Meta-TTRL is a metacognitive test-time reinforcement learning framework designed for Unified Multimodal Models (UMMs). It enables self-improvement in text-to-image (T2I) generation by leveraging model-intrinsic monitoring signals, achieving state-of-the-art gains across benchmarks like Janus-Pro-7B and Qwen-Image without external reward models.
TL;DR
Meta-TTRL is a pioneering framework that turns inference time into learning time for Unified Multimodal Models (UMMs). Unlike traditional methods that just "pick the best sample," Meta-TTRL uses the model's own "inner voice" (metacognition) to grade its outputs against a structured rubric and update its parameters on the fly. It achieves massive gains in compositional reasoning (up to 106% improvement) by ensuring that the feedback used for training is perfectly aligned with the model's own internal logic.
The Problem: Ephemeral Gains and Static Models
In the world of Text-to-Image (T2I) generation, we have become experts at "Test-Time Scaling" (TTS). If a model fails to generate "a red cat on a blue cube," we simply sample 100 images and pick the one that looks best using an external reward model.
The catch? The model learns nothing. The moment you ask for "a green dog on a yellow sphere," the model is just as "clueless" as before. It repeats the same failure modes because its weights remain frozen. Furthermore, relying on massive external reward models (like GPT-4V or dedicated CLIP scorers) often introduces a "misalignment" problem—the feedback is either too harsh or too complex for the smaller base model to actually learn from.
Methodology: The Two-Level Metacognitive Architecture
Meta-TTRL moves beyond instance-level fixes to capability-level improvements. It treats the UMM as a dual-entity system inspired by the Nelson-Narens model of metacognition:
- Object Level (The Artist): Responsible for the raw generation of images.
- Meta Level (The Critic): Responsible for monitoring and controlling the artist.
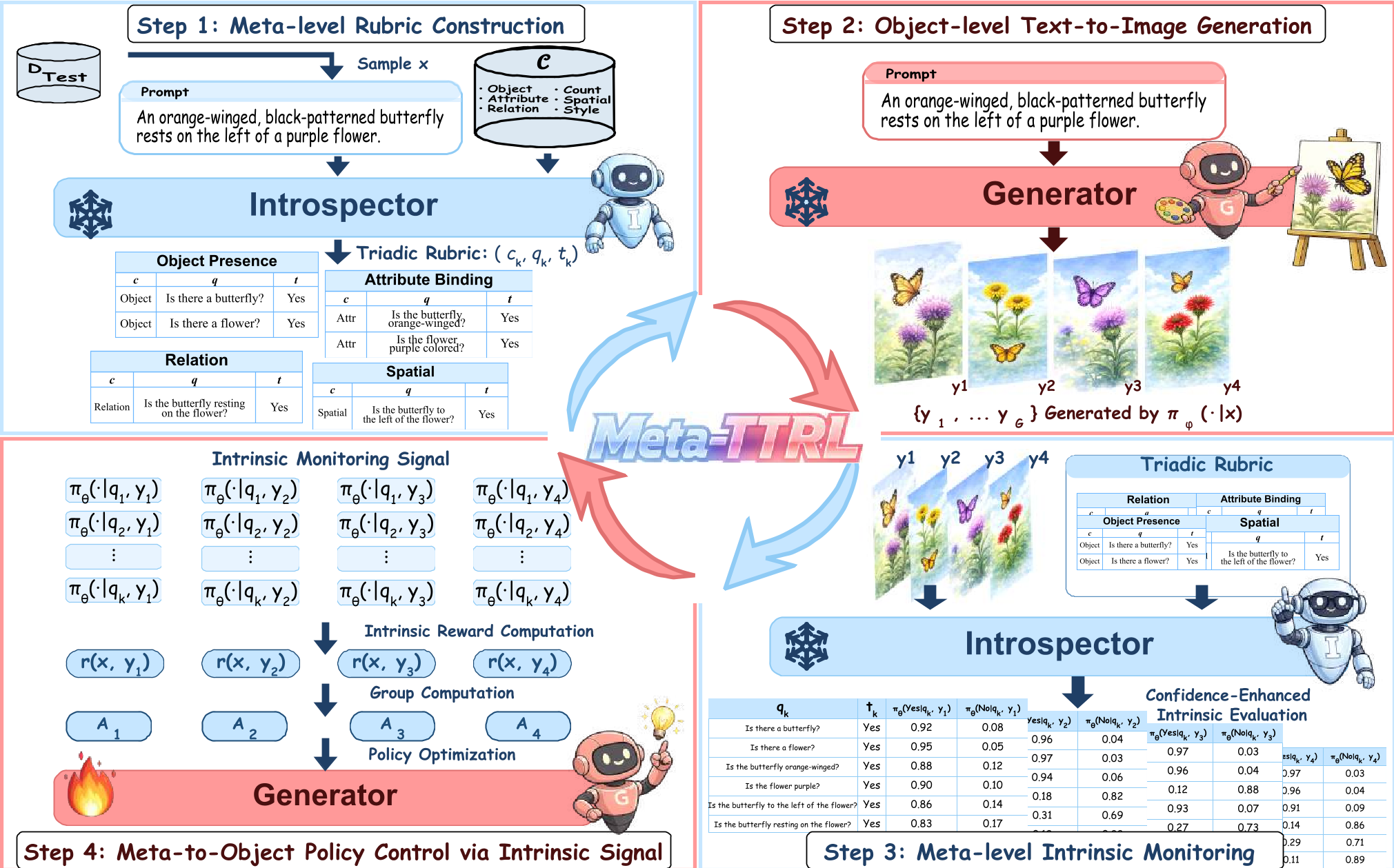
The Monitoring-Control Loop
The process follows a sophisticated four-step loop:
- Rubric Construction: Instead of a vague "is this good?" the model breaks the prompt into specific check-points (e.g., Is the object a cat? Is it red?).
