This paper introduces MolmoBot, a generalist robotic foundation model series that achieves high-performance zero-shot sim-to-real transfer for static and mobile manipulation. By leveraging a massive synthetic dataset (MolmoBot-Data) of 1.8 million expert trajectories generated via a procedural pipeline (MolmoBot-Engine), the authors demonstrate that diverse simulation data alone can produce robust real-world agents like MolmoBot, which outperforms state-of-the-art models like π0.5.
Executive Summary
The consensus in robot learning has long been that "simulation is just a sandbox"—useful for pretraining, but ultimately limited by an irreducible reality gap. To build truly capable agents, the industry has leaned heavily on massive, expensive, and often proprietary real-world datasets (e.g., NVIDIA's GR00T, PI's π0).
MolmoBot turns this assumption on its head. By scaling simulation to an unprecedented degree—1.8 million trajectories across 94k unique environments—the team from Ai2 and University of Washington demonstrates that zero-shot sim-to-real transfer is not only possible but can outperform the current state-of-the-art (SOTA) models trained on real-world data.
The Core Insight: Diversity Over Photorealism
The authors argue that the bottleneck to general-purpose manipulation isn't the lack of real-world "pixels," but the lack of diversity in interaction. While many researchers chase photorealistic rendering, MolmoBot-Engine focuses on:
- Extensive Domain Randomization: Lighting, friction, mass, and textures are varied wildly.
- Procedural Scene Generation: Utilizing "MolmoSpaces" to create 232k unique layouts.
- Action Noise: Injecting noise into expert planners to force the policy to learn recovery behaviors.
Methodology: The VLA Architecture
MolmoBot is built on the Molmo2-4B vision-language model. The architecture features a unique DiT-based flow-matching action head. Unlike traditional architectures where the action head is a simple MLP at the end of a transformer, MolmoBot uses layer-wise coupling:
- Multi-frame Input: The model ingests up to 3 frames to provide temporal context.
- Cross-Attention: At every layer, the action head attends to the corresponding hidden states of the VLM.
- Action Chunking: It predicts 16 future actions simultaneously, allowing for smooth, high-frequency control.
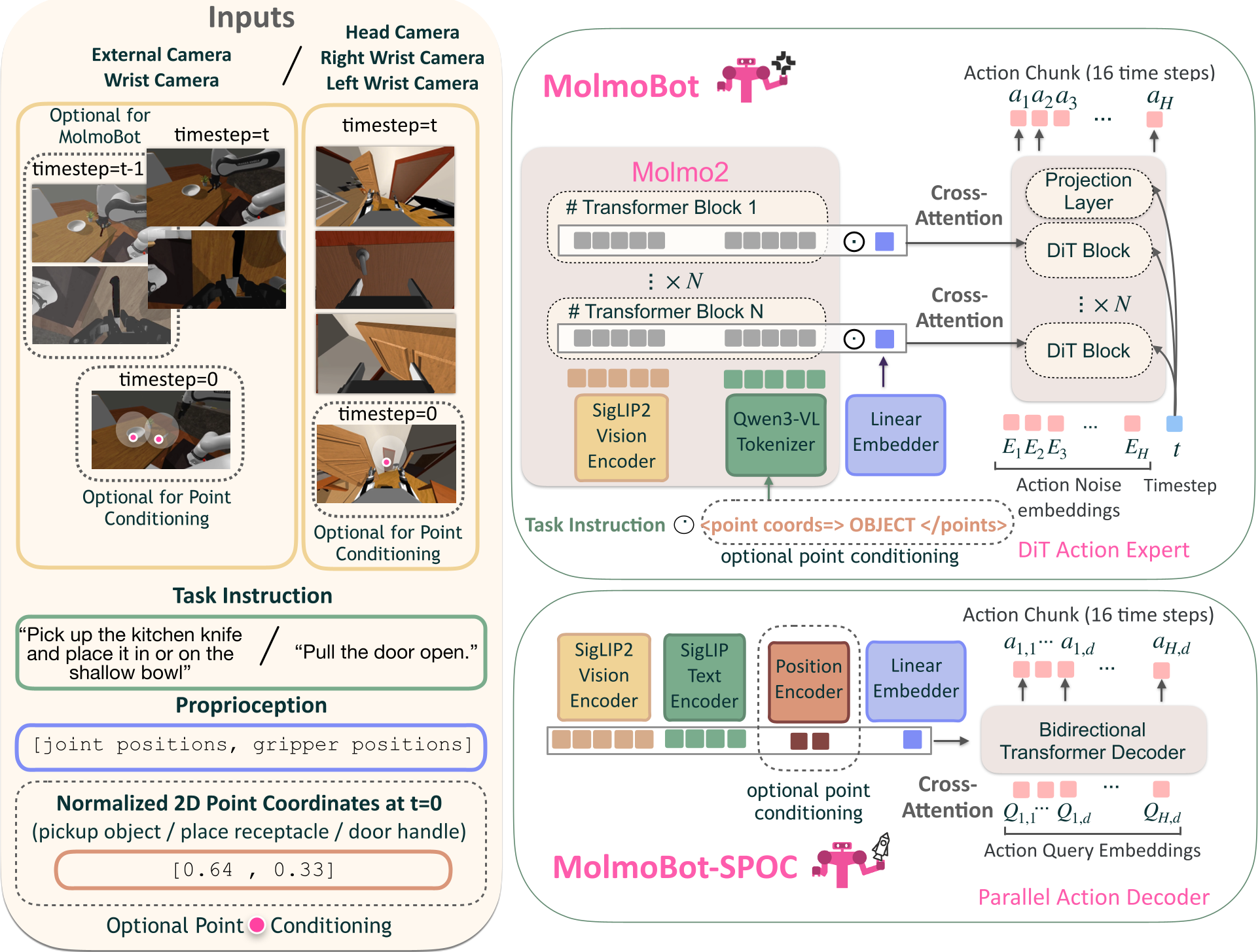 Figure 1: The MolmoBot policy architecture showcasing the VLM backbone and the coupled DiT action head.
