本文推出了 LPM 1.0 (Large Performance Model),这是首个用于单人全双工语音-视觉对话表演的视频生成系统。通过 17B 参数的 Diffusion Transformer 架构和多模态条件控制,LPM 1.0 实现了高表现力、实时推理和长程身份稳定性的统一,在 LPM-Bench 评测中达到 SOTA 水平。
TL;DR
在数字人生成领域,让角色“开口说话”已不新鲜,但让角色像真人一样“听话、反应、且持久”依然是学术界的珠穆朗玛峰。LPM 1.0 (Large Performance Model) 通过 17B 参数的 DiT 架构和创新的蒸馏算法,首次在像素空间内解决了高表现力、实时性与身份稳定性之间的冲突(Performance Trilemma)。它不仅能生成精准的口型,还能捕捉听者眼神的闪烁和点头的微表情,支持长达 10 分钟以上的稳定交互。
背景:对话即“表演”
梅斯纳尔 (Sanford Meisner) 曾言:“演戏就是反应。”在真实的对话中,听者的反应(点头、眼神交锋、情感共鸣)与说者的表达同样重要。然而,目前的 Talking-head 模型大多是“聋子”,它们只根据语音机械地驱动口型。
LPM 1.0 的动机源于解决现有视频生成模型的三难困境:
- Expressive Quality:如何展现丰富的、非重复的微表情?
- Real-time Inference:如何在直播和交互中实现毫秒级响应?
- Long-horizon Stability:如何保证角色在长达数分钟的对话中“脸不崩、色不偏”?
方法论:从 Base 到 Online 的全栈设计
1. 架构:17B 规模的交错式音频卷积
LPM 1.0 的核心是一个 17B 参数的 Diffusion Transformer (DiT)。为了处理“双工”对话(即同时说和听),研究团队设计了一种交错音频注入策略:偶数层处理“说话音频”(驱动口型和节奏),奇数层处理“听觉音频”(驱动反应和神态)。这种设计避免了参数冗余,并有效缓解了不同动作模态间的梯度冲突。
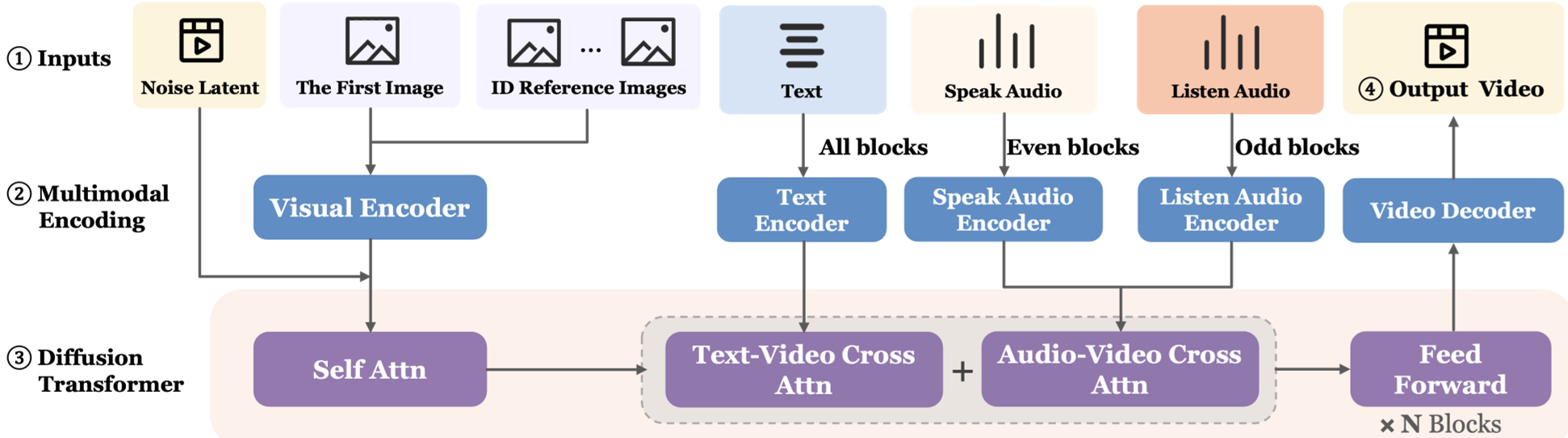
2. 身份锚定:多参考图像注入
