The paper introduces MACRO, a novel framework comprising MacroData (400K samples) and MacroBench (4,000 samples) to address the performance collapse of in-context image generation models when dealing with multiple reference images (up to 10). By fine-tuning open-source models like Bagel and OmniGen2 on this structured long-context data, the authors achieve state-of-the-art results across four key domains: Customization, Illustration, Spatial reasoning, and Temporal dynamics.
TL;DR
Current in-context image generation models (like Bagel or OmniGen2) are "short-sighted"—they perform well with one or two reference images but fall apart as soon as you give them more. MACRO fixes this by introducing MacroData, a massive 400K-sample dataset supporting up to 10 references, and MacroBench, a rigorous benchmark. By training on structured data across four dimensions (Customization, Illustration, Spatial, and Temporal), the authors have effectively "taught" models how to reason across long visual contexts, narrowing the gap with closed-source giants like Gemini-3-Pro.
The Problem: The "Many-Reference" Ceiling
For years, the research community focused on "Conditioned Generation"—give the model a prompt and maybe one face (Identity Preservation), and it works. But real-world tasks are more complex:
- Spatial Reasoning: "Here are 8 views of a chair; show me the 9th."
- Narrative Illustration: "Here are 5 storybook pages; generate the 6th with consistent characters."
Existing models fail here because their training data is shallow. Most datasets (like Echo4o or MICo) focus on 1-3 images. When you push these models to 6+ images, they suffer from "attention fatigue," forgetting key details or hallucinating incorrect attributes.
Methodology: The Four Pillars of MacroData
The authors identified that multi-reference generation isn't just about "identity"; it's about different types of inter-image dependencies. They built MacroData with 100K samples for each of these:
- Customization: Composing multiple subjects (human, object, scene) into one coherent image.
- Illustration: Parsing long text-image interleaved sequences to maintain narrative flow.
- Spatial: Mastering 3D consistency (Outside-in objects and Inside-out scenes).
- Temporal: Forecasting the next keyframe based on a historical sequence.

