出了 VLA-World,一种统一的视觉-语言-动作(VLA)世界模型。通过将预测性想象(Predictive Imagination)与反思性推理(Reflective Reasoning)结合,该模型在 nuScenes 自动驾驶任务中实现了 SOTA 性能,显著提升了规划的安全性和轨迹精度。
TL;DR
上海交通大学与华为中央研究院联合推出的 VLA-World,打破了单纯端到端控制(VLA)与环境模拟(World Model)的界限。它不仅能“预见”未来 0.5 秒的画面,还能对着自己生成的画面进行“反思”,判断之前的驾驶决策是否安全。这种**“生成式推理”**机制让模型在 nuScenes 榜单上刷出了 0.12% 的极低碰撞率。
1. 痛点:会模仿但不会“思考”的驾驶 AI
目前的自动驾驶大模型(VLA)通常直接将图像映射到动作。这种方式虽然简单,但存在致命伤:
- 缺乏时空一致性:它们只关注当前帧,很难理解周围车辆复杂的动作趋势。
- 缺乏自省能力:模型不知道如果我真的这么开,0.5 秒后会发生什么。
而传统的世界模型(World Model)虽然能生成漂亮的未来视频,却往往是“没脑子”的模拟器——它能画出撞车的画面,却无法从画面中提炼出“不要撞车”的指令。
2. 核心架构:模拟器与推理器的深度融合
VLA-World 的核心直觉源自人类驾驶:看到行人突然横穿,脑中会瞬间闪过一个“继续开会撞上”的画面,从而立刻修正指令踩下刹车。
2.1 任务流程(Pipeline)
- 感知与初步预测:识别环境后,先生成一个初步的、直觉式的 0.5s 轨迹。
- 动作引导生成(Conditioned Generation):将这个初步轨迹作为条件,让模型生成对应的未来帧图像。
- 反思性推理(Reflective Reasoning):模型在
<think>标签内对这张自生成的图进行语义分析,寻找视觉冲突(如遮挡、突然出现的障碍物)。 - 修正决策:基于反思结果,输出最终的动作指令和 3s 长程轨迹。
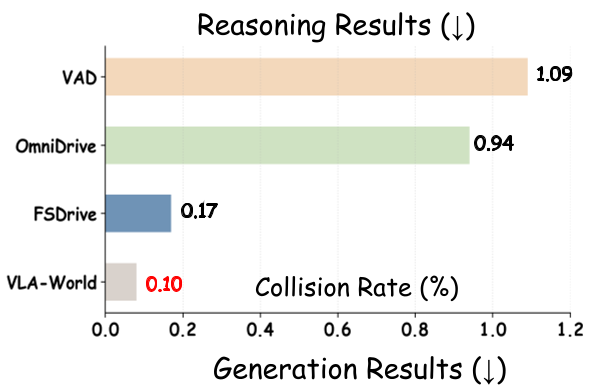 图 1:VLA-World 的三阶段学习范式:生成激活、概念微调、强化学习。
图 1:VLA-World 的三阶段学习范式:生成激活、概念微调、强化学习。
3. 训练黑科技:三阶段进化与 GRPO 优化
为了实现这种复杂的因果推理,作者设计了精妙的训练策略:
- 阶段一:视觉预训练:在大规模驾驶数据集上训练模型的未来帧生成能力,对齐多视觉 Token。
- 阶段二:指令微调(SFT):通过精心设计的
nuScenes-GR-20K数据集,教会模型按照“感知-预测-生成-思考-行动”的链条(Chain-of-Thought)说话。 - 阶段三:强化学习(RL):引入 GRPO (Group Relative Policy Optimization)。该方法不需要复杂的鉴别器(Critic),而是通过一组规则驱动的奖励函数(如碰撞惩罚、生成质量奖励、运动学一致性)来让模型在多种驾驶路径中自我演进。
4. 实验战绩:精度与生成的一箭双雕
实验结果令人惊艳:
- 规划精度:在 ST-P3 指标下,VLA-World 的平均 L2 误差仅为 0.30m,显著优于 FSDrive 和 UniAD。
- 视觉保真度:其生成的未来帧不仅逻辑自洽,质量(FID=9.8)甚至超越了一些专门做扩散生成的视频模型。
 图 2:与 FSDrive 对比,VLA-World 生成的未来画面更清晰,轨迹预测(下方蓝色 vs 红色)与 Ground Truth 契合度更高。
图 2:与 FSDrive 对比,VLA-World 生成的未来画面更清晰,轨迹预测(下方蓝色 vs 红色)与 Ground Truth 契合度更高。
5. 深度洞察:为什么 VLA-World 有效?
理论上的 ELBO 解释: 作者通过数学推导指出,传统 VLA 实际上是在对未来环境 进行边际化处理(即忽略它),这会导致策略估计的下限(ELBO)极松。而 VLA-World 显式地建模了 联合分布。通过把“未来”生出来,模型实际上在缩小决策的不确定性搜索空间。
此外,消融实验显示,如果去掉“推理(Reasoning)”模块,模型的规划误差会陡增 20% 以上,这实锤了**“反思”对于安全驾驶的不可替代性**。
6. 总结与展望
VLA-World 标志着自动驾驶从“简单的动作模仿”转向“具有先验模拟能力的决策系统”。
- 局限性:生成 Token 的过程计算开销较大,且目前主要依赖 2D 图像生成,未来若结合 3D Occupancy 可能更稳健。
- 启示:未来的端到端模型,不仅要会“开”,还要学会“做梦”并从“梦境”中吸取教训。
关键词:Vision-Language-Action, World Models, GRPO, Autonomous Driving, CVPR 2025.