本文提出了 AutoTTS,这是一个环境驱动的模型推理阶段缩放(Test-Time Scaling, TTS)策略自动发现框架。通过将 TTS 策略设计建模为在离线重放环境中的控制器合成(Controller Synthesis)任务,AutoTTS 能够自动探索并优化推理计算资源的分配,在数学推理等任务中实现了 SOTA 的性能与效率平衡。
TL;DR
传统的 LLM 推理加速(Test-Time Scaling)主要靠人工拍脑袋想策略。本文提出的 AutoTTS 彻底颠覆了这一现状:它通过构建一个极其低廉的“离线重放环境”,让 AI 智能体自己在里面“对弈”寻找最优的计算资源分配方案。最终发现的 Confidence Momentum Controller (CMC) 策略,在某些任务下仅需 30% 的 token 就能达到并超越传统方法的准确率。
背景定位:从“手工微调”到“算法进化”
在论文作者看来,目前的 TTS 策略研究正处于“前 AutoML 时期”。无论是增加采样宽度的 Best-of-N,还是增加推理深度的思维链扩展,都像是手工作坊里的产品。AutoTTS 的出现,本质上是在 TTS 领域推行了一次 “环境驱动的自动化革命”。
核心洞察:为什么要搞“重放环境”?
在自动发现策略时,最头疼的问题是:评估太贵了。如果你每改进一行代码都要重新跑一遍 Llama-70B 的推理,那研究经费会瞬间烧光。
AutoTTS 的天才之处在于:
- 预收集轨迹:先跑一次昂贵的推理,把所有的推理分支、中间过程、探测信号全部存成“索引矩阵”。
- 离线控制器回放:新设计的策略只需在这个矩阵上进行“查表”决策。这就好比用上帝视角玩扫雷——动作是实时生成的,但地雷的位置(模型输出)是早就定好的。
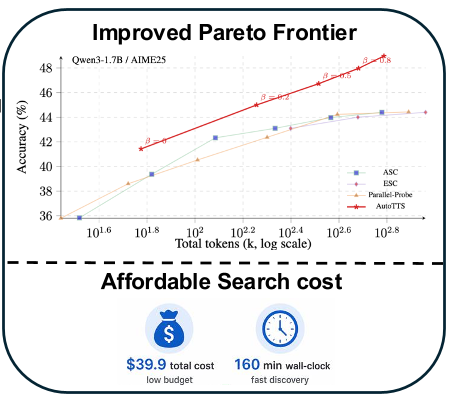
核心方法论:β 参数化与执行痕迹反馈
为了防止 AI 智能体在搜索过程中“走火入魔”(过度拟合搜索集),作者设计了两个关键约束:
- Beta Parameterization:强制要求控制器只能暴露一个
beta参数,所有的内部阈值都必须随beta单调变化。这保证了策略的鲁棒性和一致性。 - Execution Trace Feedback:不仅告诉 AI 结果是对是错,还给它看详细的“心路历程”——哪些分支被错误修剪了?哪些地方浪费了计算资源?这让 AI 能够像人类工程师一样进行“诊断式”的代码改进。
实验战果:横扫手工基线
实验结果令人振奋。AutoTTS 发现的策略在 Qwen3 全系列模型上表现出色,尤其是在 held-out(未见过)的任务上展现了极强的泛化能力。
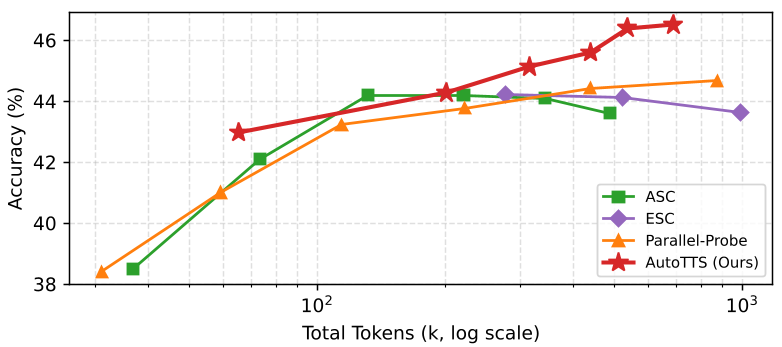 (a) Qwen3-0.6B 在 AIME25 上的表现:AutoTTS 的曲线始终位于最左上方,意味着同等准确率下成本更低。
(a) Qwen3-0.6B 在 AIME25 上的表现:AutoTTS 的曲线始终位于最左上方,意味着同等准确率下成本更低。
深度拆解:AI 发现了哪些人类没想到的黑科技?
AutoTTS 最终生成的 CMC (Confidence Momentum Controller) 策略包含了一些非常精妙的设计:
- 趋势感知停止 (EMA Momentum):它不看瞬时的信心值,而是看信心值的指数移动平均(EMA)。只有当信心值够高且“趋于稳定”时才停止,有效避开了随机碰撞出的错误共识。
- 宽度-深度联动:如果当前信心的增长势头(Delta)变缓,它会自动激活“加宽”探索,反之则深挖现有路径。
- 对齐优先分配:它会把更多的算力资源分配给那些与“当前领跑答案”一致的分支,实现资源的动态倾斜。
局限性与展望
尽管 AutoTTS 在数学推理上取得了巨大成功,但目前的控制空间主要集中在“宽与深”的二维维度。未来,如果能引入更复杂的行动集(如动态改变提示词策略、多模型协作),AI 可能会进化出更令人惊叹的推理逻辑。
总结
这篇文章有力地证明了:在 AI 时代,人类最应该投入精力的地方不是设计算法本身,而是设计能让算法自我进化的“环境”。