本文提出了 SAGE-GRPO,一种面向视频生成后训练对齐的流行感知强化学习框架。通过精准的 ODE-to-SDE 转换和双重信赖域约束,该方法在 HunyuanVideo 1.5 上显著提升了视频的视觉质量(VQ)、运动质量(MQ)和文本一致性(TA)。
TL;DR
在视频生成的大模型时代,如何通过强化学习(RL)微调让视频更符合人类偏好?本文指出,传统的 GRPO 方法在视频领域“失灵”的核心在于探索噪声过大导致偏离数据流形。SAGE-GRPO 通过微观层面的“对数修正 SDE”和宏观层面的“双重信赖域”约束,实现了极高稳定性的视频对齐,在 HunyuanVideo 1.5 上刷新了多项指标。
1. 痛点:视频 RL 的“出轨”挑战
在语言模型(LLM)中,GRPO 已经证明了其在对齐方面的强大威力。然而,迁移到视频生成时,问题接踵而至:
- 探索与质量的矛盾:为了让模型探索更好的结果,我们需要将确定性的 ODE 采样转为随机的 SDE。但现有的 FlowGRPO 等方法使用一阶近似,在噪声较大时会注入过多的能量,导致生成的视频出现“崩坏”。
- 流形漂移(Manifold Drift):视频数据存在于一个极高维但结构严密的流形上。一旦探索步子太大,采样点就会飞出流形,变成毫无意义的像素杂质。
- 梯度失衡:在扩散过程的不同阶段(Step),梯度的量级差异巨大(有时差几个数量级),导致模型只学到了某些阶段的特征,忽略了全局结构。
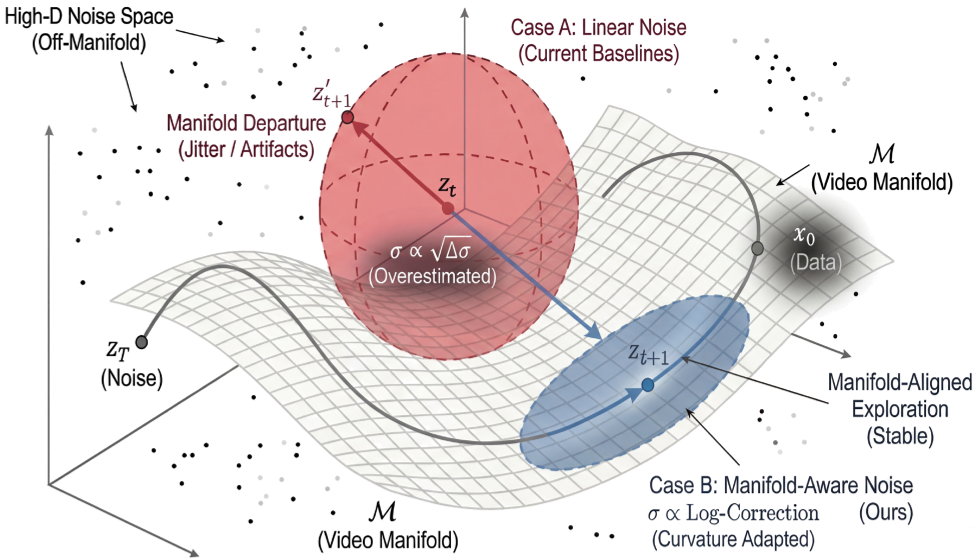 图 1:几何直观图。红色代表传统 SDE 导致的流形偏移,蓝色为 SAGE 的流形感知 SDE,更贴合视频轨迹。
