本文推出了 LiteResearcher,一个专为深度研究(Deep Research)智能体设计的可扩展强化学习(RL)训练框架。通过构建模拟真实互联网动态的“轻量虚拟世界”并配合课程强化学习,仅 4B 规模的 LiteResearcher 模型在 GAIA (71.3%) 和 Xbench (78.0%) 等基准测试中达到了开源最强水平,甚至超越了 Claude-4.5 Sonnet 等大规模商业模型。
1. 核心速览
TL;DR:LiteResearcher 是一套让智能体训练真正“跑起来”的框架。它不依赖昂贵且缓慢的真实互联网搜索,而是自建了一个包含 3200 万网页的本地“虚拟世界”。通过在这个隔离、稳定且极速的环境中进行难度感知课程强化学习,区区 4B 参数的模型便在深度研究任务上“越级”击败了 Claude-4.5 Sonnet 等一众巨头。
背景定位:这是 Agentic RL 领域的一个重要坐标。它证明了制约智能体进化的核心不是模型规模,而是环境的确定性与数据流的可扩展性。
2. 动机与痛点:为什么 Agent 很难像 R1 一样通过 RL 进化?
DeepSeek-R1 的成功证明了强化学习能让推理能力涌现。但在“深度研究”领域,智能体需要调用搜索、浏览等工具,面临以下死结:
- 环境噪声:真实互联网瞬息万变,同样的 Query 两次搜索结果可能不同,导致奖励信号(Reward)极其不稳定。
- 成本瓶颈:进行一次成规模的 RL 训练需要千万次的工具调用,若调商业 API,数万美金瞬间化为泡影。
- 数据质量:简单的 RAG 数据无法模拟现实中“多源交叉比对”和“穷举统计”的复杂逻辑。
3. 方法论详解:打造本地化的“虚拟互联网”
LiteResearcher 的核心直觉是:将互联网“搬”进实验室,并让它高度可控。