为了解决“单张参考图无法推演侧脸或特定表情”的问题,LPM 引入了 Identity-aware Multi-reference Pipeline。模型同时输入全局图、多视角图(侧面/背面)和 8 种核心表情模板。这些图像直接作为 Token 拼接到自回归序列中,通过 RoPE (旋转位置编码) 加以区分,从而实现长效的身份稳定性。
3. Online 进化:四阶段蒸馏
为了达到实时性,Base 模型被蒸馏为 Online LPM。这是一种“骨干+细化器”(Backbone-Refiner) 的因果流式架构。
- Backbone:负责在 2 个步长内确立粗略的动作轨迹,采用预测历史的“噪声缓存”来增强自回归稳定性。
- Refiner:在 1 个步长内恢复高清纹理。 这种通过轨迹稳定与细节重建分离的策略,解决了自回归生成中常见的误差累积问题。
实验与结果:定义对话评价新标准
由于传统的视觉指标无法衡量对话的自然度,作者推出了 LPM-Bench。这是首个涵盖说、听、多轮对话、复杂动作及风格化角色的多模态基准。
关键战绩:
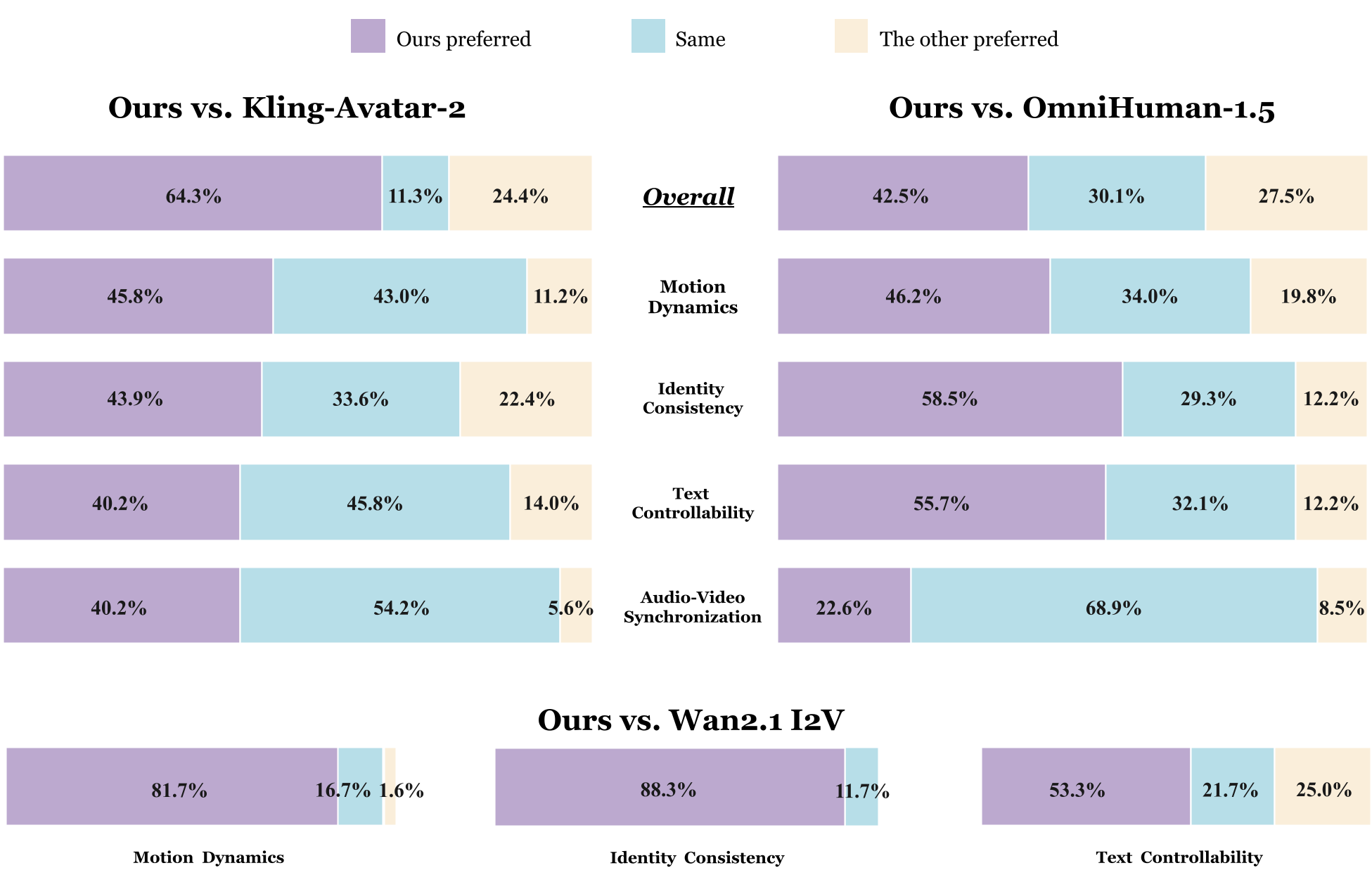
- 离线对战:在 720P 分辨率下,Base LPM 在人类评价(GSB)中全面压倒了 Kling-Avatar-2 和 OmniHuman-1.5,尤其在身份一致性(58.5% 胜出)和文字可控性上表现惊人。
- 在线实时:Online LPM 虽然经过蒸馏,但在口型同步和动作平滑度上依然保持了与 Base 模型高度一致的水平,单 Chunk 处理仅需约 350ms。
深度洞察:身份保护与安全
作为资深学术编辑,我注意到 LPM 1.0 在安全层面的布局。除了技术创新,团队同步开源了 AI 生成检测模型,并集成了 invisible watermarking (不可见水印)。在 Deepfake 争议不断的今天,这种从底层协议接入 C2PA 标准的做法,展现了顶级 AI 团队的社会责任感。
总结
LPM 1.0 不仅仅是一个更好的视频生成模型,它实际上构建了一套完整的数字人执行系统 (Runtime)。它向我们展示了:当算力(17B DiT)、数据(过滤后的全双工对话流)与工程(Ulysses 序列并行、四阶段蒸馏)完美融合时,数字人将真正告别“提线木偶”时代的迟钝感,进化为具有感知和反应能力的实时演职人员。
未来,随着该框架与具身智能和环境感知的结合,我们有望在开放世界游戏中看到真正能通过“微表情”向玩家传递情绪、而非仅仅吐字如金的 NPC。