The paper introduces BAR (Branch-Adapt-Route), a modular post-training framework that extends language models with new domain capabilities (Math, Code, Tool Use, Safety) by training independent experts and composing them via a Mixture-of-Experts (MoE) architecture. Using a 7B scale model, BAR achieves an overall score of 49.1, matching or exceeding monolithic retraining baselines while enabling independent expert updates.
TL;DR
Training state-of-the-art LLMs usually follows a "monolithic" path: you mix all your data, train once, and if you want to add a new skill (like advanced coding), you often have to retrain everything or risk breaking what already works. BAR (Branch-Adapt-Route) changes the game. It allows developers to train independent "experts" for specific domains (Math, Code, Tool Use) and snap them together using a Mixture-of-Experts (MoE) architecture. The result? Better performance, no catastrophic forgetting, and a linear cost for model upgrades.
The Problem: The Price of Being Monolithic
In the current paradigm, extending a model with a new capability is a nightmare. You face two main enemies:
- Catastrophic Forgetting: If you train a model on Math RL after it has already learned Safety, the math optimization often "overwrites" the safety behaviors.
- Quadratic Scaling of Costs: To keep a model's performance balanced, every time you add a new dataset, you must retrain on the entire combined dataset. As you add more domains, the cost to update the model grows quadratically.
The authors of BAR argue that LLMs should be built like modular software, not like a single, unbreakable block of marble.
Methodology: Branch, Adapt, and Route
BAR follows a three-stage process to transform a dense base model into a multi-expert powerhouse:
1. Independent Expert Training (Branch & Adapt)
Each domain expert (e.g., Math) is initialized from the base model and undergoes its own private training pipeline:
- Mid-training: Deepening domain knowledge.
- Supervised Finetuning (SFT): Learning to follow instructions.
- Reinforcement Learning (RLVR): Fine-tuning for accuracy using verifiable rewards.
Crucial Insight: Unlike pre-training modularity (like FlexOlmo), where shared weights are frozen, BAR identifies that post-training requires "unfreezing" attention and embedding layers. Post-training is about behavior, and behavior lives in the attention patterns and special tokens (like <thinking>).
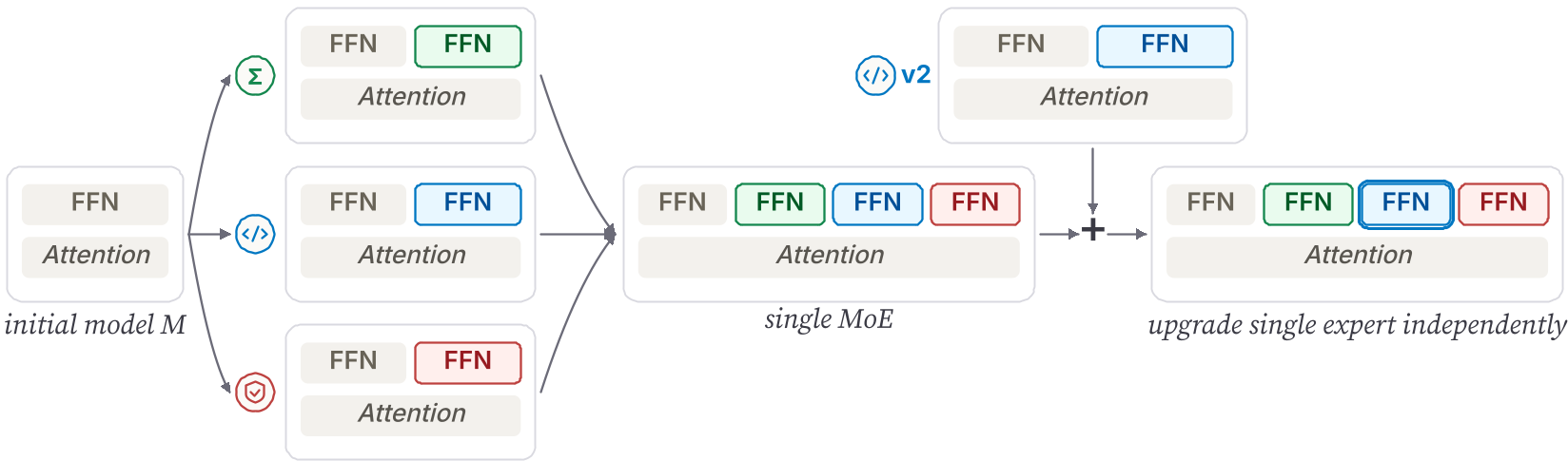
2. Expert Merging
Once the experts are trained, they are combined. Since attention weights might have diverged slightly during independent RL stages, BAR simply averages these shared parameters. Surprisingly, this "weight averaging" causes almost zero performance loss.
3. Router Training
The final step is training a "router"—a lightweight traffic controller that decides which token goes to which expert. This stage is incredibly cheap, requiring only 5% of the original SFT dataset.
Experimental Results: Performance without Compromise
At the 7B scale, BAR was tested against heavy-duty baselines.
- Beating Continual Training: BAR scored 49.1 overall, vs. 45.3 for standard sequential training.
- Isolating Safety: Because the Safety expert was trained in its own branch, its performance remained at 94.0, whereas standard retraining often sees safety scores dip significantly when math and code RL are introduced.
- Linear Upgradability: The team replaced a "Code v1" expert with a "Code v2" expert. The code score jumped by 16.5 points, while every other domain (Math, Safety, Chat) stayed perfectly stable.
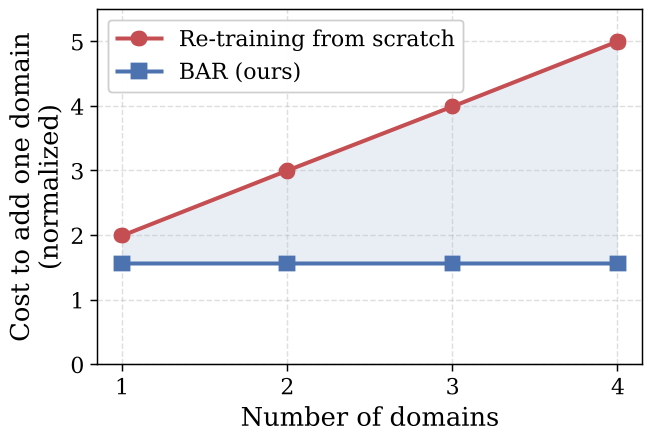 Above: Retraining cost grows with every new domain, while BAR's update cost remains constant.
Above: Retraining cost grows with every new domain, while BAR's update cost remains constant.
Deep Insight: Why Unfreezing Matters
The paper’s most significant contribution to the "Modular Training" literature is the ablation on shared parameters. Previous works suggested freezing everything except the FFN (Feed-Forward Network) layers. BAR proves that for RL and SFT, this is a mistake.
As seen in the experiments, without unfreezing the embedding layer, the "Tool Use" expert couldn't even learn the new tokens needed for function calling. By progressively unfreezing layers during the post-training stages, BAR captures the behavioral nuances that purely FFN-based modularity misses.
Conclusion and Future Outlook
BAR represents a shift toward Scalable, Modular LM Development. It provides a blueprint for teams to work on different model capabilities in parallel without stepping on each other's toes.
Limitations: Currently, total parameters grow as you add experts, which can increase inference costs. Future work on "finer-grained" experts or better sparsity could mitigate this.
For the industry, the message is clear: Stop retraining the whole brain when you only want to learn a new language. Branch it, adapt it, and route it.