3.1 语料库与任务的协同进化
作者并不是盲目抓取网页,而是采用了一种“掩码式”生成策略:
- 从种子语料生成 QA 对。
- 关键一步:在本地库中删除该 QA 的原始信息源,强迫模型必须通过搜索其他相关网页来“曲线救国”,从而诱导模型学会交叉验证(Cross-verification)和枚举(Enumeration)。
3.2 极速本地工具链
为了支撑高并发的 RL Rollout,LiteResearcher 搭建了工业级的本地检索基础设施:
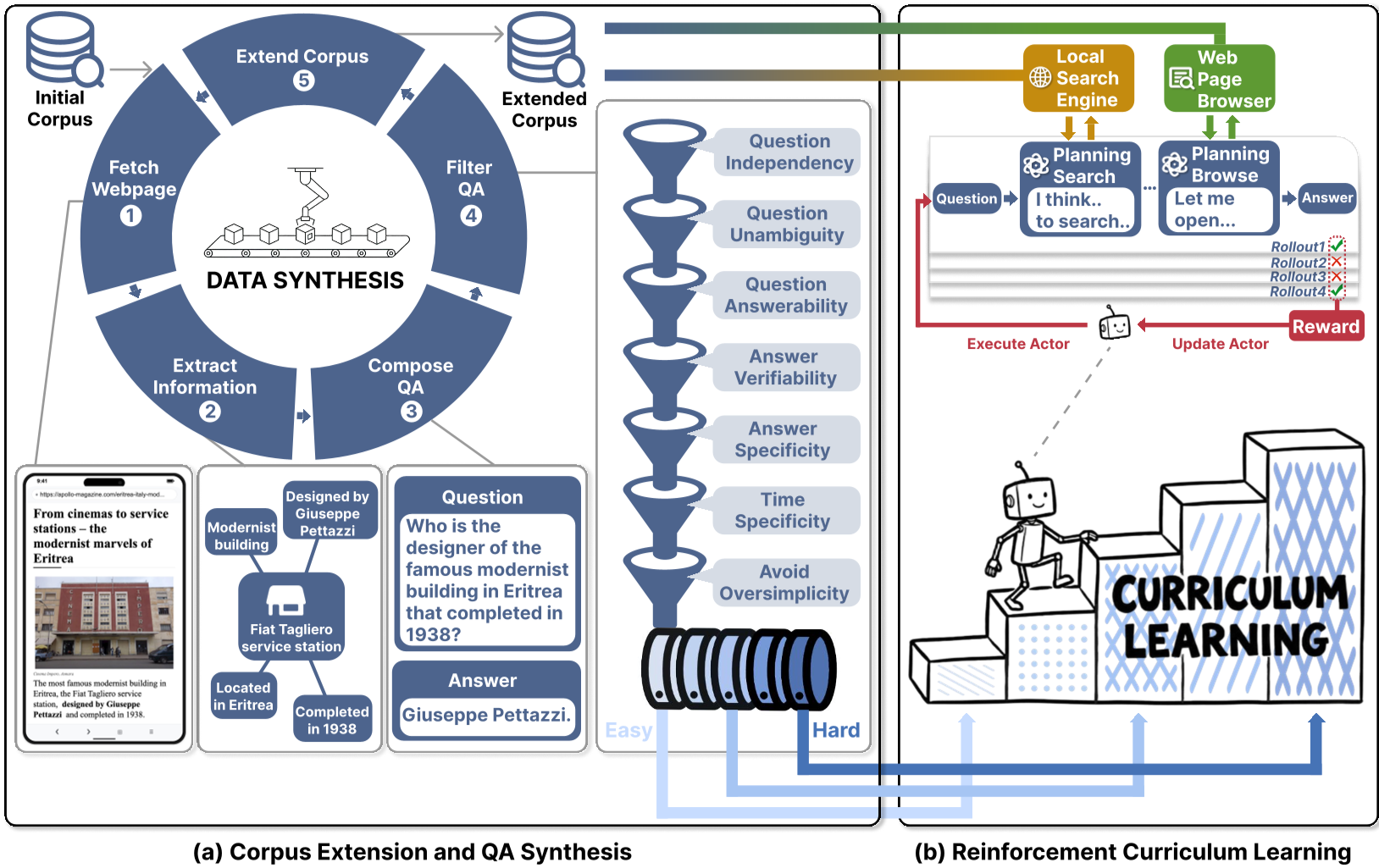
- 搜索:使用 BGE-M3 混合检索和 DiskANN,单次查询仅需 0.15s。
- 浏览:全网页 Markdown 处理 + PostgreSQL 存储,相比 Jina Reader 提速 46 倍。
3.3 难度感知课程 RL
训练 Agent 最怕“饱和”。如果任务太简单,梯度为 0;太难,模型满头雾水。 LiteResearcher 采用 GRPO 算法,并实施两步走:
- Stage 1:基础搜索。
- Stage 2:增加多跳推理(Multi-hop)和科学领域难题。
- 过滤机制:只有在 K=8 次尝试中做对 1~7 次的任务才进入训练,完美避开无效数据。
4. 实验与结果:小模型的“降维打击”
实验结果令人震撼。LiteResearcher-4B 在多个维度上展现了统治力。
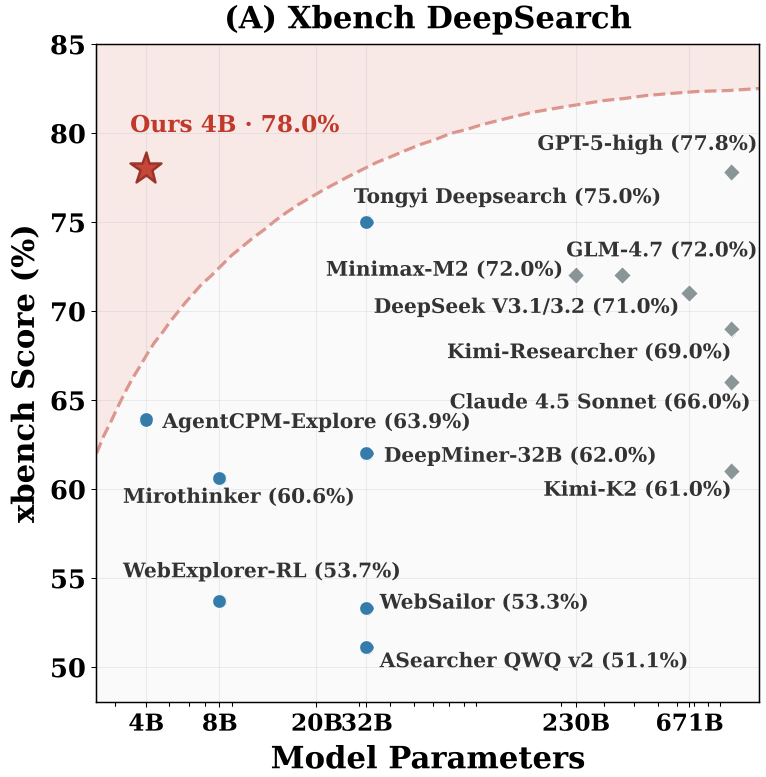
- GAIA 榜单:以 71.3% 的成绩持平 Claude-4.5 Sonnet,领跑开源界(相比 SFT 提升了 15.7%)。
- 成本优势:完成 7300 万次工具调用,本地环境开销为 0。
消融研究:为什么一定要 On-policy?
