ManiTwin is an automated pipeline that transforms single 2D images into simulation-ready, semantically annotated 3D digital twins for robotic manipulation. Using this pipeline, the authors curated ManiTwin-100K, a massive dataset of 100,000 high-quality 3D assets featuring physics-verified grasps and functional annotations, setting a new SOTA for scale in robotics-centric asset repositories.
TL;DR
The "Sim-to-Real" gap in robotics is often a "Data Gap." While we have millions of 3D meshes online, most are just empty shells—floating geometries with no mass, no friction, and no understanding of where a robot should grab them. ManiTwin solves this by introducing an automated pipeline that turns a single image into a "Digital Twin" that is physically grounded, semantically labeled, and verified in a physics engine. The result? ManiTwin-100K, a dataset of 100,000 objects ready to supercharge robotic manipulation training.
Problem: The "Dumb" Mesh Problem
In the world of 3D computer vision, datasets like Objaverse-XL are legendary for their scale (10M+ objects). However, for a robotics researcher, these meshes are often useless out of the box. They lack:
- Physical Properties: How heavy is this cup? How slippery is that screwdriver?
- Functional Affordances: Where is the handle of the mug? Which part of the spray bottle do I squeeze?
- Simulation Validity: Is the mesh watertight? Does the gripper collide with the object's geometry in a way that breaks the physics engine?
Manually annotating these for 100,000 objects is humanly impossible. Current robotics datasets like YCB or RoboTwin-OD are high-quality but contain fewer than 1,000 objects—not enough for a "Foundation Model" for robots.
Methodology: The ManiTwin Pipeline
ManiTwin bridges this gap through a three-stage automated pipeline:
1. Generative Digital Twining
The pipeline starts with a single image. Using a state-of-the-art 3D generative model (CLAY), it reconstructs a high-fidelity 3D mesh. But it doesn't stop at geometry. A VLM (Vision-Language Model) looks at multi-view renders to estimate the Oriented Bounding Box (OBB), mass, and friction coefficients based on visual material cues (e.g., "this looks like plastic").
2. Semantic & Grasp Annotation
Instead of random grasping, ManiTwin uses "Semantic Anchoring":
- Functional Points: VLMs identify task-critical regions like spouts, blades, or buttons.
- Grasp Proposals: The system uses GraspGen to suggest 6-DoF poses, which are then filtered to stay near the VLM-identified "safe" regions.
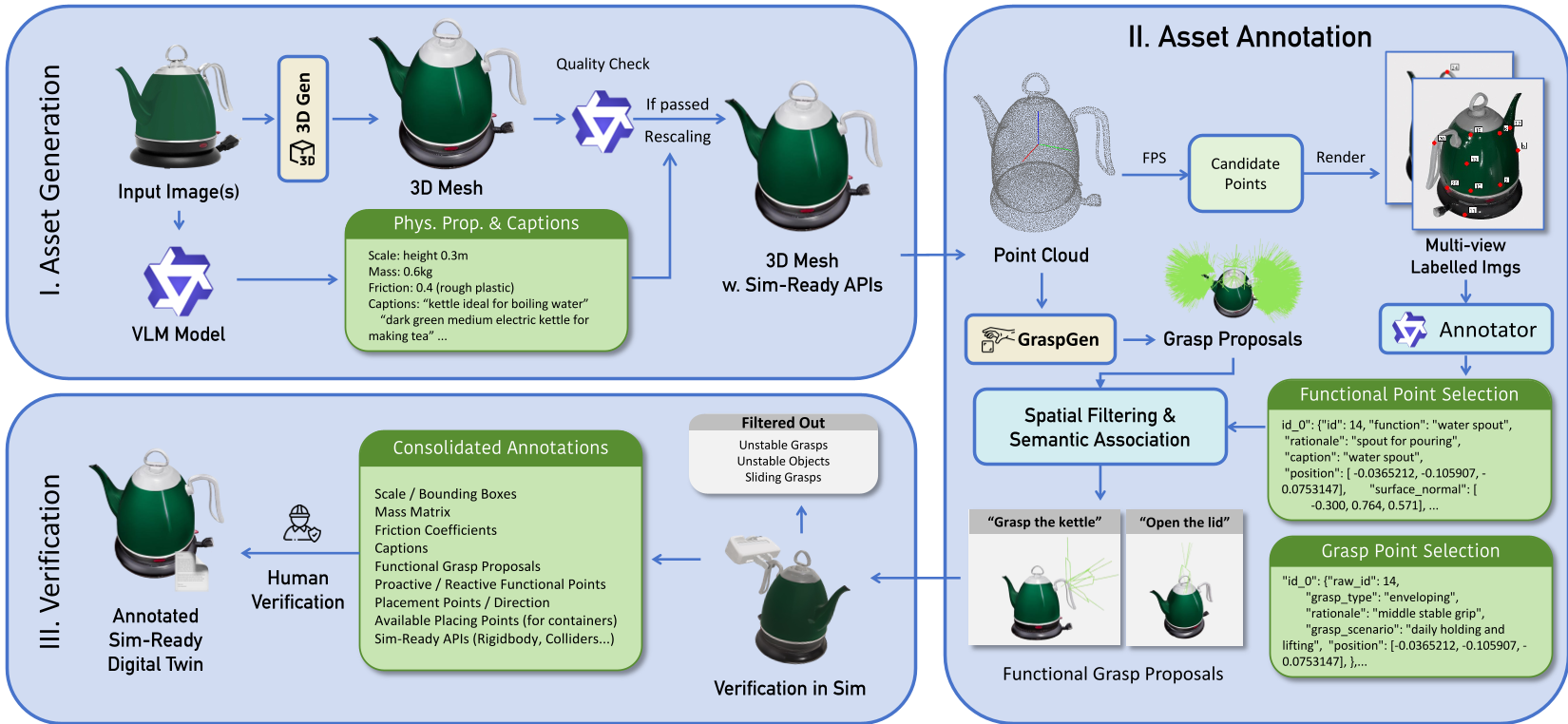
3. Rigorous Physics Verification
This is the "Secret Sauce." Every single grasp proposal is tested in the SAPIEN simulator (PhysX). A virtual robot tries to pick up the object, lift it, and move it. If the object slips or the mesh causes a collision explosion, the grasp is discarded.
