本文提出了 MemCam,一种用于一致性交互式波视频生成的记忆增强型框架。通过将历史帧视为外部 Memory 并引入基于共视性(Co-visibility)的上下文检索与压缩机制,该方法在保持长视频场景一致性方面取得了 SOTA 成就,特别是在大角度摄像机旋转任务中表现卓越。
TL;DR
在视频生成领域,如何让模型在“回头看”时记住之前的场景一直是个难题。MemCam 通过引入一个外部记忆模块和上下文压缩技术,让模型能够根据当前相机的视场(FOV)动态检索最相关的历史帧。在 360° 环绕旋转等极端场景下,MemCam 成功消除了内容漂移,不仅画质更稳(FVD 大幅领先),推理效率还提升了 5 倍。
核心定位
MemCam 属于交互式视频生成(Interactive Video Generation)领域的突破性工作。它解决了 Diffusion Transformer (DiT) 在处理长序列时,因注意力机制计算成本随长度平方增长而导致的“短视”问题。它在学术坐标系中处于结构化记忆增强的位置,既避免了复杂的 3D 重构,又超越了简单的固定窗口滑动方法。
痛点深挖:为什么视频生成总是“健忘”?
当前的 SOTA 模型(如 CameraCtrl 或 DFoT)在生成短视频时表现尚可,但在长视频生成中,往往面临以下局限:
- 感受野受限:模型只能看到最近的几帧,当摄像机旋转 180° 再转回来时,模型早已忘记了起点的样子。
- 计算开销爆炸:如果强行拉长上下文,Attention 的计算量会让推理速度慢到无法忍受。
- 3D 一致性缺失:缺乏几何约束,导致生成的场景在逻辑上无法闭合。
Methodology:MemCam 拓扑架构
MemCam 的核心逻辑在于:不再试图让 Transformer 记住一切,而是给它一个“图书馆”(Memory)和“检索员”(Context Selection)。
1. 基于共视性的上下文选择 (Co-visibility Selection)
为了精准找到最能帮助当前帧生成的历史参考,MemCam 利用相机的旋转矩阵 和平移向量 计算共视性分数。通过蒙特卡洛采样 3D 点,计算两帧之间视场(FOV)的 IoU: 只有那些跟当前镜头“看的是一个地方”的历史帧才会被送入模型。
2. 上下文压缩模块 (Context Compression)
即便是筛选掉无关帧,直接输入多帧原始图像依然太重。MemCam 设计了一个卷积压缩层,将 Context 帧的时间维度保持不变,但对空间维度进行 2 倍下采样,从而将 Token 长度缩减至 1/4,极大缓解了 KV Cache 的压力。
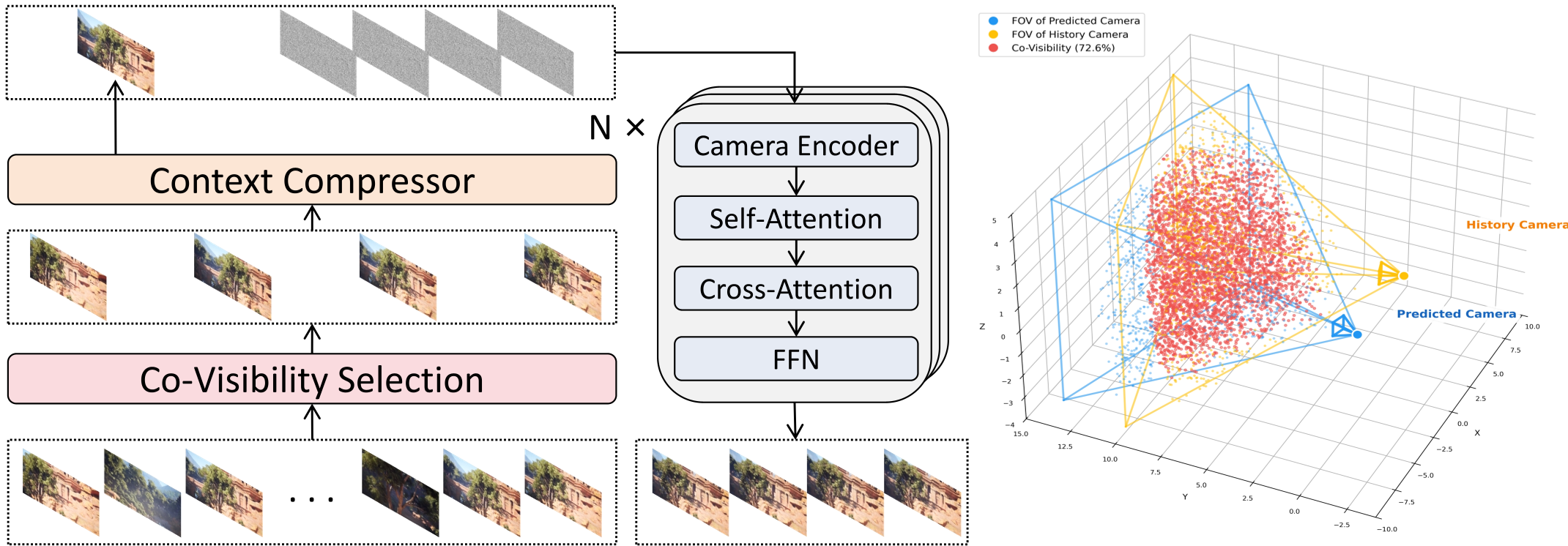 图 1:MemCam 整体架构。左侧展示了压缩后的 Memory 如何与噪声序列拼接,右侧演示了共视性计算逻辑。
图 1:MemCam 整体架构。左侧展示了压缩后的 Memory 如何与噪声序列拼接,右侧演示了共视性计算逻辑。
实验与结果:统治级的长视频一致性
作者设计了一个极具挑战性的实验:360° Round-trip(相机转一圈再转回来)。
- 定量分析:在 360° 任务中,MemCam 的 FVD 指标为 167.87,而基线方法如 DFoT 高达 1188.34。在跨数据集(RealEstate10K)测试中,其 Generalization 能力同样出色。
- 定性分析:从下图中可以明显看到,当相机回到原点时,MemCam 生成的纹理和物体布局与初始帧保持了惊人的一致,而对比方法已经完全产生了幻觉。
 图 2:不同旋转场景下的生成效果。可见 MemCam 在 360° 旋转后依然能完美收拢场景。
图 2:不同旋转场景下的生成效果。可见 MemCam 在 360° 旋转后依然能完美收拢场景。
推理速度的飞跃
通过上下文压缩,MemCam 在使用 76 帧作为 Context 时,推理速度(4.47s/f)比不加压缩的 None-76(22.15s/f)快了近 5 倍,且生成质量几乎没有损失,这为其走向实时交互铺平了道路。
深度洞察与总结
Takeaway: MemCam 的成功告诉我们,视频的一致性本质上是一个检索问题而非简单的生成问题。通过引入相机几何先验(Co-visibility)来引导内容检索,可以在不增加 3D 几何模块的情况下,实现伪 3D 的一致性。
局限性与未来展望:
- 计算效率: 尽管已压缩,但双向 Notice 的开销依然存在。未来可以通过 Diffusion Distillation(模型蒸馏)或更高效的注意力内核进一步提速。
- 数据集规模: 目前主要在特定数据集上验证,未来在万亿级参数大模型(如 Sora 类架构)上的可扩展性值得期待。
MemCam 为实现“无限、连贯、可交互”的数字孪生世界提供了一个切实可行的技术路径。