本文提出了 MEMCOLLAB,一个面向大语言模型(LLM)智能体的跨模型共享记忆框架。该方法通过对比不同模型在相同任务上的推理轨迹,提取出“智能体无关”(Agent-agnostic)的抽象推理约束,实现了在异构模型(如 Qwen 与 Llama)间的高效记忆共享。
TL;DR
在多智能体协同的时代,我们是否能让轻量级模型直接复用轻旗舰模型的“经验”?MEMCOLLAB 给出了肯定答案。它通过对比不同模型(如 Qwen2.5-32B 与 7B)在同一题目下的表现差异,洗净了特定模型的“语言怪癖”,提炼出纯粹的逻辑约束。实验证明,这种“跨模型共享记忆”不仅能让小模型超越大模型的原生表现,还能显著降低推理过程中的试错成本。
1. 痛点:为什么“经验”不能直接打包带走?
在 LLM 领域,通常我们会为智能体配备存储过往经验的 Memory。然而,目前的 Memory 存在严重的**“过拟合”性**:
- 推理风格耦合:32B 模型的记忆可能包含其特有的思维分步方式,7B 模型模仿不来,强行模仿反而“走火入魔”。
- 偏差污染:记忆中往往混杂了特定模型的偏好(Bias),导致 naive 的记忆转移(Direct Transfer)效果极差,甚至不如裸机运行。
MEMCOLLAB 的核心直觉在于:真理是通用的,但错误各有各的离奇。通过把“正确的逻辑”和“典型的坑”对比出来,就能得到一份不带偏见的“避坑指南”。
2. 核心机制:对比轨迹蒸馏 (Methodology)
MEMCOLLAB 的工作流分为两个关键阶段:
2.1 轨迹配对与对比提取
系统让两个不同的智能体 (弱)和 (强)去解同一道题。
- 偏好选择:通过检查器筛选出一个正确的轨迹 和一个错误的轨迹 。