作者发现,Agent 的长程搜索轨迹对 Policy Lag 极其敏感。如果使用 Off-policy 频繁更新,由于策略偏差的累积,模型很快会陷入性能衰退。而 LiteResearcher 坚持的纯 On-policy 更新则展示了极其优美的单调上升曲线。
5. 深度洞察:RL 究竟改掉了什么?
通过分析训练过程,作者发现 RL 的本质收益在于消除冗余。
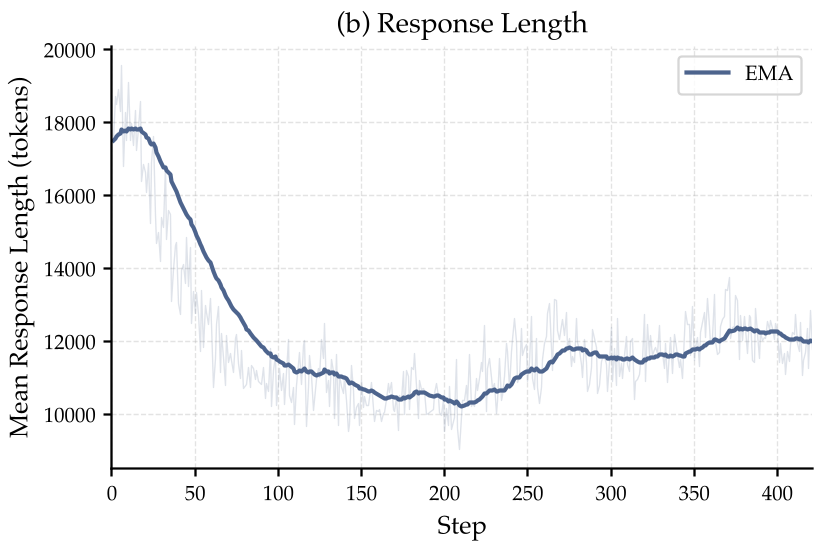 原本 SFT 出来的模型常会陷入“复读机式搜索”。而在单纯的正确性 Reward 驱动下,RL 自动让模型学会了:如果一条路走不通,赶紧换个关键词,别再重复劳动。这导致平均对话轮数锐减,但得分反而更高。
原本 SFT 出来的模型常会陷入“复读机式搜索”。而在单纯的正确性 Reward 驱动下,RL 自动让模型学会了:如果一条路走不通,赶紧换个关键词,别再重复劳动。这导致平均对话轮数锐减,但得分反而更高。
6. 总结与启示
LiteResearcher 的成功给了我们两点深刻启示:
- 数据工程才是第一生产力:如何构建一个能模拟真实动态、且能自动扩容的本地环境,是 Agent 进化的先决条件。
- RL 的潜力远未见顶:小模型并非能力不足,而是缺乏足够的、高质量的“实战训练”。
局限性:尽管检索极快,但小模型在处理超过 20 个搜索页面的超长上下文时仍有压力,未来可能需要更强的外部记忆模块支持。
本文由资深学术技术主编深度重构。