Figure 1: The MolmoBot policy architecture showcasing the VLM backbone and the coupled DiT action head.
Experiments: Real-World Dominance
The most striking result is the performance on the Franka FR3 tabletop benchmark. Despite never seeing a single real-world image or robot command during training, MolmoBot achieved a 79.2% success rate, nearly doubling the performance of π0.5 (39.2%), a model trained on 10,000+ hours of real-world demonstrations.
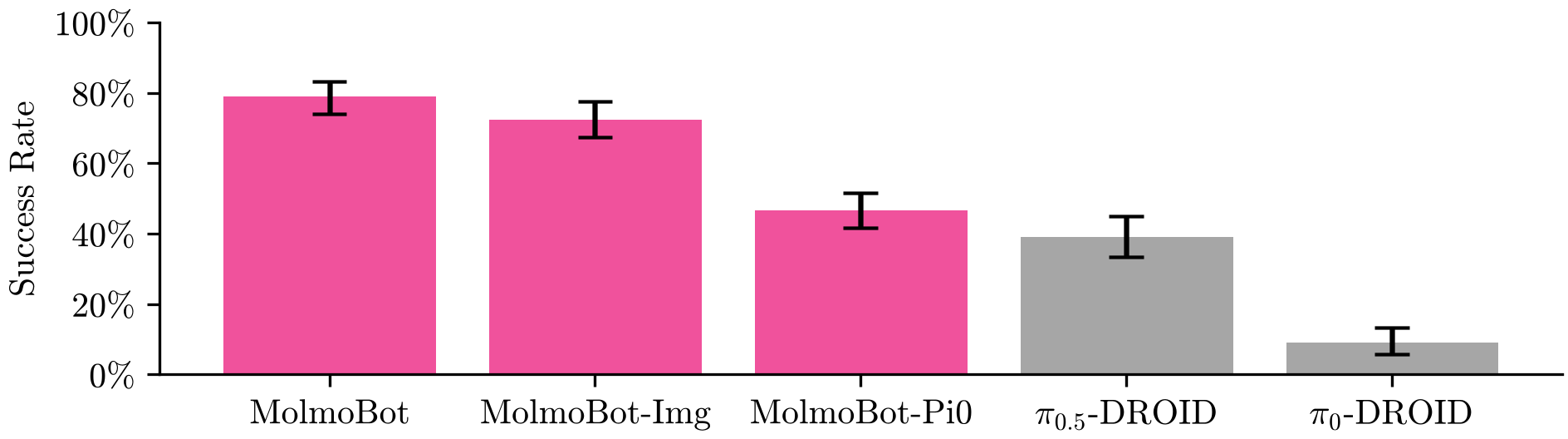 Figure 2: Real-world success rates across different environments (Kitchen, Workroom, Bedroom, Office). MolmoBot variants consistently lead.
Figure 2: Real-world success rates across different environments (Kitchen, Workroom, Bedroom, Office). MolmoBot variants consistently lead.
Mobile Manipulation: The Final Frontier
The study also deployed the model on the Rainbow Robotics RB-Y1, a mobile manipulator. The policy successfully performed complex articulated tasks—opening drawers, cabinets, and even high-resistance pull-doors—in completely unseen real-world environments.
Critical Analysis & Takeaways
Why does this work?
- The Power of Scaling: Ablation studies showed that success scales monotonically with the number of demonstrations and object diversity.
- Joint Space Control: Using absolute joint positions rather than end-effector deltas proved superior for sim-to-real transfer.
- Data Quality: Even using the π0 architecture (MolmoBot-Pi0), the model outperformed the original π0, proving that the data engine is the primary differentiator.
Limitations
While MolmoBot masters rigid and articulated objects, it currently struggles with contact-rich dexterity (e.g., peg-in-hole) and deformables (e.g., cloth). These tasks require higher physics fidelity than current simulators easily provide.
The Future of Open Robotics
By open-sourcing MolmoBot-Engine, MolmoBot-Data, and the model weights, the authors have democratized the "recipe" for robotics foundation models. The message is clear: the path to general-purpose robots may not be paved with expensive real-world data, but with a massive, diverse, and well-structured simulated world.
Conclusion
MolmoBot is a landmark paper for 2026. It provides a robust, reproducible counter-argument to the necessity of real-world data for manipulation. As simulation fidelity improves, this "sim-only" approach may soon become the standard for training the next generation of physical AI.