本文提出了 MAG-3D,一种用于 3D 场景理解的无需训练(Training-free)的多智能体协作框架。通过协调规划、开放词汇定位和程序化几何验证,该方法在 Beacon3D 和 MSQA 两个挑战性基准上均取得了 SOTA 性能。
TL;DR
清华大学与字节跳动 Pico 团队提出了 MAG-3D,这是一个无需任何 3D 训练(Training-free)的多智能体框架。它通过将复杂的 3D 空间推理任务分解给三个专门的“专家智能体”——规划员(Planning)、定位员(Grounding)和程序员(Coding),利用现成的 2D 基础模型实现了超越特定领域训练(In-domain tuning)模型的 3D 理解能力。
痛点深挖:为什么 3D 空间推理这么难?
尽管 2D 视觉语言模型(VLMs)已经很强大,但在 3D 场景中往往会“翻车”。主要挑战在于:
- 观察碎片化:3D 场景由多个视角、存在遮挡的 RGB 帧组成,模型难以在脑中构建全局一致的地图。
- 幻觉问题:缺乏显式的几何对齐,模型常根据语言先验“瞎编”空间关系,而非基于物理事实。
- 柔性缺失:现有方法要么需要大量 3D 标注数据微调,要么使用固定的硬编码逻辑,无法应对开放世界的各种刁钻提问。
方法论详解:三位一体的专家协作系统
MAG-3D 的核心直觉是:不要让一个模型干所有事。作者通过一个共享的“场景记忆(Shared Scene Memory)”将三个职能完全解耦:
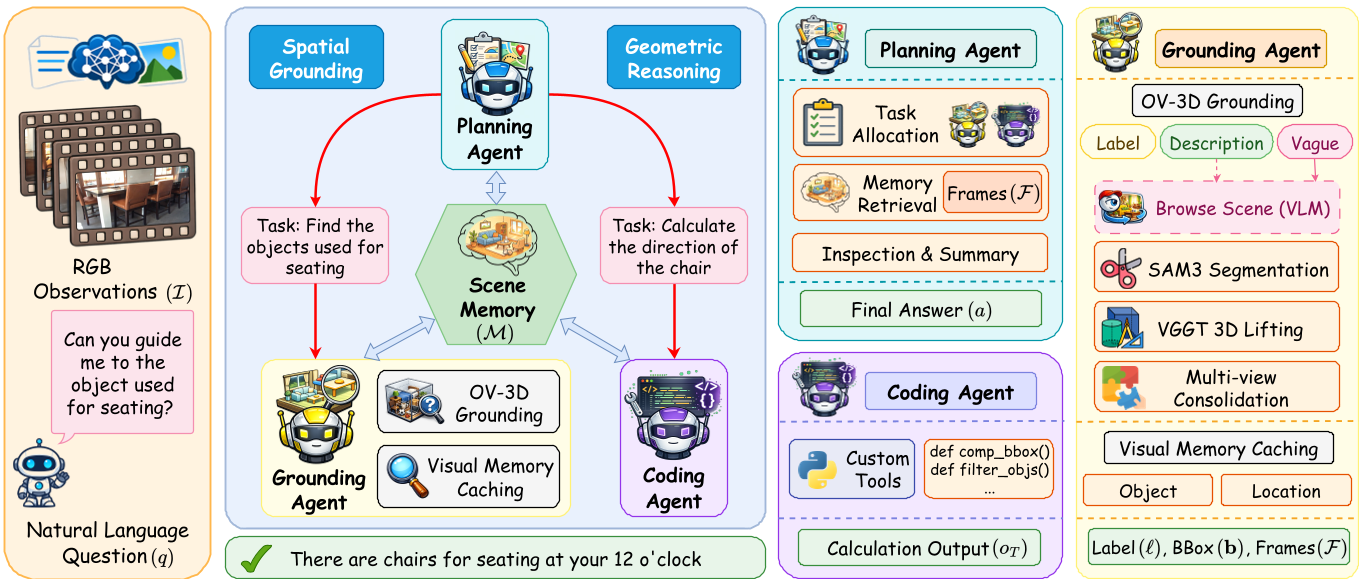
1. Planning Agent:大脑中枢
负责任务拆解。比如面对提问“电视机左边的椅子是什么颜色?”,它会先命令定位员找“电视机”和“所有椅子”,再让程序员算空间位置,最后汇总得出答案。
2. Grounding Agent:空间搜索引擎
它通过 VGGT 技术将 2D 分割掩码(SAM3 提取)投影到 3D 空间,并建立3D 视觉记忆(3D Visual Memory)。最巧妙的是其体素覆盖评分机制,它能精准找到观测目标最完整、无遮挡的最佳视角帧提供给主模型参考。
3. Coding Agent:严谨的几何学家
通过生成 Python 代码(如计算 Bounding Box 的中心距、旋转后的相对位置)进行显式运算。这种“程序化验证”彻底消灭了 LLM 在处理数字和空间坐标时的低级错误。
实验与结果:无需训练,反超 SOTA
MAG-3D 在 Beacon3D 和 MSQA 两大榜单上刷新了纪录。
- 超越训练模型:在 Beacon3D 上,MAG-3D(基于 Seed-1.6)的 Obj-QA 分数达到 27.5,远超经过专门训练的 SceneCOT(23.2)。
- 一致性大幅提升:如下图所示,MAG-3D 显著提高了 Good Coherence(即:不仅答对了,且定位完全正确),减少了靠“蒙”答对的概率(Type-2 错误)。
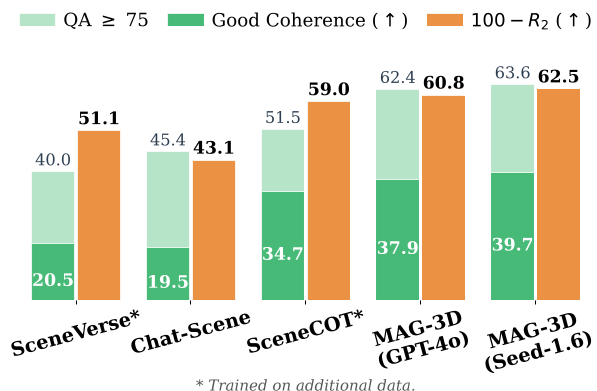
在消融实验中(Tab. 7),采用 3D-based Visual Memory 相比不带记忆的方案提升了 3.3 分,证明了从海量视频帧中精准筛选“高质量 3D 观测”的必要性。
深度洞察与总结
MAG-3D 的成功预示了一个趋势: 解决复杂的 3D 推理不再单纯依赖于“喂数据”来训练更大的端到端模型,而是通过**智能体工程(Agentic Engineering)**来释放现有 2D 基础模型的潜能。
- 优点:零样本、可解释性强(有代码、有定位框)、灵活可扩展(可随时更换更强的底层 LLM)。
- 局限性:依赖于视觉几何模型(如 VGGT)的重建精度,在稀疏视角或极度恶劣的光照下可能受限。
- 启示:未来的 3D 场景理解可能会演变为一个“动态程序生成”的过程,LLM 负责逻辑调度,而几何工具负责物理验证。
作者总结: MAG-3D 不仅是一个模型,更是一套处理物理世界信息的“新范式”。它为自动生成大规模 3D 标注数据提供了可能。