图 1:几何直观图。红色代表传统 SDE 导致的流形偏移,蓝色为 SAGE 的流形感知 SDE,更贴合视频轨迹。
2. 核心方法论:微观精准,宏观稳健
SAGE-GRPO (Stable Alignment via Exploration) 的核心逻辑可以概括为:在流形的边缘试探,但绝不越界。
2.1 微观:精准流形感知 SDE
作者发现,传统方法忽略了信号衰减的曲率。通过对随机微分方程进行积分推导,他们引入了一个对数项修正: 这个修正确保了注入的噪声能量恰到好处,既保留了探索的随机性,又让采样路径始终切于视频流形。
此外,针对梯度爆炸/消失问题,引入了 Gradient Norm Equalizer。通过对不同时刻 的梯度进行中值标准化,确保了模型对视频的“骨架”(高噪声阶段)和“皮肤”(低噪声阶段)拥有同等的优化力度。
2.2 宏观:双重信赖域 (Dual Trust Region)
传统的 KL 约束要么太死(固定锚点,限制模型进化),要么太松(步进约束,容易导致路径失控)。SAGE 提出了一种类似“位置-速度控制”的方案:
- 位置控制 (Moving Anchor):每 步更新一次参考模型。这给模型提供了一个周期性的“安全港”。
- 速度控制 (Step-wise KL):限制相邻两次迭代之间的变化。 这种组合确保了模型在不断攀爬奖励高地(Plasticity)的同时,不会跑出预训练知识的控制(Stability)。
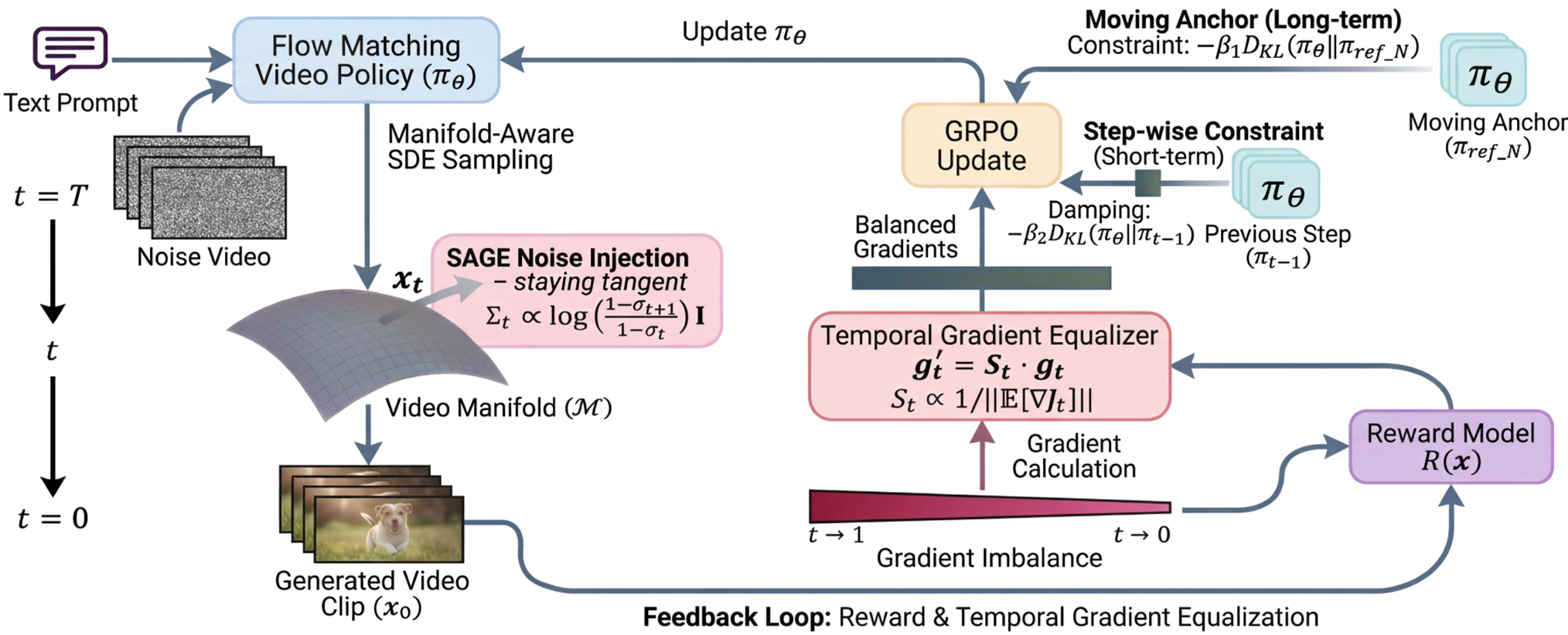 图 2:SAGE-GRPO 整体框架:精准 SDE、梯度均衡器与双重信赖域三位一体。
图 2:SAGE-GRPO 整体框架:精准 SDE、梯度均衡器与双重信赖域三位一体。