- 差异化算子 ():不是简单的文本对比,而是让后台模型分析:“为什么 能成,而 挂了?”
- 生成约束 ():输出格式化的指令——
When [场景], enforce [必须遵循的不变量]; avoid [必须避免的违规模式]。
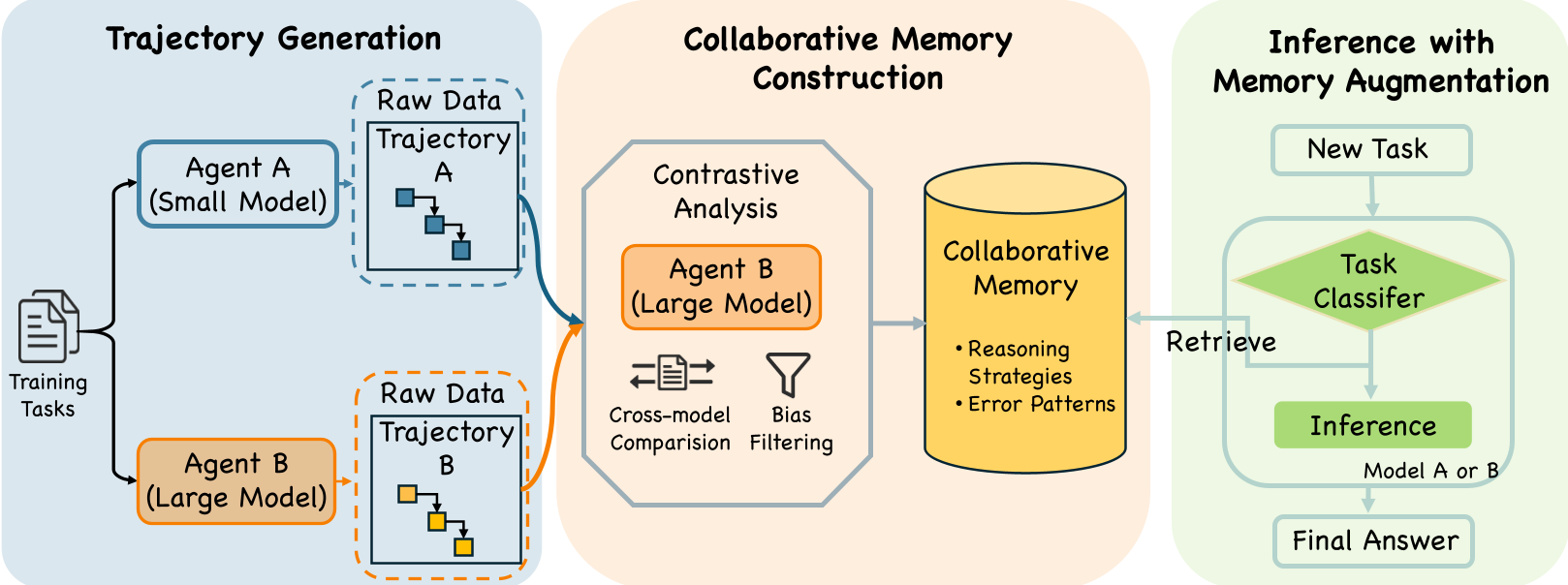 图 1:MEMCOLLAB 框架概览。左侧产生对比对,中间蒸馏记忆,右侧引导推理。
图 1:MEMCOLLAB 框架概览。左侧产生对比对,中间蒸馏记忆,右侧引导推理。
2.2 任务感知的局部检索
为了防止过度检索导致的噪音(Distraction),MEMCOLLAB 加入了一个任务分类器。在检索前,先将任务分类(如:代数、数论、概率)。
- 逻辑:概率题的坑(如遗漏条件概率)和几何题的坑(如辅助线逻辑)完全不同。这种分类过滤极大地提高了检索的
Signal-to-Noise Ratio。
3. 实验战绩:跨模型、跨架构的奇迹
3.1 跨模型家族的兼容性
令人惊讶的是,即使在 Qwen 家族 和 Llama 家族 之间互换记忆,MEMCOLLAB 依然稳健。
| 模型 | 方法 | MATH500 准确率 | HumanEval 准确率 | | :--- | :--- | :--- | :--- | | Qwen2.5-7B | Vanilla (无记忆) | 52.2% | 42.7% | | Qwen2.5-7B | MEMCOLLAB | 67.0% (↑14.8) | 74.4% (↑31.7) |
