RLA-WM is a visual feature-based world model that predicts future states in the DINO token space using a novel representation called Residual Latent Action (RLA) and Flow Matching. It achieves SOTA performance in 3D robot manipulation tasks, significantly outperforming video diffusion models like Vid2World in prefix-conditioned rollout accuracy while being orders of magnitude faster.
TL;DR
Researchers have developed RLA-WM, a world model that predicts the "future" not in pixels, but in a compressed semantic feature space (DINO). By introducing Residual Latent Actions (RLA)—a compact way to encode the change between frames—and using Flow Matching, they've created a model that is faster than video diffusion models while being far more accurate for complex robot manipulation.
Context: The Hallucination and Efficiency Trade-off
Most modern world models (like Gen-2 or Sora-style architectures applied to robotics) attempt to imagine the future frame-by-frame in pixel space. While visually stunning, these models are computationally ruinous and suffer from "hallucinations"—where the robot's arm might disappear or the object might morph into something else.
Conversely, feature-based models (predicting DINO tokens) are fast but historically "blurry." They often use simple regression, which averages out all possible futures into a single grayish blob. RLA-WM solves this by realizing that the manifold of physical movement is much lower-dimensional than the raw visual data.
Methodology: The Power of the Residual
The core innovation is Residual Latent Action (RLA). Instead of trying to generate a 1-million-dimension DINO feature set from scratch, the model learns to encode the difference between the current state () and the future state ().
1. RLA Autoencoder
The model uses an encoder-decoder structure to squash the DINO residual into a compact latent vector .
- Physical Intuition: represents the "delta" or the "intent" of the transition.
- Temporal Topology: Interestingly, the authors found that linear interpolation in the RLA space () actually corresponds to smooth physical movement in time, even though the model wasn't explicitly trained with a temporal loss.
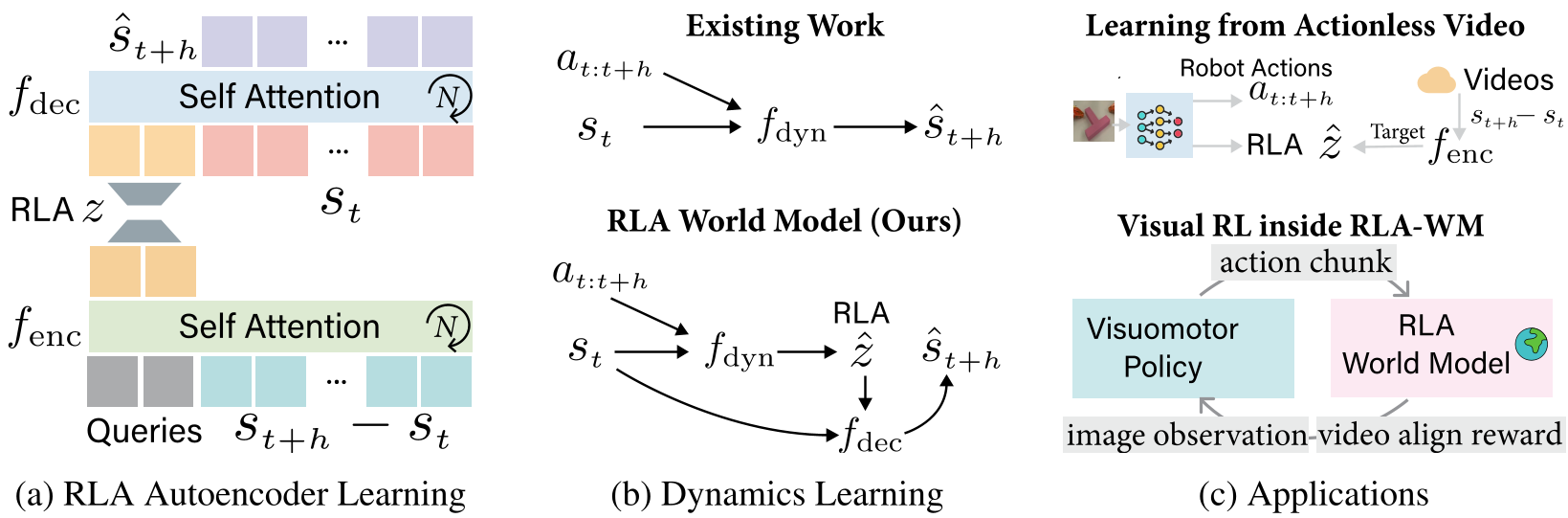
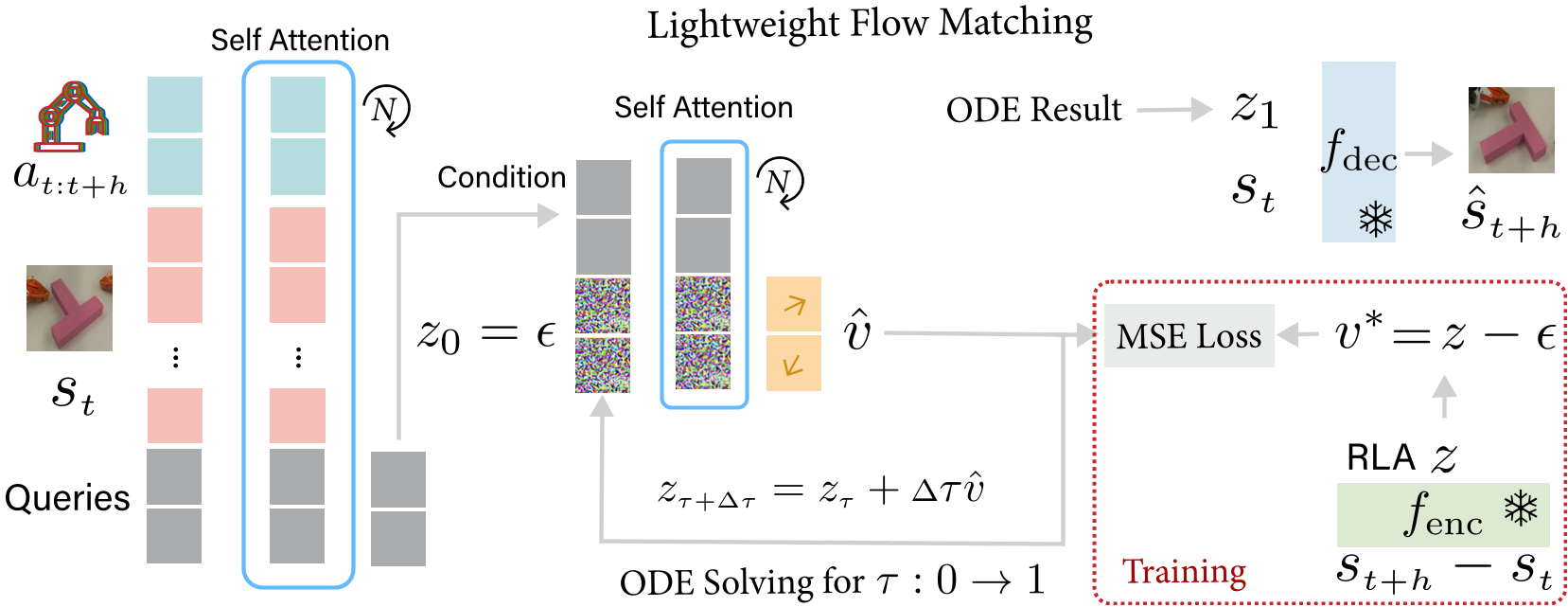
2. Flow Matching in Latent Space
Rather than traditional Diffusion, which can be slow and unstable, RLA-WM uses Flow Matching. It treats the transition from Gaussian noise to the correct RLA as a continuous ODE (Ordinary Differential Equation). Because this math happens in the compact RLA space (dimension 2048) rather than the pixel space, it is incredibly efficient.