Experiments & Results: Quality at Scale
ManiTwin-100K isn't just big; it's precise. The authors generated over 10 million grasp trajectories.
| Statistic | Value | | :--- | :--- | | Total Objects | 100,000 | | Verified 6-DoF Grasps | 5,000,000+ | | Interaction Categories | 512 | | Avg. Verification Success | 76.13% |
Human evaluators found that the VLM's ability to classify categories was 100% accurate, and it correctly identified functional points 92.2% of the time. This suggests that LLM/VLM reasoning is now robust enough to act as an automated "Lab Assistant" for dataset creation.
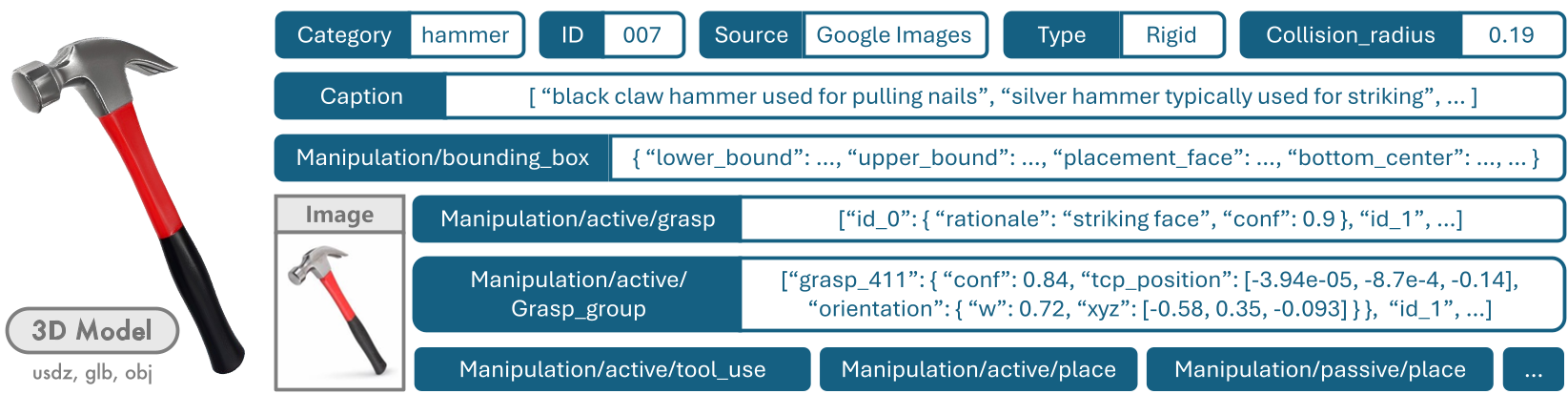
Deep Insight: Beyond "Pick and Place"
The most exciting aspect of ManiTwin is its support for Functional Manipulation. Because the dataset knows where the "spout" of a kettle is, researchers can automatically generate data for complex tasks like "pouring water" or "using a tool."
By providing collision_radius and placement_orientation for every object, the dataset also enables "Scene Layout Generation." You can programmatically scatter 100,000 different types of clutter on a table to train a robot to work in messy, real-world kitchens.
Critical Analysis & Future Work
Strengths:
- Unprecedented Scale: 100K objects is a massive leap from previous robotics datasets.
- Multi-Modal: Integrates language, 2D images, 3D meshes, and 6-DoF actions.
- Physics-Grounded: The simulation verification ensures the data isn't just "visual hallucinations."
Limitations:
- Rigid Only: The current version doesn't handle articulated objects (like opening a drawer) or deformable ones (like folding a towel).
- VLM Bias: Physical properties are "estimates." While 92% accurate by human standards, they might still differ from real-world ground truth (e.g., a hollow ceramic vase vs. a solid one).
Conclusion
ManiTwin-100K is a foundational contribution to the "Robot Scaling Law" era. By turning the infinite web of images into simulation-ready assets, it provides the "internet-scale" data diet required for the next generation of generalist robotic policies (VLA models).
