This paper introduces Memory Transfer Learning (MTL) for coding agents, a paradigm that enables the sharing of experience across heterogeneous task domains. By utilizing a unified memory pool, the authors achieve a 3.7% average performance gain across 6 benchmarks, reaching new SOTA levels for self-evolving agents in complex coding environments.
TL;DR
Researchers from KAIST and NYU have cracked the code on how AI agents can "remember" lessons from one programming domain and apply them to completely different ones. By shifting focus from raw code traces to high-level Insights, their Memory Transfer Learning (MTL) framework boosts performance by up to 8.3%, proving that for AI agents, process is more important than syntax.
Motivation: Why Coding Agents Stay Stuck in Silos
In the current landscape of AI software engineering, we have "specialists." An agent might be great at competitive programming (LiveCodeBench) but fail miserably when asked to fix a real-world GitHub bug (SWE-bench).
The problem isn't a lack of data; it's a Memory Wall. Most agents only learn from their own successes and failures within a single domain. They fail to realize that whether they are writing a sorting algorithm or fixing a Django backend, the "Meta-Knowledge"—things like "always verify with a dry run" or "check file headers before editing"—remains identical.
Methodology: The Abstraction Spectrum
The authors investigated which type of memory transfers best. They categorized memory into four levels of abstraction:
- Trajectory (Low Abstraction): Raw command-level logs.
- Workflow: Extracted sequences of successful actions.
- Summary: Natural language descriptions of why a task succeeded/failed.
- Insight (High Abstraction): Task-agnostic principles for future problem-solving.
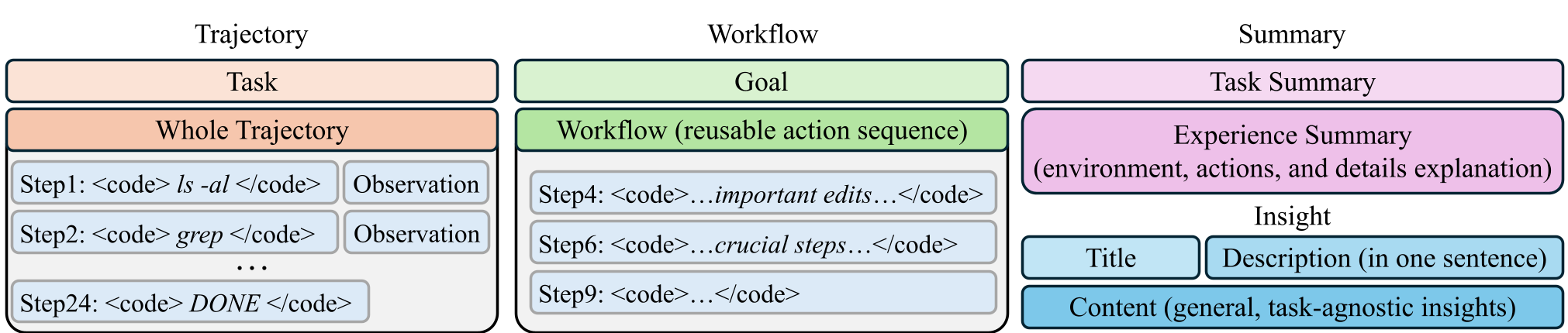 Figure 1: From concrete traces to abstract insights—the hierarchy of memory formats used in the study.
Figure 1: From concrete traces to abstract insights—the hierarchy of memory formats used in the study.
The "Insight" Advantage
The study found a direct correlation between Abstraction and Transferability. Low-level Trajectories often caused "Negative Transfer" because the agent would blindly copy-paste commands (like R-language syntax into a C++ environment). Insights, however, act as behavioral guardrails.
Experimental Battleground: Scaling Beyond Benchmarks
The team tested MTL across 6 heterogeneous benchmarks using models like GPT-5-mini and DeepSeek V3.2.