3. 实验战绩:全方位超越
团队在 HunyuanVideo 1.5 上进行了严苛的测试。
3.1 定量提升
在“对齐优先”的设置下,SAGE-GRPO 的表现令人惊艳:
- Overall Reward:从 FlowGRPO 的 0.21 飙升至 0.80。
- 视觉指标:PickScore 和 CLIPScore 均有显著提升,说明模型不仅在刷 reward 指标,是真的变好看了。
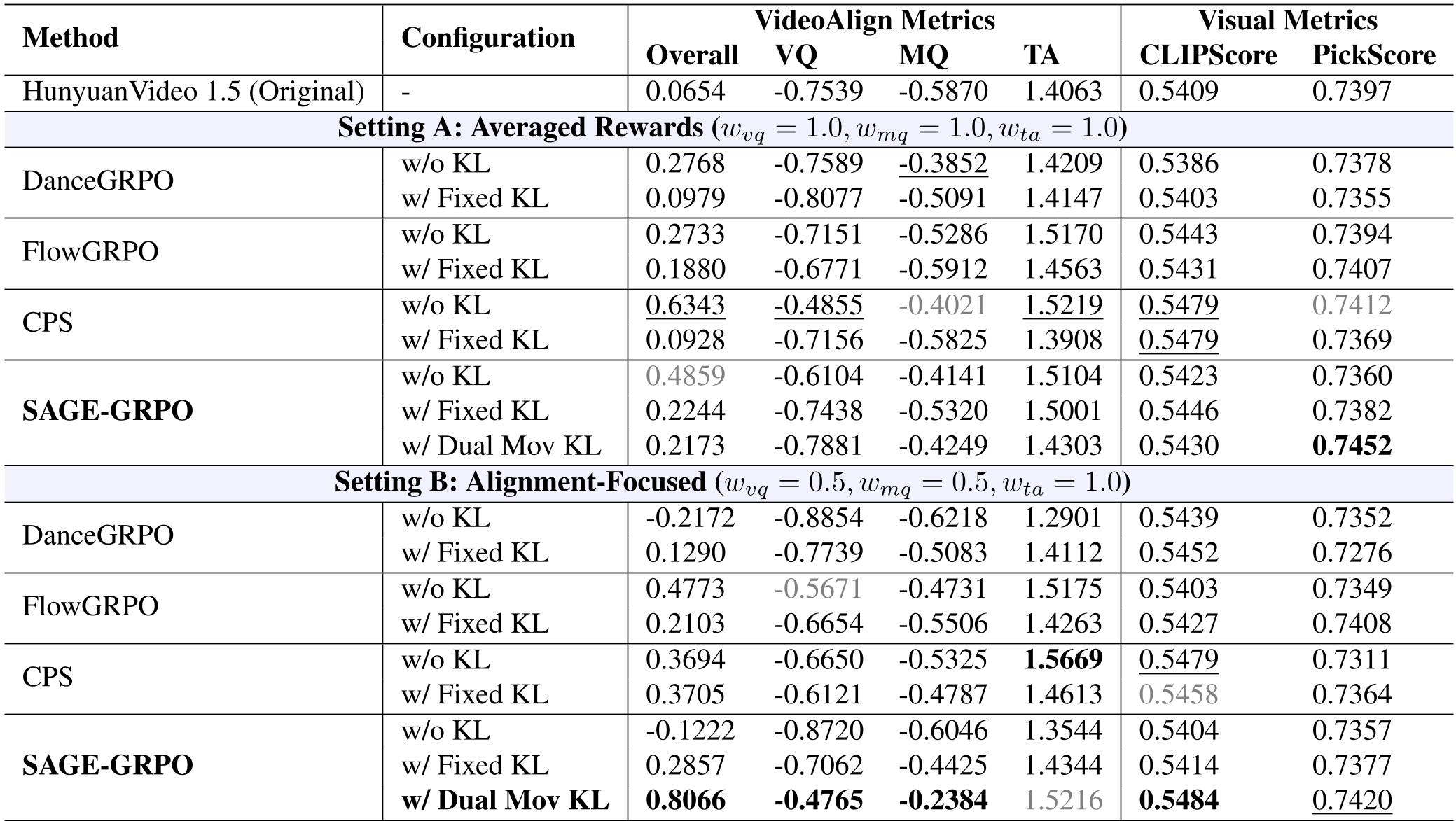 表 1:不同配置下的指标对比,可以看到 SAGE-GRPO (Dual Mov KL) 的全面领先。
表 1:不同配置下的指标对比,可以看到 SAGE-GRPO (Dual Mov KL) 的全面领先。
3.2 定性分析
从视觉效果上看(参考论文中的 Case),SAGE-GRPO 生成的视频在长时间动作的连贯性、以及复杂语义(如:士兵脸上的疲惫感与污垢)的刻画上远超基线模型。
4. 资深总编点评
SAGE-GRPO 并非简单地堆砌技巧,而是抓住了视频生成模型作为“流形生成器”的物理本质。其最大的贡献在于从数学上修补了 ODE 转向 SDE 时的近似误差。
局限性分析: 虽然实验效果卓越,但周期性移动锚点(Moving Anchor)的频率 仍需人工调优,这在不同规模的模型上可能存在泛化风险。此外,实验高度依赖 VideoAlign 作为奖励模型,如果奖励模型本身存在偏见,SAGE 可能会更高效地“学会”这些偏见。
未来启示: 该工作为视频大模型的后训练提供了一套标准的“稳定套件”。未来的研究可以探索如何将这种流形感知能力直接整合进奖励模型中,实现更深层次的端到端对齐。