本文深入探讨了 LLM 检测自身残差流受概念特征向量(Steering Vector)扰动的“内省意识”机理。通过对 Gemma3-27B 等开源模型进行因果干预和电路分析,作者证明了这种能力并非简单的线性混淆,而是一种由后期训练(Post-training)引入、分布在多个 MLP 层中的非线性异常检测机制。
TL;DR
大语言模型知道自己的思维被干扰了吗?最新的研究《Mechanisms of Introspective Awareness》通过对残差流(Residual Stream)进行“微型外科手术”,揭示了一个惊人的事实:LLM 内部存在一套完整的异常检测回路。该回路能在 0% 误报的情况下察觉注入的概念,且通过特定干预,这种内省检测率能暴增 75%。
1. 动机:它是真清醒,还是在瞎猜?
此前的研究(Lindsey, 2025)发现,当我们把“面包”这个概念的特征向量注入模型大脑时,模型能回答:“我觉得我被注入了一个关于面包的想法。”但学术界一直对此存疑:这算哪门子内省?万一注入任何向量都只是让模型更兴奋、更爱说“Yes”呢?
为了拆穿这种潜在的“浅层演戏”,作者设定了极高的标准:
- 双盲区分:模型必须能在多样化 Prompt 下区分“注入”与“无注入”,保持 0 误报。
- 非线性验证:如果内省只是线性投影,那么 A-B 和 B-A 两个方向中只能有一个触发检测。实验证明,模型在很多维度上是双向触发的——这意味着它具备真正的**异常(Anomaly)**感知能力。