- Generation: The model generates a group of candidate images.
- Intrinsic Monitoring: The model uses its own VQA (Visual Question Answering) capabilities to score its own images against the rubric.
- Policy Control: Using Group Relative Policy Optimization (GRPO), the model updates its weights to favor characteristics of the "winning" candidates in that specific group.
Why It Works: The "Metacognitive Synergy" Insight
One of the most striking findings of the paper is that bigger is not always better. The authors tested using a massive external model (Qwen3-VL-235B) as the critic (E-TTRL) versus the model’s own internal critic.
Surprisingly, the internal critic won.
The authors call this Metacognitive Synergy. When a model evaluates itself, the "reward signals" it generates are within its own "optimization regime." It provides a curriculum that it is actually capable of following. An external "super-model" might provide feedback that is too far beyond the base model’s current grasp, leading to unstable training.
Experimental Triumphs: Compositional Masterclass
The results on Benchmarks like T2I-CompBench++ (which tests complex spatial and attribute relationships) were profound.
| Model | Attribute | Improvement (Δ) | | :--- | :--- | :--- | | Janus-Pro-7B | 2D Spatial | +106.36% | | Janus-Pro-7B | Texture | +67.17% | | BAGEL | 3D Spatial | +15.64% |
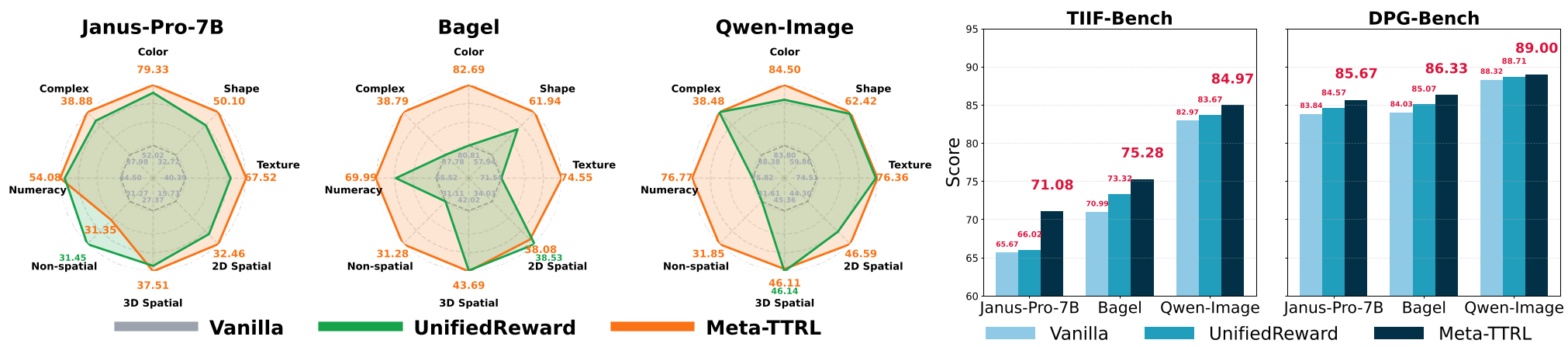
As seen in the radar plots, Meta-TTRL (green line) consistently pushes the boundaries of the base model (grey) across almost every dimension, particularly in spatial reasoning and numeracy—areas where UMMs typically struggle.
Critical Analysis & Conclusion
Meta-TTRL proves that inference isn't just for output—it's for growth. By closing the loop between understanding (introspector) and generation (generator), we create models that actually get smarter the more we use them.
Limitations:
- Resource Intensive: Training at test-time requires gradient updates, which is significantly slower than standard inference.
- White-Box Only: You need access to model weights, making this unusable for "Closed-Source" APIs like DALL-E 3 or Midjourney.
Future Outlook: This work sets the stage for "Continuous Learning" agents. Imagine a model that, after a day of user queries, has fundamentally improved its ability to understand your specific artistic style or complex technical requirements without ever needing a "Version 2.0" release.