MeMix is a training-free, plug-and-play memory update module designed for streaming 3D reconstruction. It recasts recurrent states into a "Memory Mixture," significantly reducing reconstruction completeness error by up to 40.0% on long sequences while maintaining O(1) inference memory.
TL;DR
MeMix is a training-free, plug-and-play module that solves the catastrophic forgetting problem in streaming 3D reconstruction. By partitioning the recurrent state into patches and only updating the least-relevant "Bottom-k" portions, it achieves a 15.3% average reduction in reconstruction error across long sequences (up to 500 frames) while maintaining constant O(1) memory.
The Bottleneck: The Paradox of Fixed States
Streaming 3D reconstruction is the backbone of spatial intelligence for robotics and autonomous driving. Current methods face a "Goldilocks" problem:
- KV-Cache Methods: Store everything, but memory usage grows linearly until the system crashes (OOM).
- Fixed-State Recurrent Models (e.g., CUT3R): Maintain O(1) memory, but suffer from state drift.
The fundamental issue in fixed-state models is that every new frame tries to "write" its information into the same latent tokens. This unconditional full-step write erases historical context, causing the geometry to "melt" or drift as the sequence lengthens.
The Insight: Mixture of Memories (MoM)
The authors propose MeMix, which shifts from "dense" updates to "sparse" routing. Instead of treating the state as a single monolithic block, they treat it as a mixture of independent memory patches.
How MeMix Works (The "Bottom-k" Logic)
The core innovation lies in the selection strategy. At each step:
- The model generates a candidate state () via cross-attention.
- It computes a Routing Score (dot-product similarity) between the state and the current image tokens ().
- Bottom-k Selection: It identifies the patches that are least aligned with the current observation.
- Selective Update: Only these patches are updated; the rest are frozen and preserved exactly.
Why Bottom-k? Updating the most-aligned (Top-k) tokens creates a positive feedback loop where a few tokens do all the work while others go stale. Bottom-k forces the model to distribute information across the entire memory capacity, maximizing diversity and stability.
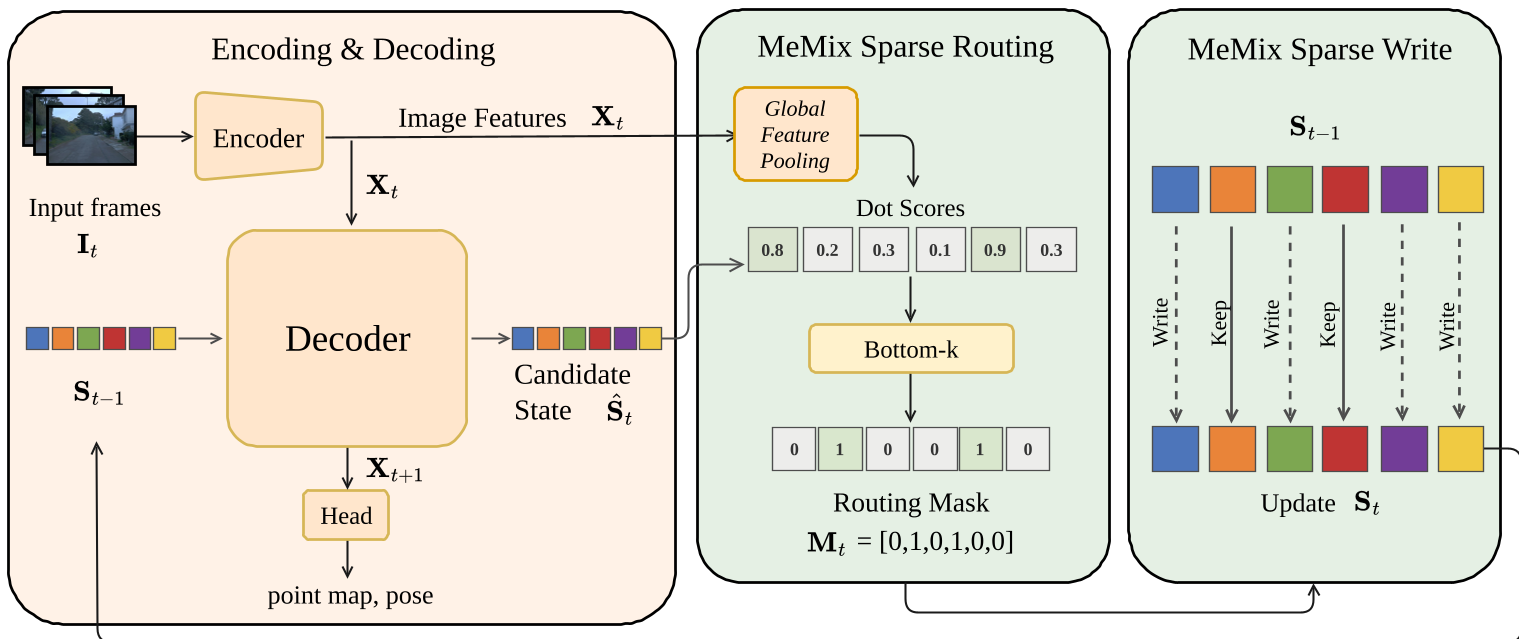 Figure 1: The MeMix pipeline. Sparse binary routing selects specific patches for replacement, preventing global state degradation.
Figure 1: The MeMix pipeline. Sparse binary routing selects specific patches for replacement, preventing global state degradation.
Unified Framework: A Mathematical Synthesis
The paper elegantly shows that most modern streaming models (CUT3R, TTT3R) can be unified under a single gated state update rule:
- CUT3R: (Total overwrite)
- TTT3R: (Dense soft gating)
- MeMix: (Sparse binary routing)
Experimental Results: Precision Over Time
MeMix was tested on standard benchmarks like 7-Scenes and NRGBD.
1. Superior Long-Horizon Stability
While baseline models like CUT3R and TTT3R saw accuracy plummet as the stream approached 500 frames, MeMix variants remained stable. On 7-Scenes, MeMix reduced completeness error by up to 40.0%.
2. Qualitative Sharpness
Visualizations show that without MeMix, surfaces in 3D reconstructions often tear or suffer from "ghosting" effects. MeMix preserves sharper edges and more complete geometric structures by "remembering" the global context more effectively.
 Figure 2: Qualitative results showing how MeMix prevents surface tearing and missing geometry in long-sequence reconstruction.
Figure 2: Qualitative results showing how MeMix prevents surface tearing and missing geometry in long-sequence reconstruction.
3. Efficiency
Despite the added routing logic, the module is extremely lightweight. It maintains ~14 FPS on an RTX 4090, with virtually zero increase in peak GPU memory compared to baseline recurrent models.
Critical Analysis & Outlook
Strengths:
- Plug-and-Play: Can be added to existing SOTA models (CUT3R, TTT3R, TTSA3R) without retraining.
- Physics-Informed Intuition: Recognizing that not all memory needs to be updated at every frame is a biologically plausible and computationally efficient inductive bias.
Limitations:
- Heuristic k: The choice of (708/768 tokens) is determined empirically. Future work could make this parameter dynamic based on scene complexity or motion.
- Kilometer-Scale: While it excels at 500 frames, it hasn't yet been proven on "endless" kilometer-scale autonomous driving streams.
Conclusion
MeMix proves that in the world of recurrent 3D vision, less is more. By strategically refusing to update the entire state, the model preserves its "long-term memory," providing a robust and efficient solution for the next generation of real-time spatial AI.