本文提出了 LoopCTR,一种基于循环缩放(Loop Scaling)范式的点击率(CTR)预测架构。通过递归重用模型层而不是堆叠新参数,该方法实现了计算量与参数规模的解耦,在多个基准测试中达到了 SOTA 性能。
TL;DR
在点击率(CTR)预测领域,模型缩放(Scaling)通常意味着更深的层数和更臃肿的参数。阿里巴巴与中国人民大学的研究者们提出 LoopCTR,反其道而行之:通过**递归重用(Recursive Reuse)同一模型层来增加计算深度。这种“循环缩放”范式通过过程监督,实现了“训练时多循环,推理时零循环”**的惊人效果——推理成本极低,性能却稳居 SOTA。
1. 痛点:缩放野心与部署约束的矛盾
传统的 Transformer 缩放路径(如增加深度、宽度或序列长度)虽然能提升 AUC,但会带来成比例的存储和计算开销。在工业级推荐系统中,毫秒级的低延迟要求使得这些“巨型模型”难以落地。
此外,推荐数据具有高度稀疏性。研究发现,简单地增加参数深度往往会由于过拟合而导致边际收益递减。作者认为,我们需要一种能解耦参数增长与计算增长的新方案。
2. 核心设计:LoopCTR 的“三明治”架构
LoopCTR 的核心是一个由 Entry Block(入口)、Loop Block(循环)和 Exit Block(出口)组成的架构。
2.1 循环块(Loop Block)的表达能力增强
如果只是简单地重复应用同一个 Transformer 层,模型会很快遇到表达能力瓶颈。LoopCTR 引入了两个关键模块来破局:
- 超连接残差 (Hyper-Connected Residuals, HCR):将标准残差改为多流(Multi-stream)自适应融合。其系数是输入相关的,允许模型在不同循环迭代中动态控制信息流。
- 混合专家模型 (MoE):在不增加每个样本计算量的前提下,通过稀疏激活极大地扩展了共享层的参数容量。
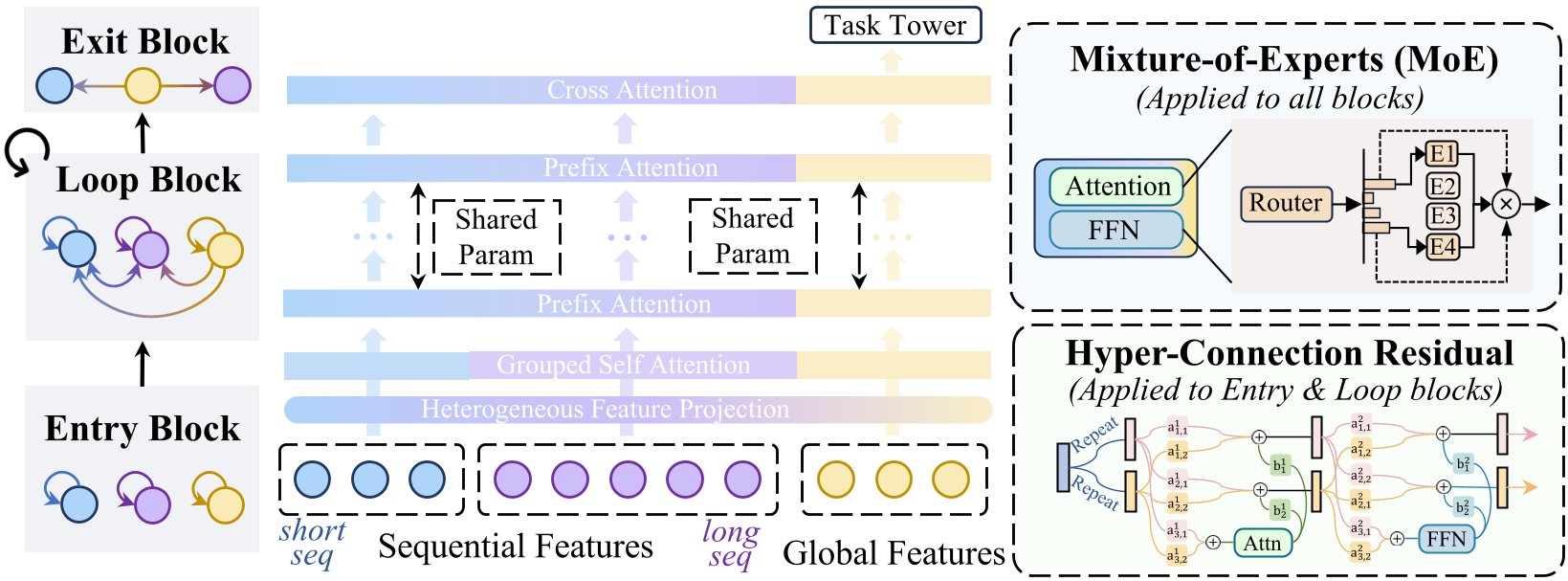 图 1:LoopCTR 整体架构,展示了其独特的三明治设计与 HCR/MoE 模块。
图 1:LoopCTR 整体架构,展示了其独特的三明治设计与 HCR/MoE 模块。
2.2 过程监督(Process Supervision)
这是实现“零循环推理”的关键。在训练期间,模型在每一个循环深度(从 0 到 L)都会通过 Exit Block 输出预测并计算 Loss。
- 逻辑本质:深层的循环作为“老师”,通过共享参数将其提取的特征知识“蒸馏”给浅层。