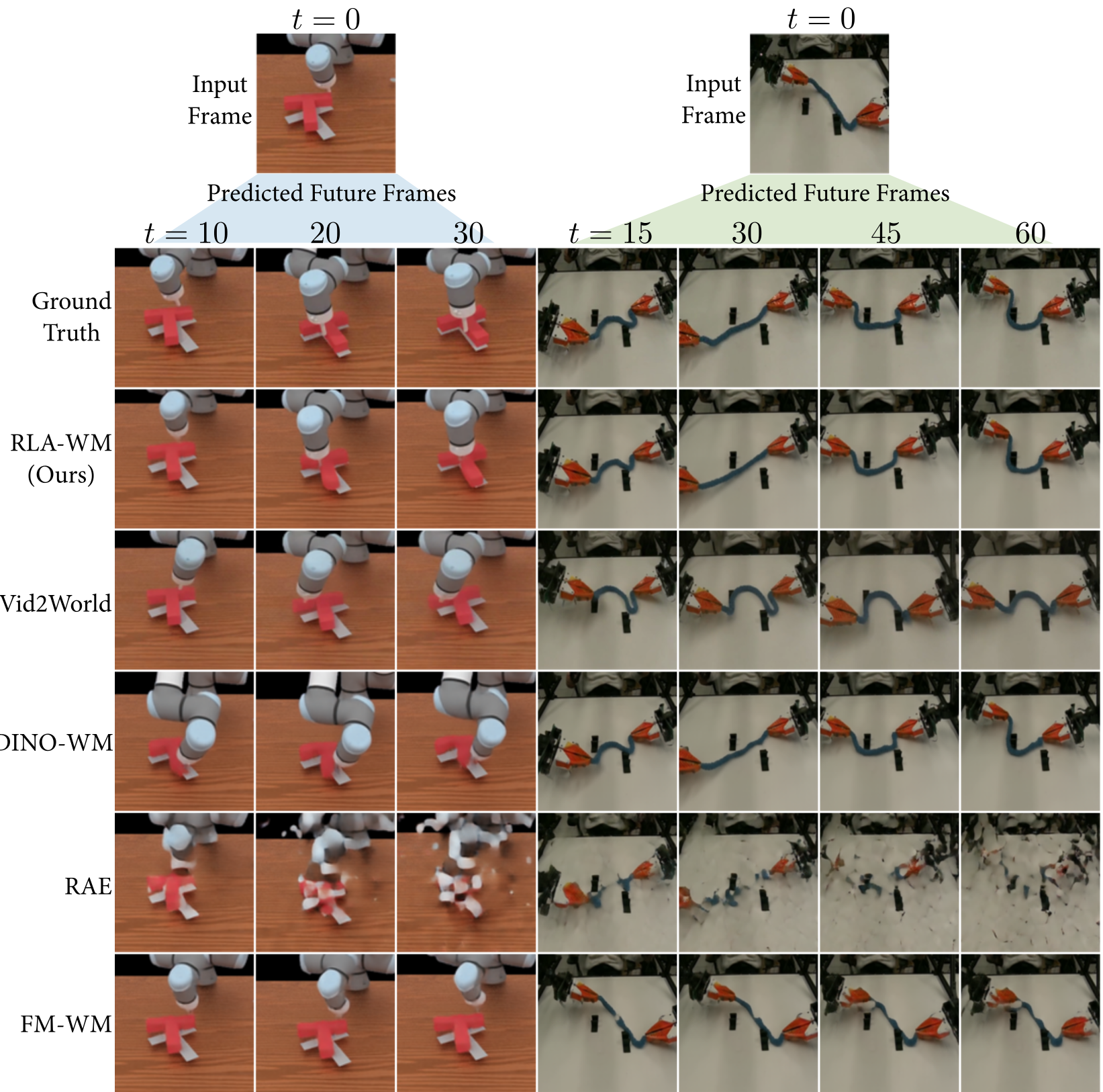
Experimental Mastery: Faster and Better
The benchmarks on ManiSkill (simulation) and IWS (real-world ALOHA robot) show a clear victory for RLA-WM.
- Fidelity: On the Push-T task, RLA-WM maintains sharp object boundaries where DINO-WM blurs out.
- Consistency: Unlike Vid2World (a diffusion baseline), RLA-WM's predictions don't diverge from physical reality over long horizons.
- Efficiency: RLA-WM uses 3.5 TeraFLOPs, compared to the 1.1 PetaFLOPs required by high-end video diffusion models. That's a massive reduction in the cost of "imagination."
Downstream Impact: "World Model-Based RL"
Perhaps the most exciting result is WMRL. The authors trained a Reinforcement Learning policy entirely inside the world model.
- The robot "imagines" a rollout using RLA-WM.
- It receives a Video Aligned Reward (VAR) based on how closely its imagined state matches an offline demonstration's DINO tokens.
- It updates its policy via PPO without ever touching a simulator or the real world during the RL phase.
This bridges the "Neural-to-Sim" gap, allowing for free policy optimization that actually transfers back to reality.
Critical Analysis & Conclusion
Takeaway
RLA-WM proves that generative modeling in feature space is the "Goldilocks" zone for robotics: it's more semantically grounded than pixels and more expressive than simple regression.
Limitations
- Dynamic Backgrounds: The model might struggle if the camera itself is moving (eye-in-hand), as the RLA would then have to encode the entire scene's shift, not just the robot's action.
- Partial Observability: Since it works on frame pairs, long-term occlusions (objects disappearing and reappearing) remain a challenge.
In conclusion, by focusing on Residuals and Flow Matching on features, RLA-WM provides a practical blueprint for the next generation of "thinking" robots that can simulate their own futures with both speed and precision.