| Benchmark | Improvement (MTL-Insight) | Key Takeaway | | :--- | :--- | :--- | | SWEBench-Verified | +4.0% | Better repository navigation. | | MLGym-Bench | +8.3% | Improved experimental discipline. | | ReplicationBench | +7.8% | Stronger scientific reasoning. |
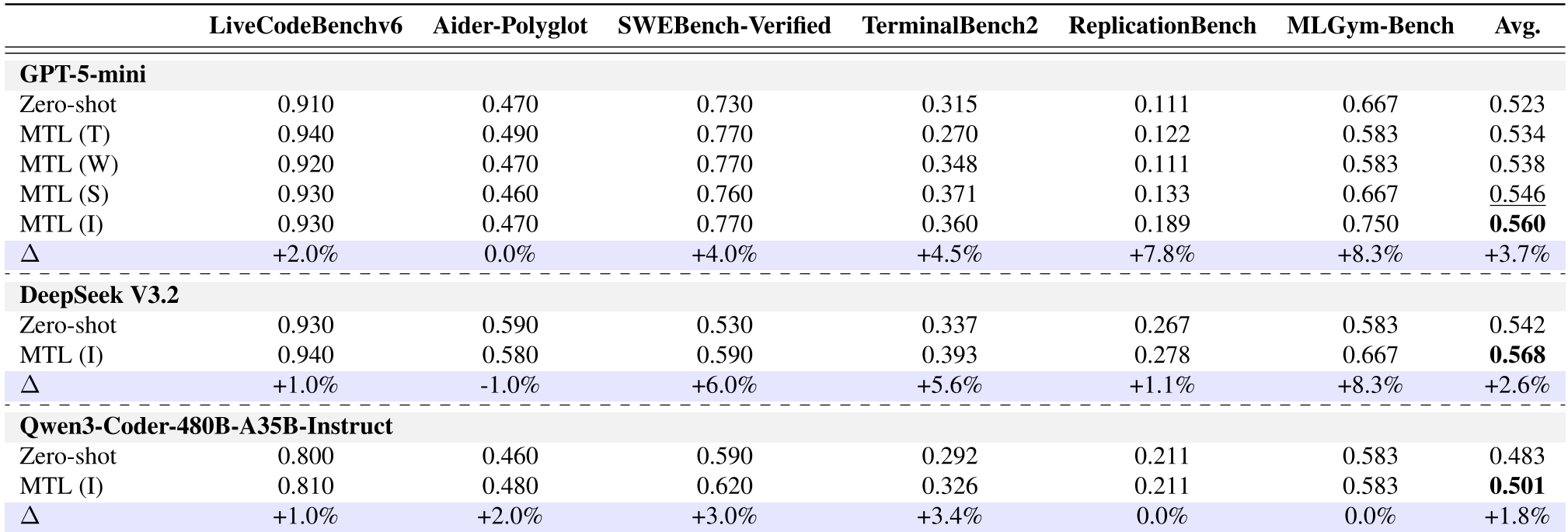 Figure 2: Performance gains across various LLMs. Note the consistent improvement when using high-level Insight transfer.
Figure 2: Performance gains across various LLMs. Note the consistent improvement when using high-level Insight transfer.
Deep Dive: How Memory Actually Helps
Interestingly, only 5.5% of the performance gain came from transferring actual algorithms. The vast majority of the "win" came from Meta-Knowledge, such as:
- Iterative Workflow Discipline: "Edit small, test immediately."
- Anti-Pattern Avoidance: "Don't blindly overwrite files without checking dependencies."
- Environment Adaptation: "How to handle bash vs. sh idiosyncrasies."
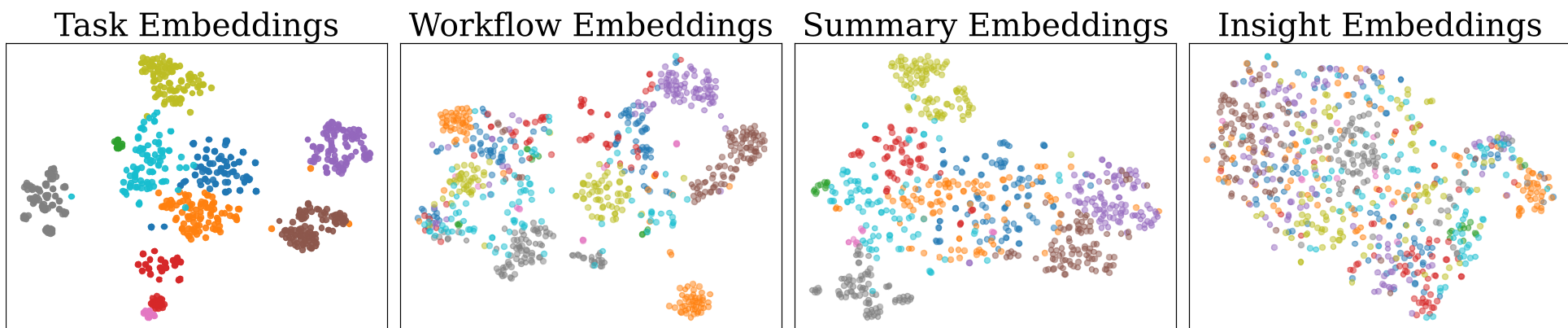 Figure 3: t-SNE visualization showing that Task and Trajectory memories are clustered (siloed), while Insight memories are intermingled (generalized) across all domains.
Figure 3: t-SNE visualization showing that Task and Trajectory memories are clustered (siloed), while Insight memories are intermingled (generalized) across all domains.
Conclusion: A New Blueprint for Self-Evolving Agents
The findings establish three critical design principles:
- Abstraction is King: To transfer knowledge, you must strip away the task-specific "noise."
- Cross-Model Synergy: Memory can be transferred from stronger models (like GPT-5) to weaker ones, serving as a form of "on-the-fly" distillation.
- Scale is Data-Dependent: The effectiveness of MTL scales linearly with the size of the cross-domain memory pool.
The Future: Instead of training massive, domain-specific coding models, we should focus on building tiny, agile agents that share a massive, global "Insight Pool." This paper shows that in the world of AI coding, wisdom is universal.