The paper introduces a two-stage RL-based framework to equip Large Audio-Language Models (LALMs) with "timestamp-grounded reasoning." By combining Supervised Timestamp Alignment (STA) with Group Relative Policy Optimization (GRPO), the authors achieve State-of-the-Art (SOTA) performance across speech benchmarks like MMAU and AIR-Bench, ensuring Chain-of-Thought (CoT) outputs are anchored to specific audio segments.
TL;DR
Large Audio-Language Models (LALMs) are great at talking, but are they actually listening? This paper argues they aren't. By introducing Timestamp-Grounded Speech Reasoning, researchers from Mila and Université Laval have developed a framework that forces models to anchor every reasoning step to specific time-stamps in the audio. The result? A massive leap in interpretability and SOTA performance across major speech benchmarks.
The "Linguistic Prior" Trap: Why LLMs Hallucinate Audio
Most current LALMs (like Qwen-Audio or Audio Flamingo) behave like students who try to answer a listening comprehension test by only reading the questions. They rely on textual bias—predicting what a "likely" answer sounds like based on the prompt rather than the audio.
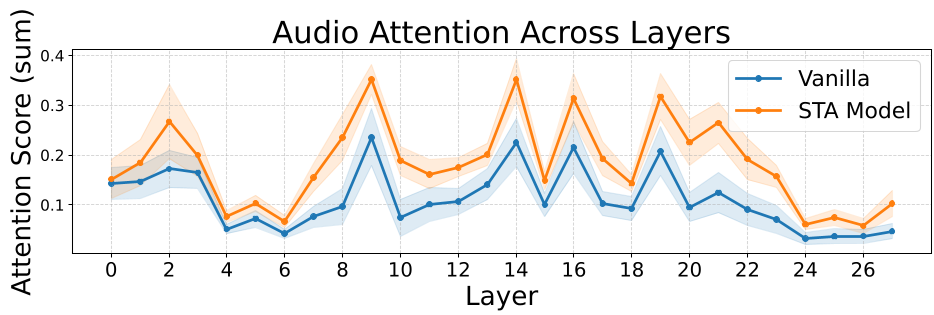
The authors prove this via a semantic attention analysis. As seen in the figure below, baseline models allocate an alarmingly small fraction of attention to audio tokens, with "system tokens" acting as attention sinks that dominate the processing.
Methodology: The Two-Stage "Ear Training"
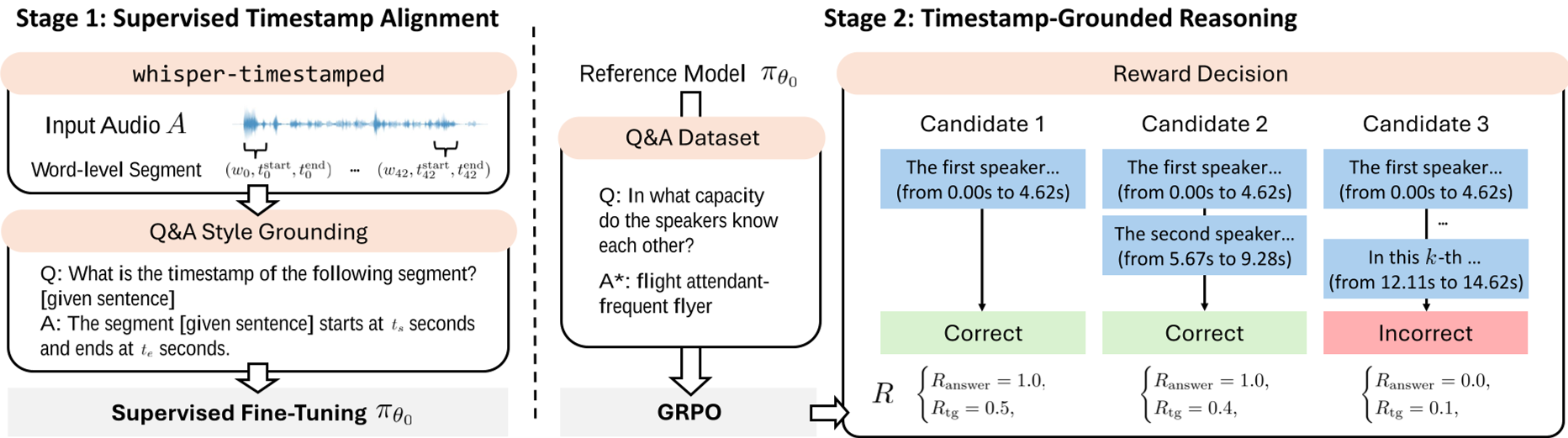
To fix this, the authors propose a two-stage training pipeline designed to make the model "hear" before it "thinks."
Stage 1: Supervised Timestamp Alignment (STA)
The goal here is simple: teach the model where things are. Using a large corpus of timestamp-annotated speech (LibriSpeech, CoVoST 2, etc.), the model learns to map specific phrases to start/end times (). This builds a "temporal primitive" capability.
Stage 2: GRPO-based Grounded Reasoning
Instead of standard fine-tuning, the authors use Group Relative Policy Optimization (GRPO). They introduce a reward function that balances two things:
- Accuracy (): Did you get the right answer?
- Grounding (): Did your reasoning actually reference the correct audio segments?
This encourages the model to generate a Chain-of-Grounded-Thought, where it must cite its evidence (e.g., "Between 2.5s and 4.0s, the speaker's tone changes...") before concluding.
Experimental Battleground: SOTA Achievements
The results are striking. On benchmarks like AIR-Bench and MELD, the proposed model (built on Qwen2.5-Omni) consistently outperforms both open-source and proprietary giants like GPT-4o Audio in specific reasoning categories.
| Method | MMAU-mini (%) | AIR-Bench SIC (%) | MELD (%) | | :--- | :--- | :--- | :--- | | GPT-4o Audio | 66.67 | 89.3 | 62.5 | | Audio-Thinker | 73.37 | - | - | | Ours (7B) | 74.47 | 89.3 | 64.6 |
Crucially, the "Ablation Study" shows that neither STA nor Reasoning SFT alone is enough. The magic happens when they are combined through RL, forcing the model to verify its reasoning against the acoustic data.

Deep Insight: Grounding is Listening
The paper's most profound finding is that explicit grounding actually changes the model's internal physics. When forced to provide timestamps, the model's cross-attention to audio tokens increases significantly. Certain layers act as "picking points" where acoustic evidence is selectively amplified to support the text output. This suggests that grounding isn't just a "feature"—it’s a prerequisite for faithful multimodal intelligence.
Conclusion & Future Outlook
While this work focuses on speech, the blueprint is clear: Multimodal models must be held accountable for their perceptual evidence.
Future Work:
- Expanding this to environmental sounds (e.g., grounding the sound of a "barking dog").
- Implementing "dense" rewards where the model is penalized during the middle of a reasoning chain if it hallucinates a timestamp.
This research marks a significant step toward making AI "listen" to the world as intently as it "speaks" about it.