This work serves as a comprehensive theoretical synthesis titled "Mathematical Foundations of Deep Learning," bridging the gap between empirical deep learning success and rigorous mathematical principles. It systematically covers function approximation, optimization theory, optimal control (including Mean-Field Control), Reinforcement Learning (RL), and generative modeling (VAEs, GANs, Diffusion, Flow Matching) through the lens of functional analysis and dynamical systems.
TL;DR
Deep Learning is fundamentally a mathematical enterprise where neural networks act as function approximators, training is non-convex optimization, and sample generation is a controlled trajectory in probability space. This work provides a rigorous roadmap from the Universal Approximation Theorem through Neural ODEs to modern Flow Matching, proving that the "black box" of AI can be cracked using the tools of functional analysis and Hamiltonian dynamics.
Background: Beyond Heuristics
For years, Deep Learning has been criticized as alchemy. We know it works, but "Why?" and "How exactly?" are questions often answered with experimental results rather than mathematical proofs. This work positions itself at the intersection of classical analysis and modern AI, providing the "Unified Field Theory" for neural architectures.
1. The Power of Approximation: How Deep Can We Go?
The journey begins with the Universal Approximation Theorem. While horizontal (shallow) networks can approximate any continuous function, this work emphasizes that depth provides exponential efficiency.
Theoretical Bound
For a function in the Sobolev space , a deep ReLU network requires weights to achieve accuracy . This mathematically formalizes why deep models are essential for high-dimensional data ( is large).
2. Optimization: The Engine of Training
Training is not just "Gradient Descent"; it is navigating a non-convex landscape in a Banach space. The book breaks down the efficiency of Automatic Differentiation (AD), explaining why the Reverse Mode (Back-propagation) is the only viable path for modern models with billions of parameters.
Deterministic to Stochastic
While Newton’s method provides quadratic convergence, its cost is prohibitive. The transition to Stochastic Gradient Descent (SGD) and adaptive optimizers like AdamW and the new Muon (Momentum Orthogonalized by Newton-Schulz) represents a shift from exact optimization to effective "exploration" of the parameter space.
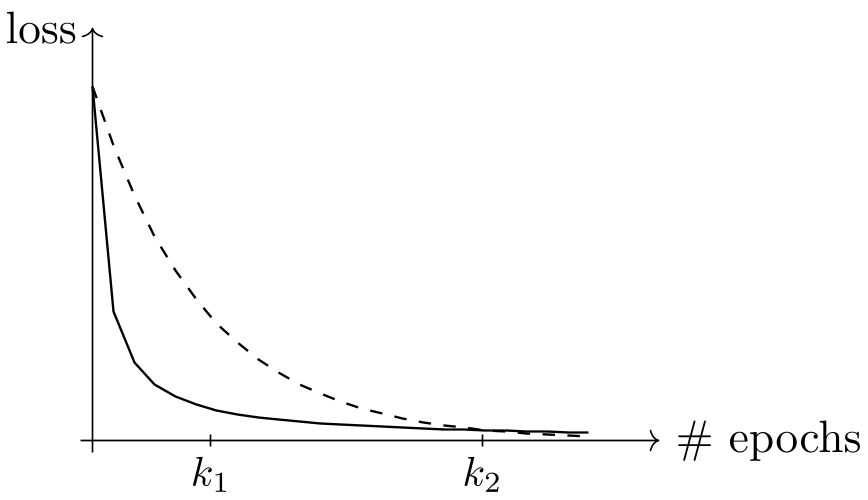 Figure: The tradeoff between linear convergence (Deterministic) and the fast initial progress of sublinear rates (Stochastic).
Figure: The tradeoff between linear convergence (Deterministic) and the fast initial progress of sublinear rates (Stochastic).
3. Deep Optimal Control & Neural ODEs
One of the most profound insights is viewing a Deep Network as a discrete-time dynamical system (ResNet). By taking the limit as layers go to infinity, we arrive at Neural ODEs:
The Adjoint Method
Training a Neural ODE doesn't require storing intermediate activations. Instead, we solve the Adjoint Equation: This allows for constant memory cost, a massive breakthrough for training extremely deep representations.
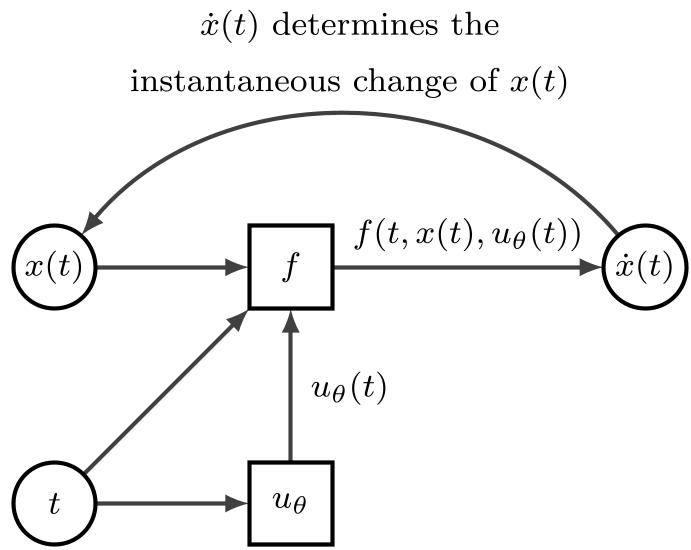 Figure: The state x is steered by a control network uθ toward a terminal reward.
Figure: The state x is steered by a control network uθ toward a terminal reward.
4. Generative Models: Mapping Densities
The book culminates in generative modeling, reframing Diffusion Models and Flow Matching as problems of Probability Density Control.
The Intuition of Flow Matching
Instead of following a messy SDE (Stochastic Differential Equation), Flow Matching learns a deterministic vector field that pushes a standard Gaussian toward the data distribution along straight-line paths: This allows for faster, more stable sampling than traditional Diffusion.
 Figure: The continuity equation approach to transforming probability densities.
Figure: The continuity equation approach to transforming probability densities.
Critical Analysis & Conclusion
Takeaway
The unification of Optimal Control and Generative Modeling is the future of AI. By treating learning as a flow, we can apply centuries of control theory to make models more robust and interoperable.
Limitations
- The Gap: Theoretical network sizes are still much larger than those found in empirical practice (e.g., LLMs work better than theory suggests they should).
- Curse of Dimensionality: While Monte Carlo methods help, high-dimensional PDEs still face extreme variance in gradient estimation.
Future Work
The next frontier is Mean-Field Control—controlling a massive number of agents (parameters/neurons) as a continuous fluid rather than discrete particles. This work paves the mathematical road for that transition.