The Data Pipeline: From Noise to Structure
Instead of scraping noisy web data, the authors used a hybrid approach:
- Source Selection: High-quality identities from OpenSubject, 3D renderings from Objaverse, and 360-degree panoramas.
- VLM-as-Judge: Using Gemini-3-Flash to curate and filter samples. If the generated target didn't faithfully represent all 10 input images, it was discarded.
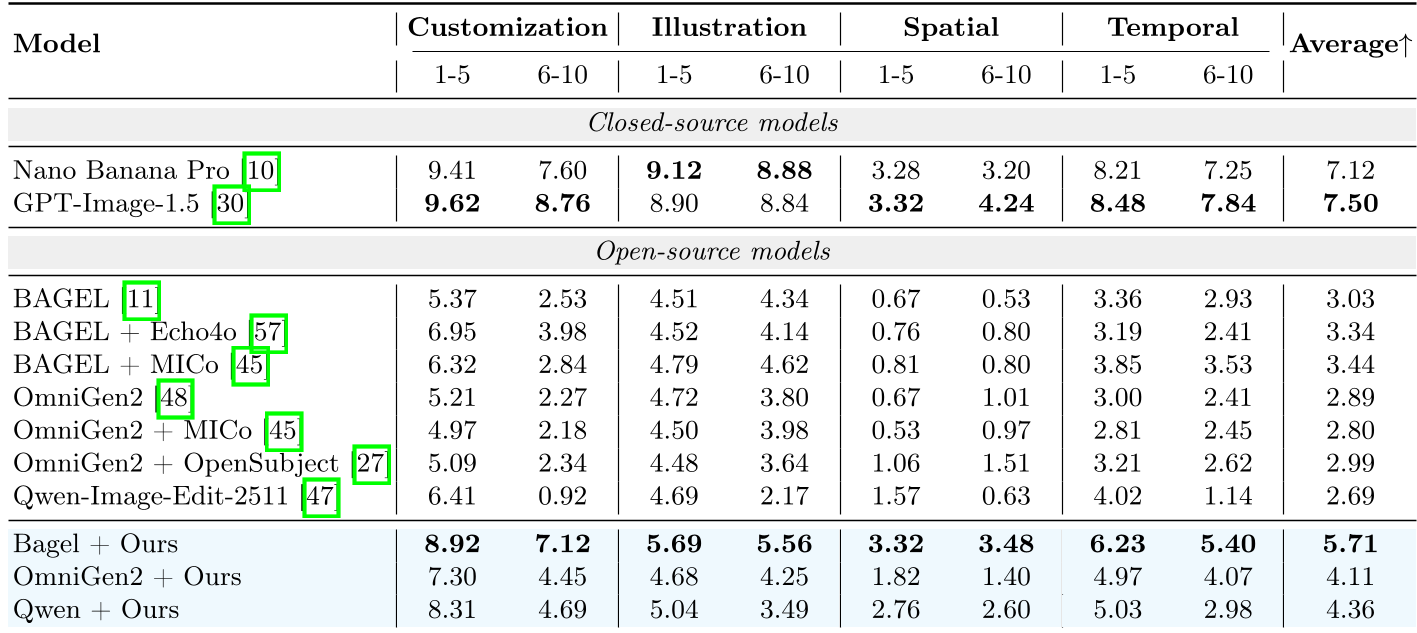
Experimental Results: Scaling to the Long-Context
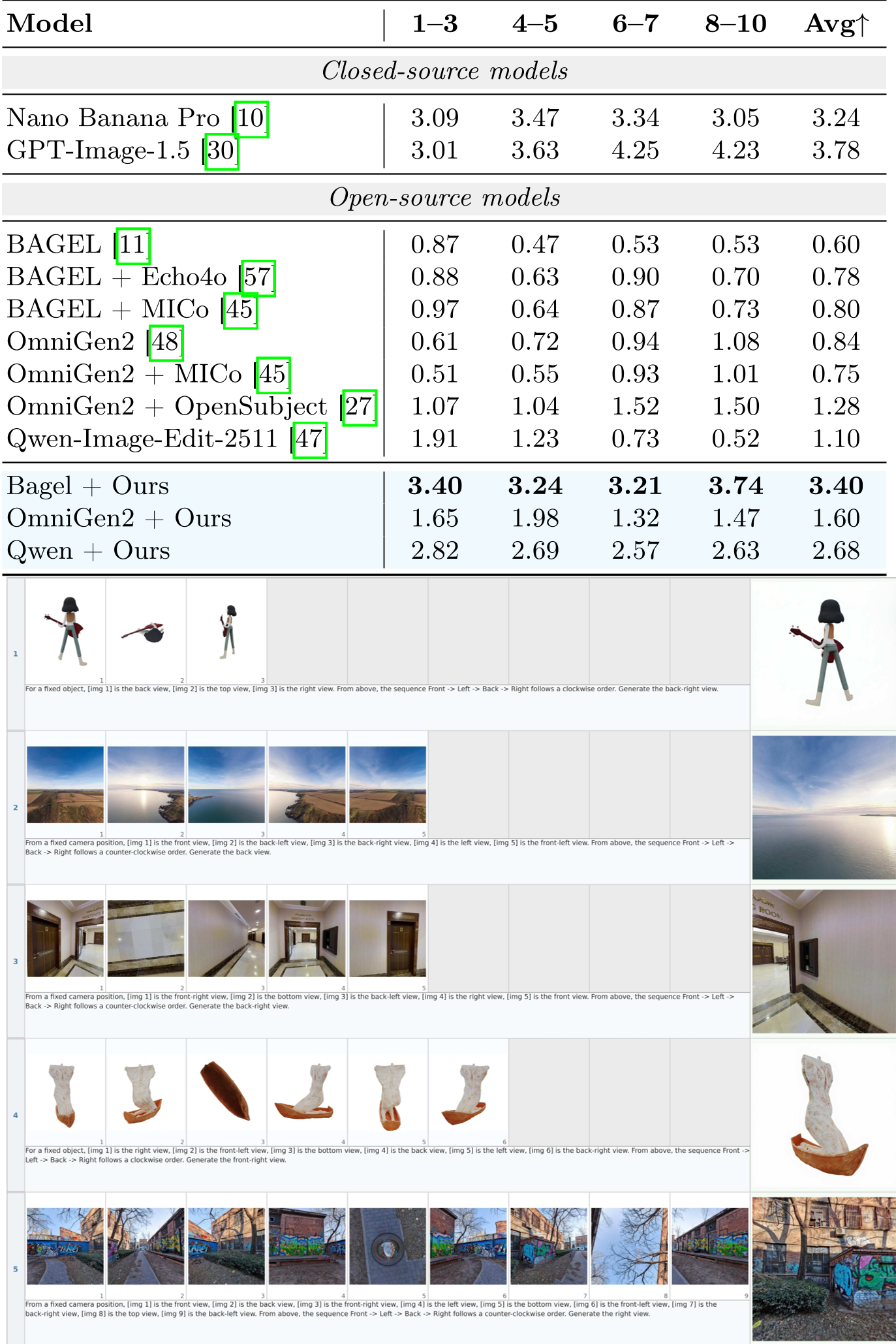
The impact of MacroData is visceral. In the MacroBench benchmark, which tests models on buckets of 1-3, 4-5, 6-7, and 8-10 images, the "Macro-Enhanced" models showed remarkable robustness.
Key Insights:
- The "Synergy" Effect: Training on Spatial and Temporal tasks actually helped the model perform better on Customization. Cross-task co-training provides a "richer" feature space for the model.
- Token Selection is King: As you add more images, the token sequence length explodes. The authors explored Text-Aligned Selection (keeping only the most relevant visual tokens based on the prompt), which maintained 99% of performance while drastically reducing compute.
 Even with 6+ inputs (different clothes, different people, specific background), the model retains consistent identities and follows the prompt.
Even with 6+ inputs (different clothes, different people, specific background), the model retains consistent identities and follows the prompt.
Qualitative Proof
In the spatial domain, baseline models often "flip" the object or lose its texture. MACRO-enabled models maintain the geometry because they've seen structured examples of how views relate to each other.
Critical Analysis & Conclusion
Limitations: Even with MacroData, performance still dips slightly at the 10-image mark. It’s a "hard" problem that involves more than just data—it touches on the fundamental attention limits of Transformers. Furthermore, text rendering remains a weak spot.
Takeaway: This paper is a wake-up call for the community: we don't necessarily need "bigger" models to handle complex multi-reference tasks; we need "longer" data. By treating image generation as a long-context reasoning problem, MACRO paves the way for truly autonomous visual storytellers and 3D-aware generative agents.