- 结果:在推理时,即使跳过所有 Loop Block(即 Zero-loop),Entry Block 生成的特征也已经包含了迭代优化的增益。
3. 实验结果:降维打击般的效率
在 Amazon、TaobaoAds、KuaiVideo 和大规模 InHouse 数据集上的测试显示,LoopCTR(0/3)(推理时 0 循环)在所有指标上均显著优于传统的 DIN、OneTrans 和强基线 HSTU。
| Method | AUC (Amazon) | FLOPs (InHouse) | Latency (InHouse) | | :--- | :--- | :--- | :--- | | OneTrans | 0.8689 | 417.97M | 494.58ms | | HSTU | 0.8657 | 2150.00M | 775.72ms | | LoopCTR(0/3) | 0.8715 | 13.38M | 9.26ms |
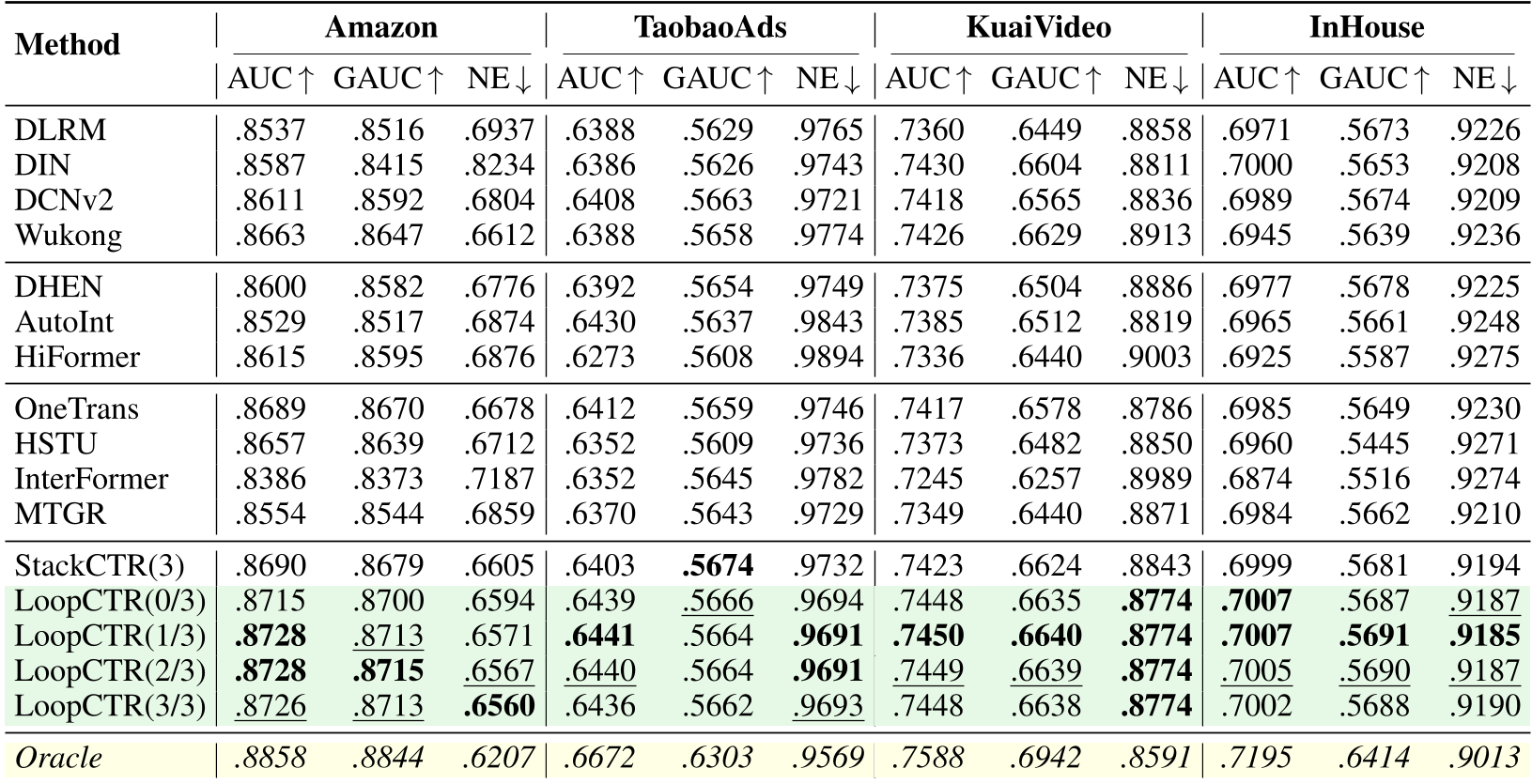 表 1:LoopCTR 与各基线的性能对比,展示了其在 AUC 和效率上的巨大优势。
表 1:LoopCTR 与各基线的性能对比,展示了其在 AUC 和效率上的巨大优势。
4. 深度洞察:被隐藏的“神谕”性能
作者通过 Oracle Analysis(即假设我们能为每个样本自动选择最佳循环深度)发现了一个惊人的结论:
- 当前模型仍有 0.02-0.04 的 AUC 潜力尚未被挖掘。
- 反直觉发现:训练循环次数较少的模型,其 Oracle 天花板反而更高。这说明减少训练循环能保持更好的表示多样性(Representational Diversity),为未来的**自适应推理(Adaptive Inference)**留下了巨大的想象空间。
5. 总结与展望
LoopCTR 成功证明了在推荐系统中,“思考”比“背诵”更重要。通过递归共享层,模型不仅更轻量,还获得了更好的泛化能力。
- 价值:为内存受限的移动端部署或极低延迟的实时推荐提供了完美方案。
- 局限:目前的自适应选择仍基于后验(Oracle),如何在线上实时判断一个样本是否需要更多循环“思考”,将是下一个研究高地。
资深主编点评:LoopCTR 的意义在于它打破了 LLM 时代“参数即正义”的思维定势。它告诉我们,通过巧妙的设计,共享参数同样能涌现出深度推理的能力,而这对成本敏感的工业界而言,价值千金。