The paper introduces MEMCOLLAB, a collaborative memory framework for LLM-based agents that enables a single memory system to be shared across heterogeneous models (e.g., Qwen and Llama). It utilizes a contrastive trajectory distillation mechanism to extract agent-agnostic reasoning constraints, achieving SOTA performance in cross-model memory transfer.
TL;DR
MEMCOLLAB introduces a paradigm shift in agentic memory: instead of each agent maintaining its own private diary of experiences, it creates a shared, agent-agnostic library of reasoning constraints. By contrasting how a "strong" agent succeeds where a "weak" agent fails, it distills pure logic that helps any model—regardless of size or architecture—solve complex math and coding tasks more accurately and twice as fast.
The Problem: The "Dialect" of Agent Memory
When we build an LLM agent with memory (like MemGPT or Voyager), the memory usually consists of raw trajectories or summaries of that specific model's past actions. However, models have "dialects"—stylistic biases, specific heuristic shortcuts, and unique failure modes.
The authors discovered a startling "Negative Transfer" effect: If you take the memory generated by a Qwen-32B model and give it to a Qwen-7B model, the 7B model often performs worse than if it had no memory at all. The memory is so entangled with the 32B model's reasoning style that it becomes noise to the 7B model.
The Solution: Learning by Contrast
MEMCOLLAB moves away from "storing what happened" to "distilling why it worked." It treats memory construction as a Contrastive Learning problem.
1. Contrastive Trajectory Analysis
For any given task, the system generates trajectories from two different agents (e.g., a "weak" 7B and a "strong" 32B).
- The Positive ($ au^+$): The successful path.
- The Negative ($ au^-$): The failed path.
By comparing them, MEMCOLLAB extracts a Normative Constraint:
“When dealing with joint probability, enforce explicit case enumeration; avoid assuming independence without verification.”
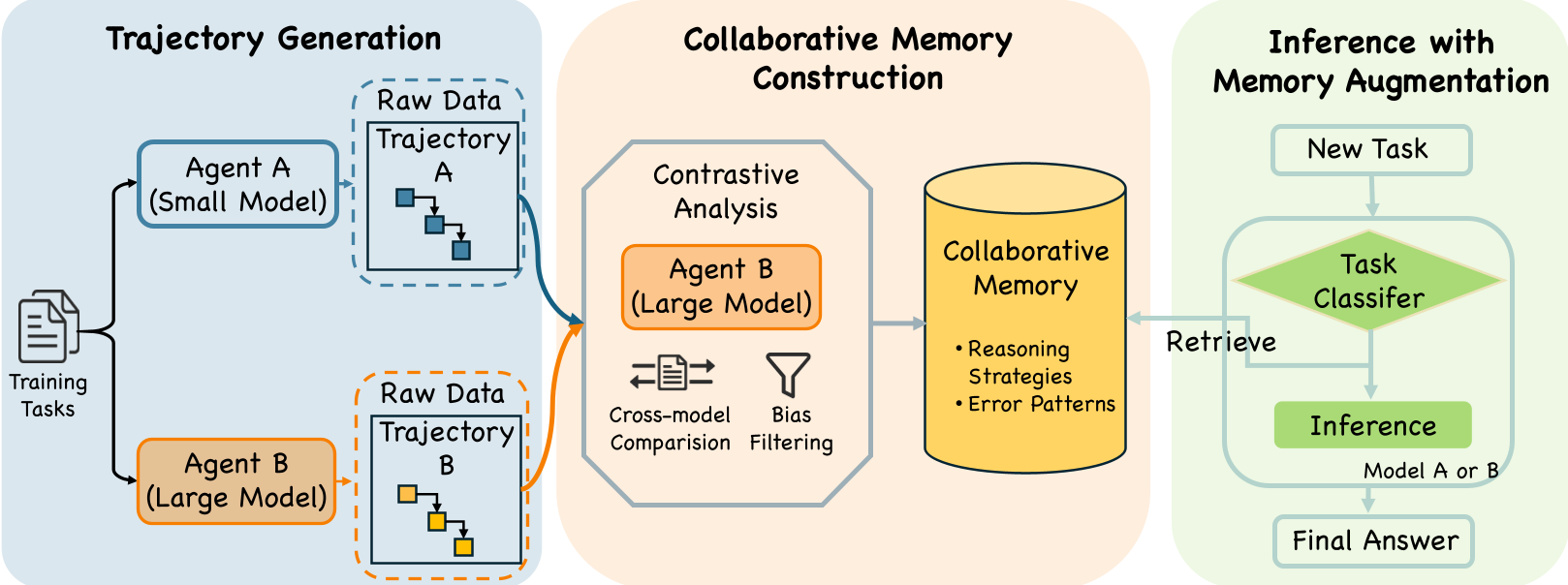 Figure 1: The MEMCOLLAB Workflow—from trajectory pairing to augmented inference.
Figure 1: The MEMCOLLAB Workflow—from trajectory pairing to augmented inference.
2. Task-Aware Routing
To prevent "memory interference" (where geometry hints confuse an algebra solver), the system implements a two-stage retrieval. It first classifies the query (e.g., "Counting & Probability") and then searches for relevant constraints only within that specific "manifold" of tasks.
Experimental Performance: Better, Faster, Universal
The results across MATH500, GSM8K, and HumanEval benchmarks show that MEMCOLLAB doesn't just help weak models—it makes strong models even stronger.
Key Result: Cross-Family Success
The most impressive feat is the Cross-Architecture Transfer. Using a memory bank built by contrasting Qwen-32B and Qwen-7B, a Llama-3-8B model saw its accuracy on MATH500 jump from 27.4% to 42.4%. This proves the memory is truly "agent-agnostic."
 Table 1: Performance gains across different backbone models. Note the significant "Average" improvement for Qwen-7B (+14.5%).
Table 1: Performance gains across different backbone models. Note the significant "Average" improvement for Qwen-7B (+14.5%).
Efficiency: Cutting the Fluff
Beyond accuracy, MEMCOLLAB acts as a "reasoning shortcut." On code generation tasks (MBPP/HumanEval), agents equipped with these constraints reached the correct answer in 50% fewer turns on average. By knowing exactly what pitfalls to avoid (e.g., "avoid using uninitialized variables in loops"), the agent stops wandering in the search space.
The "Why": Pruning the Solution Manifold
The authors provide a fascinating theoretical intuition: if you think of reasoning as a search tree, every "Avoid" constraint in the memory acts as a pruning mechanism. By identifying $k$ erroneous patterns, you exponentially contract the effective search space for the agent. This is why few-shot examples + constraints outperformed raw demonstrations.
Critical Insight & Future Outlook
While MEMCOLLAB is powerful, it currently relies on having a "pair" of agents to generate the initial contrast. Future work could potentially use Self-Contrast (comparing a model's own best vs. worst samples) or scale this to Multi-Agent environments where dozens of models contribute to a "Community Knowledge Base."
Takeaway for Practitioners: If you are deploying a fleet of heterogeneous agents (e.g., a small local model and a large GPT-4o instance), don't give them separate memories. Use a contrastive distillation layer to build a shared "Playbook" that helps the small model punch far above its weight class.