本文探讨了大语言模型(LLM)作为写作辅助工具对人类写作语义、风格和决策的深远影响。研究通过人类用户实验、ArgRewrite-v2数据集对比以及 ICLR 2026 审稿意见分析,揭示了 LLM 会导致写作观点中立化、语义同质化并显著改变科学评价标准。
TL;DR
一份来自 UC Berkeley、DeepMind 和华盛顿大学的最新联合研究警示:超过 10 亿人使用的 LLM 写作助理正在悄悄抹杀人类的个性。实验证明,过度依赖 LLM 不仅让文章变得千篇一律,更会导致观点强行转向“中立”,并使科学评审的标准从“创新”滑向“可复制性”。
1. 消失的“个人声线” (Personal Voice)
我们常说 AI 提高了生产力,但代价是什么?研究团队通过 100 人的对照实验发现,重度使用 AI 的作者普遍感到创作力下降,文章不再像出自自己之手。
核心痛点:
- 观点稀释:当你问 AI“金钱是否带来幸福”时,LLM 倾向于产出一种平衡得近乎平庸的回答。重度用户产出中立文章的比例暴增了 70%。
- 轶事蒸发:人类写作喜欢用个人经历(如“我朋友出车祸的经历”)来佐证观点,而 LLM 的编辑习惯是删掉这些“不专业”的细节,替换为统计数据。
2. 语义空间的“向心力”:算法如何制造平庸
作者利用 PCA(主成分分析)对文本嵌入向量进行了可视化,直观展示了 LLM 的“格式化”能力。
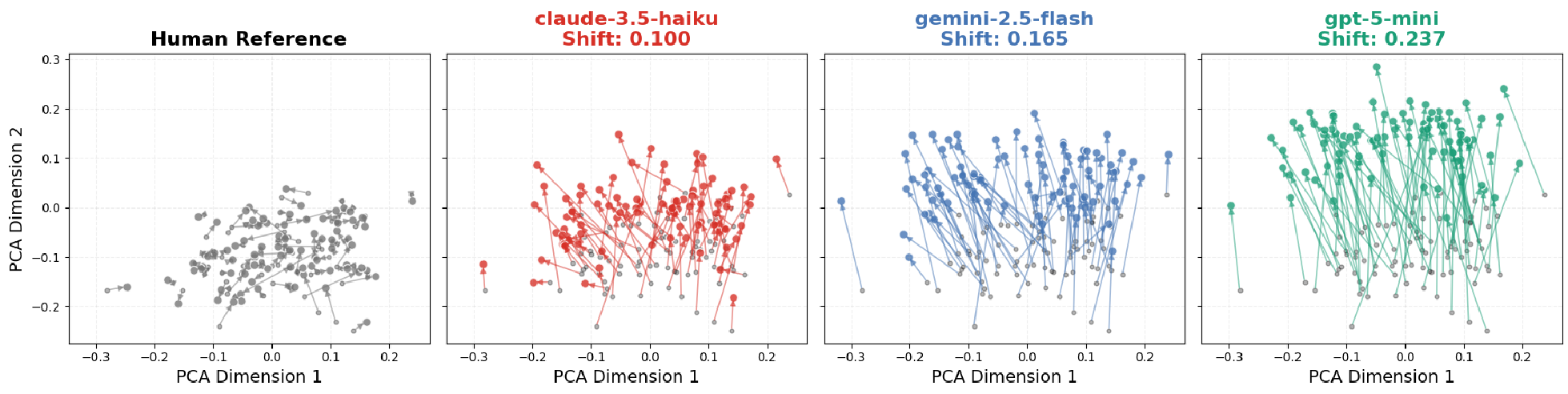 上图展示了 ArgRewrite-v2 任务中人类与 AI 的编辑路径对比。人类的编辑(左)位移小且方向各异;AI(右)的位移巨大且全部冲向同一个“算法盲区”。
上图展示了 ArgRewrite-v2 任务中人类与 AI 的编辑路径对比。人类的编辑(左)位移小且方向各异;AI(右)的位移巨大且全部冲向同一个“算法盲区”。
技术洞察: LLM 不是在“修补”你的文章,而是在“重写”。研究显示,即便你告诉 AI 只需要“修改语法”,它依然会进行大规模的词汇替换(JSD 散度是人类的 3 倍)。它强制使用更多的代词(减少第一人称)、更多的形容词和连词,制造出一种“虚假的专业感”。
