本文提出了 MARBLE,一种用于扩散模型强化学习(RL)微调的多奖励平衡框架。通过梯度空间优化(Gradient-space Optimization)解决了多维度评估指标下的冲突问题,在 SD3.5 Medium 上实现了五个奖励维度的同步提升。
TL;DR
在将扩散模型(Diffusion Models)与人类偏好对齐时,我们往往面临审美、图文匹配、OCR 准确性等多个维度的考量。传统的“加权求和”奖励法常导致顾此失彼。MARBLE 提出了一种创新的梯度空间平衡框架,通过独立优势估计和摊销梯度协调,在不增加训练负担的情况下,实现了多个奖励指标的同步 SOTA。
痛点深挖:为什么加权求和会失效?
在学术界和工业界,最常见的做法是将多个奖励函数(Reward Models)加权合并为一个标量:。然而,作者通过深入分析发现,这种做法存在**“专家级样本(Specialist Sample)”**问题:
- 样本偏差:一张猫的照片对 OCR(文字识别)奖励毫无贡献,但对审美奖励贡献巨大。
- 信号稀释:在标量化后,由于加权计算包含了无关维度的噪声,这种特定领域的有效信号被稀释了。
- 梯度冲突:作者定量研究发现,在 80% 的训练 mini-batches 中,加权求和产生的更新方向竟然与至少一个奖励维度的梯度呈负相关。这意味着,模型在优化 A 的时候,往往在伤害 B。
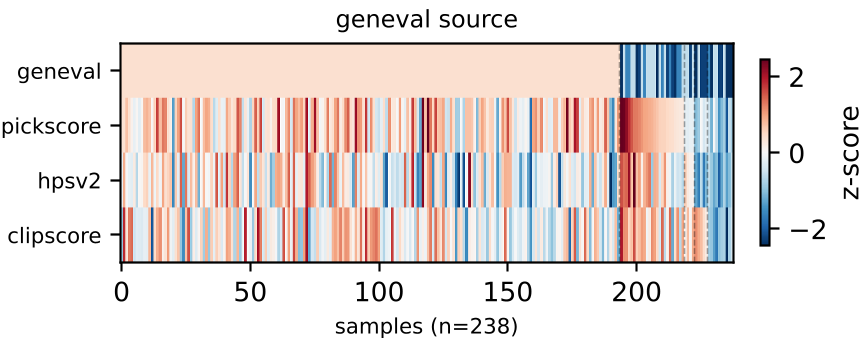 每一列代表一个样本,可见正向奖励高度集中在特定维度,极少有样本能同时在所有维度获得正收益。
每一列代表一个样本,可见正向奖励高度集中在特定维度,极少有样本能同时在所有维度获得正收益。
核心方法:梯度空间的“外交官”
为了解决冲突,MARBLE 并没有在 Loss 层面上硬凑,而是深入到梯度空间进行协调:
1. 独立优势分解(Per-reward Advantage Decomposition)
不再计算一个总的 Advantage。MARBLE 为每个奖励 维护独立的均值和方差,通过 Z-score 归一化计算每个维度的独立优势 。这确保了每个样本只在它真正懂的领域“发言”。
2. 梯度标准化与协调(Harmonization)
