本文对生成式机器人策略中的 Sim-and-Real 共同训练(Co-Training)机制进行了系统性机理分析。研究提出了“结构化表示对齐”(Structured Representation Alignment)和“重要性重采样效应”(Importance Reweighting Effect)两大核心机制,并据此设计了 CFG-ADDA 算法,在复杂的机器人操纵任务中实现了 SOTA 性能。
TL;DR
在机器人学术界,为了解决真机数据稀缺问题,将大量模拟数据(Sim)与少量真实数据(Real)混合训练(Co-training)已成标配。然而,为什么简单的混合能奏效?本文通过理论与实验证明:有效的共同训练取决于“结构化表示对齐”——即在抹除领域差异进行知识迁移的同时,必须保留足够的“领域可辨别性”以进行动作适配。 基于此,作者提出的 CFG-ADDA 方案在性能上实现了 20% 的跨越式提升。
1. 核心矛盾:对齐还是区分?
以往的研究者往往陷入两个极端:要么通过 Optimal Transport (OT) 或强判别器让模型彻底分不清 Sim 和 Real(Overlap 模式),导致模型在真机上“生搬硬套”模拟器的动作;要么任由两者在特征空间内保持独立(Disjoint 模式),导致模拟器的知识无法迁移。
本文通过对扩散策略(Diffusion Policy)的最佳得分函数进行数学拆解,指出最优状态是 Structured Aligned:特征在全局结构上对齐,但在局部仍可被区分。
2. 两大关键效应
作者通过一个巧妙的 Toy Model 实验(见下图),揭示了影响性能的两个变量:
- 结构化表示对齐(一级效应):决定了模型能否从源域(Sim)学习任务逻辑,并将其平顺地映射到目标域(Real)。
- 重要性重采样效应(二级效应):由数据混合比例 驱动,起到局部调节作用,像一个“微调拨盘”。
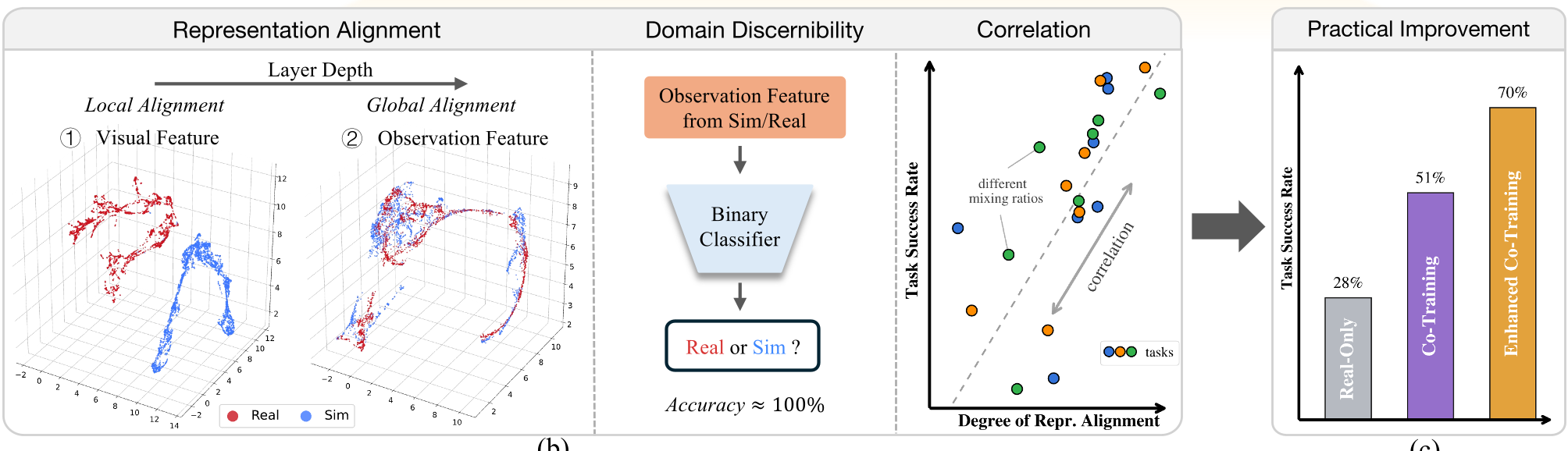 图 1:(a) 共同训练工作流;(b) 浅层局部对齐与深层全局对齐的演化过程。
图 1:(a) 共同训练工作流;(b) 浅层局部对齐与深层全局对齐的演化过程。
3. 为什么 如此重要?一个科学的选择指南
很多开发者在设置数据混合比 时依赖直觉。本文通过对 (真机数据量)和 (模拟数据量)的比例分析,给出了标准建议:
- 自然混合比 (Natural Ratio) 是搜索的下限。
- 平衡混合比 (Balanced Ratio) 通常位于 区间内。
- 实验证明,在这个区间内,模型最能自发形成“结构化对齐”。
4. 进化版方法:CFG-ADDA
基于上述洞察,作者提出了一种“既要对齐,又要区分”的组合策略:
- CFG (Classifier-Free Guidance):将领域标签作为输入。训练时以一定概率丢弃标签。这使得模型在推理时可以通过调整引导尺度 (推荐 ),主动从模拟域“提取”知识。
- ADDA (Adversarial Adaptation):在特征编码器后接一个对抗判别器,强制模型学习领域不敏感的特征,但仅限于非标签维度的空间。
 表 1:CFG-ADDA 在多项任务中均显著优于传统方法。
表 1:CFG-ADDA 在多项任务中均显著优于传统方法。
5. 深度观察:隐形的辨别力
令人惊讶的一点是,即使在 UMAP 图上看起来 Sim 和 Real 的特征已经完全重叠(图 6),使用一个简单的 2 层 MLP 仍然能以 ~100% 的准确率区分领域。这证明了:模型内部保留了极微小但关键的领域差异信号,这正是动作能够从模拟环境适配到现实物理特性的基础。
6. 总结与启示
这项研究为机器人策略训练提供了清晰的路线图:
- 不要盲目对齐:过度追求领域不变性可能导致“负迁移”。
- 利用负向引导:在推理阶段使用负向的 CFG 尺度,可以反向利用模拟数据中的先验知识,这在长程操纵(如 MugCleanup)中尤为有效。
- 架构稳健性:该机制在 CNN-based Unet 和 Transformer 等不同架构下均表现一致。
未来,这一理论有望扩展到跨机器人形态(Cross-embodiment)的训练中,为构建真正的机器人通用基础模型提供理论基石。