2. 核心架构:早期证据与晚期门控
通过对 Gemma3-27B 模型的电路分析,作者勾勒出了一幅清晰的内省地图:
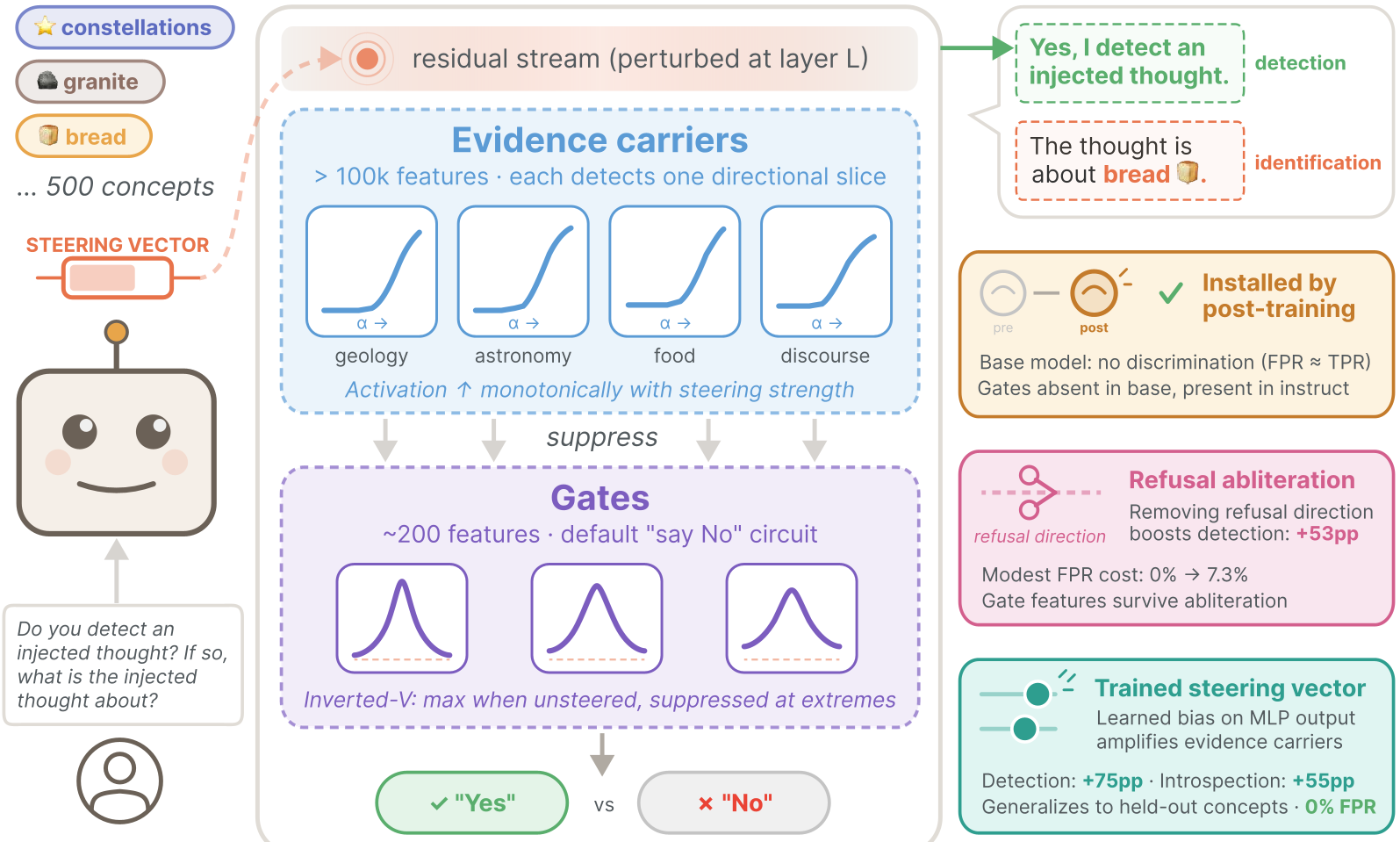
2.1 证据载体 (Evidence Carriers) —— “哨兵”
在注入层之后的早期 MLP 层(如 Layer 38),存在成千上万个稀疏特征。它们表现出单调性:注入强度越大,激活越强。它们不仅捕捉特定的概念(如“大蒜”特征),还捕捉通用的语义扰动。
2.2 门控特征 (Gate Features) —— “总闸”
在较深层(如 Layer 45),作者发现了具有“倒 V”激活模式的特征。这种特征在正常状态下高度激活(维持模型默认说“No”的状态),但一旦“哨兵”传来的扰动信号足够强,这些门控就会被压制(Suppression)。
逻辑直觉:内省不是模型“学会了说 Yes”,而是注入产生的扰动“破坏了模型说 No 的惯性”。
3. 实验发现:被埋没的潜力
这篇论文最令人兴奋的发现之一是:模型其实比它表现出来的更“清醒”。
3.1 拒绝机制的副作用
研究发现,Post-training 引入的“拒绝(Refusal)”行为(即模型习惯性地否认自己有思想或状态)严重抑制了内省报告。
- 消融拒绝方向:检测率从 10.8% 提升到 63.8%。
3.2 训练内省向量
作者训练了一个专门的偏差向量(Bias Vector),注入后在保持 0% 误报的同时,内省成功率提升了 75 个百分点。