3. 科学界的警钟:ICLR 2026 的 AI 幽灵
最令人震惊的发现来自对 ICLR 2026 审稿意见的分析。在野外环境(In the wild)下,AI 已经占据了 21% 的评审席位。
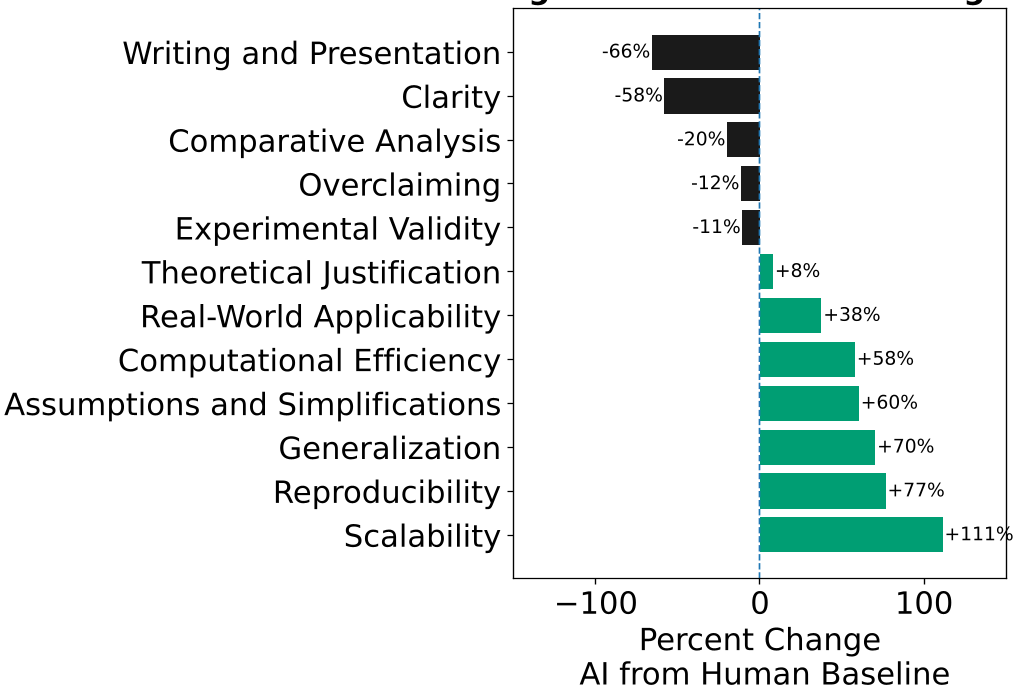 上图对比了人类评审与 AI 评审关注点的差异。
上图对比了人类评审与 AI 评审关注点的差异。
变异的评价准则:
- 人类更看重:研究的清晰度(Clarity)和重要性(Significance)。
- AI 更看重:可复现性(Reproducibility)和可扩展性(Scalability)。
- 后果:AI 评审给出的分数平均比人类高出 1 分。这意味着如果未来评审全面自动化,科学界可能会充斥着大量“平庸但可复现”的研究,而那些具有颠覆性、写作风格独特的原创工作可能被埋没。
4. 深度洞察:为什么 RLHF 成了“洗脑”推手?
为什么所有模型(GPT, Claude, Gemini)的表现如此一致?
作者指出,RLHF(基于人类反馈的强化学习) 可能是罪魁祸首。为了迎合人类的平均喜好,模型学会了产生一种“听起来很专业、很客观、充满了逻辑连接词”的风格。这种风格本质上是文字版的“点击诱饵(Clickbait)”,虽然让人满意,却剥夺了人类思考的深度和独特性。
5. 总结与启示
这项工作不仅仅是一次学术分析,它对未来的 AI 产品设计提出了核心挑战:
- 能力缺陷:目前的 LLM 无法在辅助写作的同时保持原意。
- 社会风险:当 10 亿人的电子邮件、演说稿和学术论文都经过同一种算法的脱水与漂白,我们的文化多样性将面临前所未有的危机。
资深主编点评: 这篇论文刺破了“AI 让创作更简单”的幻象。它告诉我们,当我们为了省力将笔交给 AI 时,我们也交出了修正世界、表达独特偏见和情感的权利。未来的 AI 应该致力于多元化对齐(Pluralistic Alignment),而不是制造一个全球统一的“复读机”。