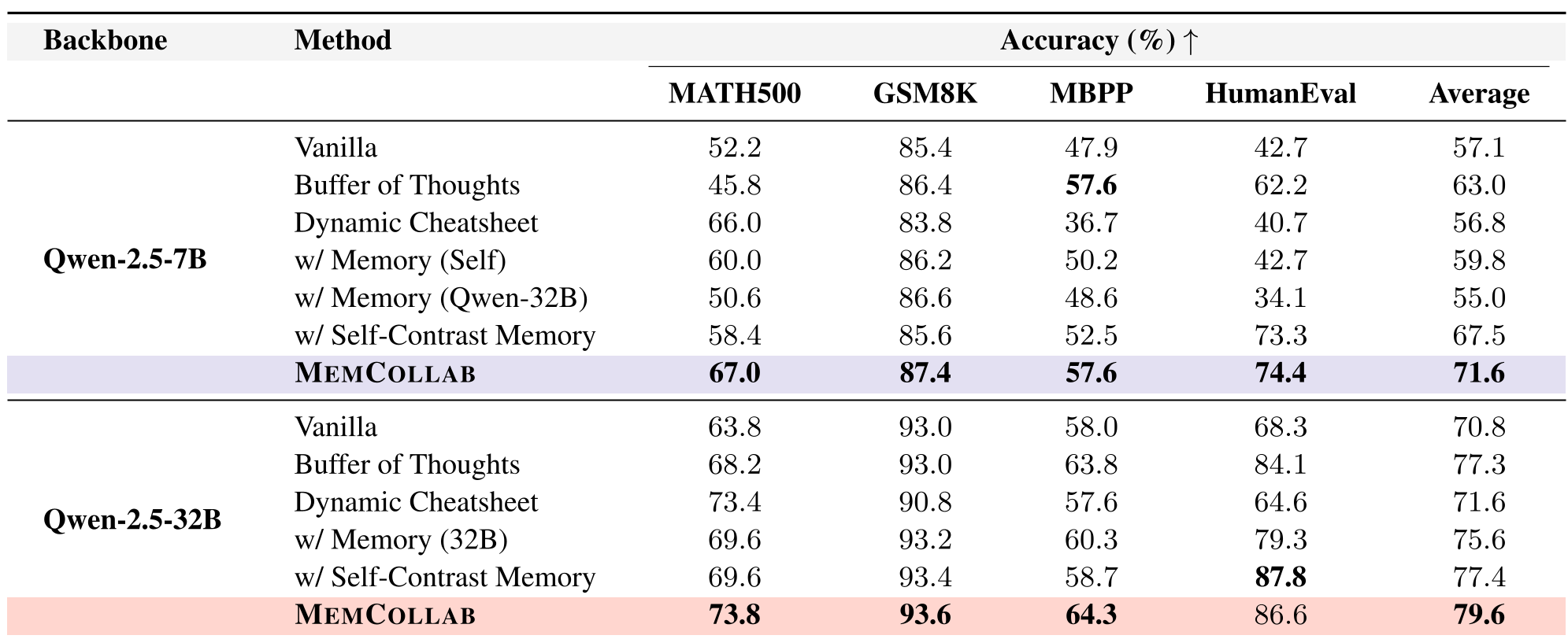 表 1:在同族及跨族模型下的性能对比。可以看到 MEMCOLLAB 显著优于 BoT 和单模型记忆。
表 1:在同族及跨族模型下的性能对比。可以看到 MEMCOLLAB 显著优于 BoT 和单模型记忆。
3.2 推理效率的“降维打击”
记忆不仅增加了准确性,还充当了“加速器”。通过预先告知“哪些坑不能踩”,智能体在推理过程中的自我修正和反复试错显著减少。在 MBPP 代码任务上,推理步数从 3.1 步降低到 1.4 步。
4. 深度洞察:为什么对比能奏效?
作者给出了一个非常精彩的物理解释。假设推理轨迹 ,其中 是任务结构, 是个体偏差。
通过对比学习的 InfoNCE 思想:
- 正样本:成功的轨迹。
- 负样本:同一任务失败的轨迹。 由于同一个任务的 是恒定的,而 在不同智能体间波动,对比操作能够抵消掉 bias 项 ,从而将核心 logic 结构 凸显出来。
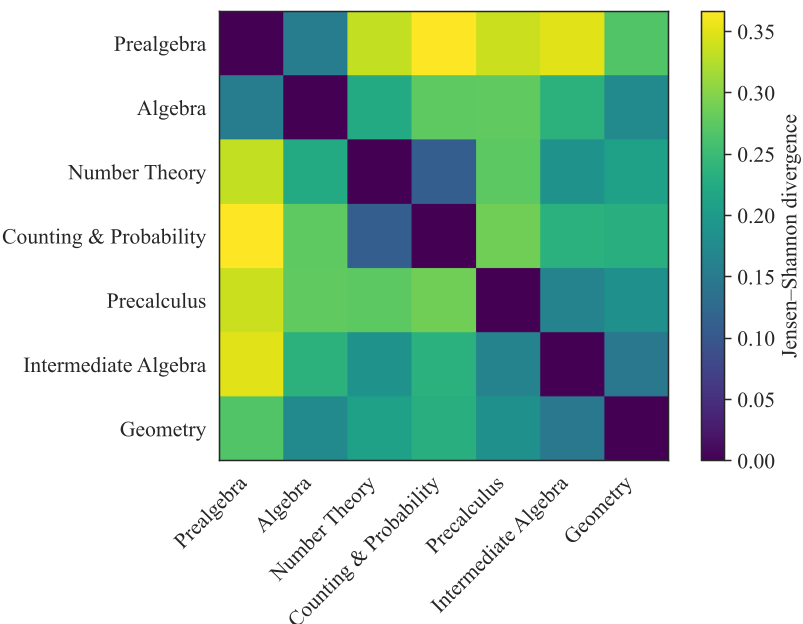 图 2:不同任务类别的错误模式 JSD 散度分析,证明了“分任务检索”的必要性。
图 2:不同任务类别的错误模式 JSD 散度分析,证明了“分任务检索”的必要性。
5. 局限性与未来展望
虽然 MEMCOLLAB 在数学和代码上表现惊艳,但其高度依赖于“高质量的对比对”。如果弱模型和强模型在某个极难任务上都失败了,系统将失效。此外,如何在大规模多智能体网络(Multi-agent Swarm)中动态精简这套记忆库,也是未来值得探索的方向。
总结: MEMCOLLAB 证明了记忆不应该是死板的录像带,而应该是经过对比淬炼后的“方法论”。它为异构模型协同工作、资源受限设备共享云端旗舰模型经验铺平了道路。