由于不同奖励模型的梯度幅值差异巨大,MARBLE 首先将各维度梯度 归一化为单位向量,然后通过求解一个**凸二次规划(Quadratic Programming)**问题来寻找最优更新方向 : 这个公式本质上是在寻找梯度向量凸包中的最小范数点,代表了一个能让所有奖励共同进步的“最大公约数”方向。
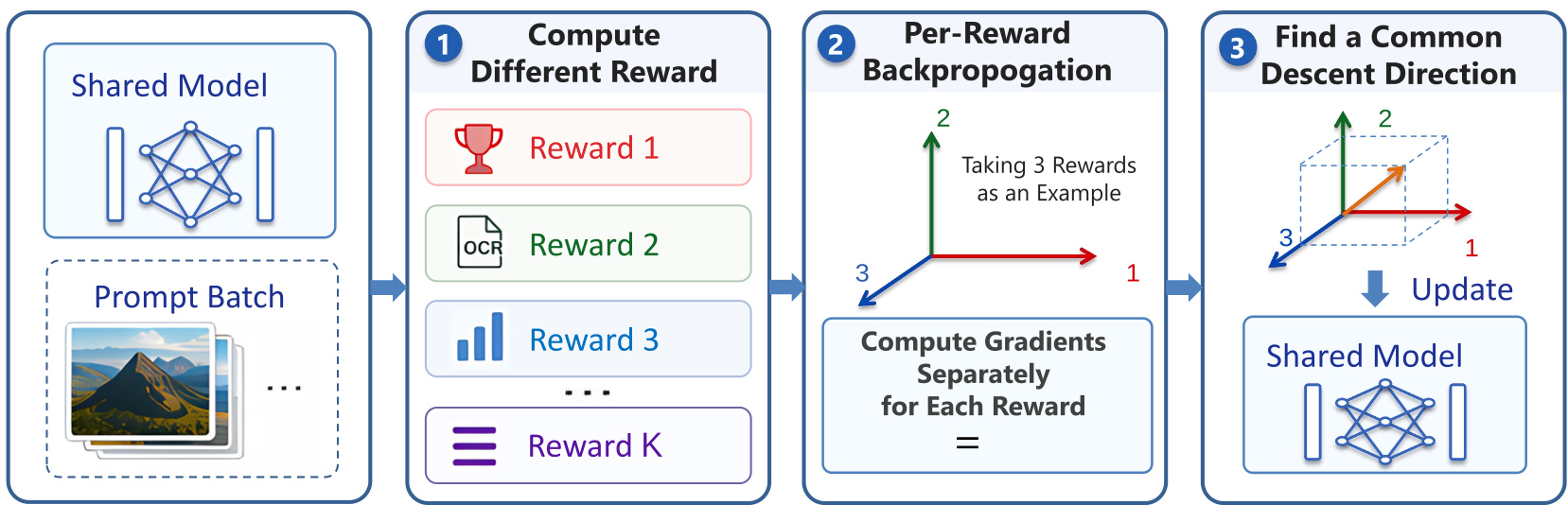
3. 摊销计算与 EMA 平滑:效率的保障
如果每步都要算 次反向传播,效率将难以忍受。作者发现 DiffusionNFT 的损失函数具有仿射结构(Affine Structure),这意味着在一定条件下,多个梯度的凸组合等价于对优势函数进行凸组合后再进行一次反向传播。
- 摊销(Amortization):每 步才进行一次昂贵的梯度协调。
- EMA 平滑:对更新权重 进行指数移动平均,防止单个 mini-batch 的噪声导致某些奖励被瞬时“静音”。
实验战绩:全维度的胜利
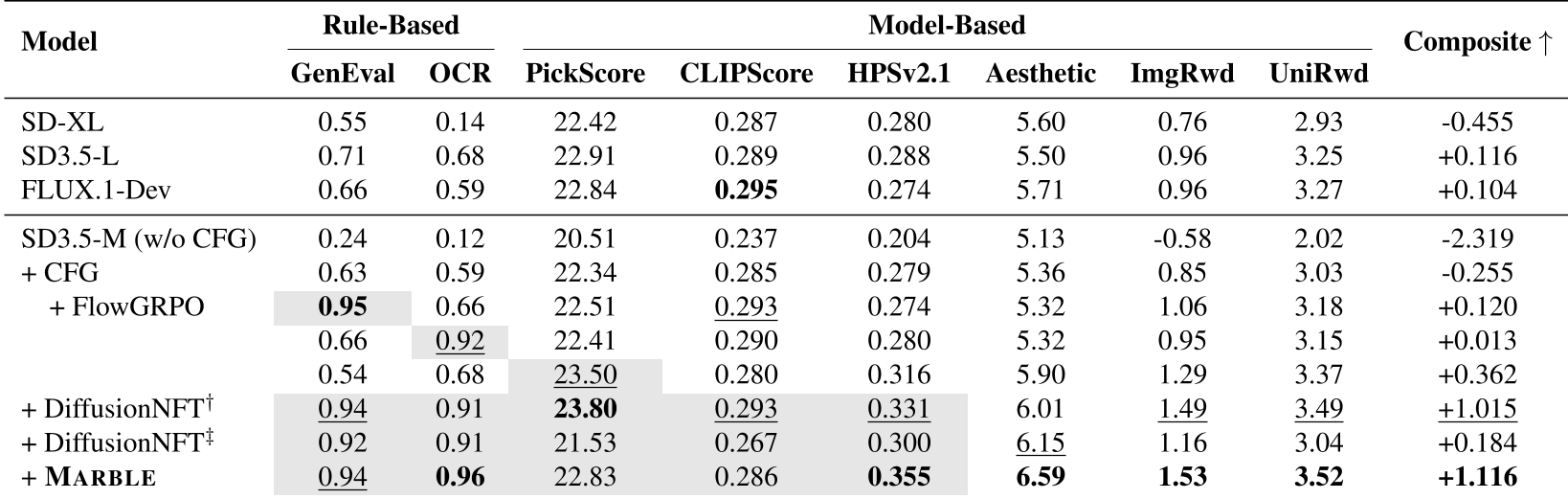
在 SD3.5 Medium 的实验中,MARBLE 展现了强大的统治力:
- 性能提升:在 OCR、GenEval、审美得分等所有 5 个训练维度和 4 个测试维度上,MARBLE 均优于加权求和(Simultaneous)和手动设计的顺序微调(Sequential)。
- 运行效率:通过摊销技术,其训练速度(0.97x)几乎等同于最简单的加权求和基线。
- 复合得分(Composite Score):在综合 8 项指标的平均 Z-score 中,MARBLE 显著领先,证明了其平衡不同目标的卓越能力。
总结与洞察
MARBLE 的成功在于其深刻的物理直觉:生成质量是多维度的,对齐过程不应追求单一的标量极值,而应追求梯度空间的和谐。
其局限性在于目前主要验证了图像生成任务。对于视频扩散模型(Video Diffusion),涉及的时间一致性、运动真实感等更复杂的异构维度,MARBLE 的这种梯度协调机制将具有更大的想象空间。
资深主编点评:在 Diffusion RL 领域,大部分工作还在卷单奖励 SOTA 时,MARBLE 已经跳转到多奖励协调的“第二战场”。它不仅提供了有力的数学工具,更重要的是揭示了为什么简单的权重组合在模型对齐中是极其低效的。