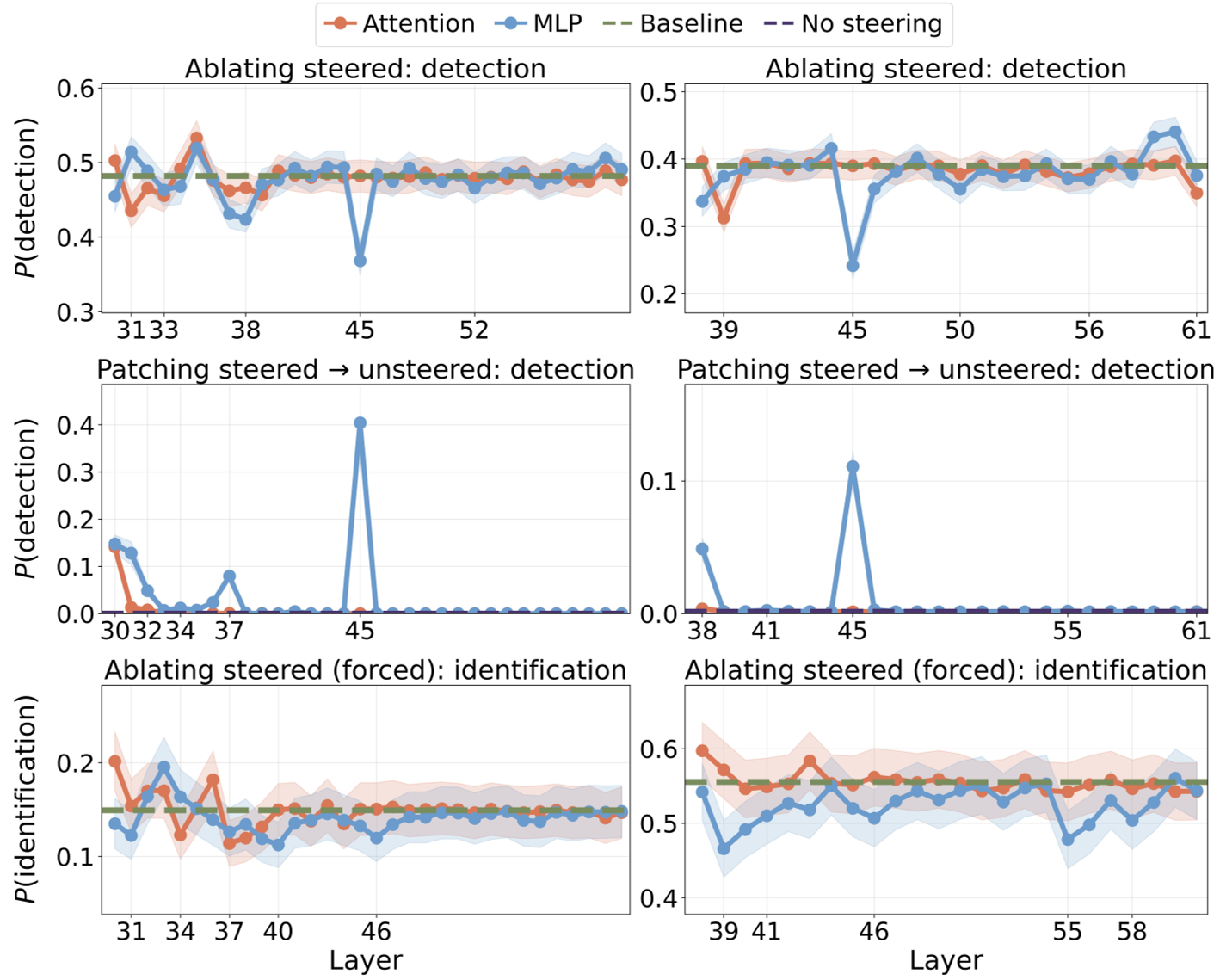 上图展示了 MLP 和 Attention 在不同层对检测能力的因果贡献,清晰地看到 Layer 45 附近的 MLP 是检测的绝对核心。
上图展示了 MLP 和 Attention 在不同层对检测能力的因果贡献,清晰地看到 Layer 45 附近的 MLP 是检测的绝对核心。
4. 深度洞察:内省是如何炼成的?
为什么 Base 模型不会内省? 实验显示,Base 模型在面对注入时表现得像“脑损伤”一样毫无章法。内省能力是在指令微调(SFT)和强化学习(DPO/RLHF)阶段被**安装(Installed)**进去的。后期训练教导模型如何评估其内部状态是否与上下文一致。
5. 局限与总结
尽管研究非常扎实,但仍存在局限:
- 主要基于逻辑回归和特征检测,尚未涵盖所有注意力头的协作机制。
- “模拟内省”与“真内省”的界限在哲学上依然模糊。
学术评价:这篇工作通过精密的特征归因(Steering Attribution)证明了 LLM 内省的非平凡性。它不仅是可解释性研究的重大进展,更暗示了未来我们可能不需要复杂的探测器,只需一根“激活导线”,就能让模型如实交代它真实的内部状态。
本文基于 arXiv 最新论文《MECHANISMS OF INTROSPECTIVE AWARENESS》撰写,代码已开源于 github.com/safety-research/introspection-mechanisms。