本文提出了 MOMENTA,一个集成多模态专家混合(MoE)、双向协同注意力和神经时间聚合的统一框架,用于虚假信息检测。该方法在 Fakeddit, MMCoVaR, Weibo, 和 XFacta 四大基准数据集上均取得了 SOTA 性能,显著提升了跨领域泛化能力。
TL;DR
虚假信息的进化速度远超想象。本文提出的 MOMENTA 框架,不仅能“看懂”图文不符(跨模态不一致性),还能“追踪”叙事演化(时间动态),并通过 Mixture-of-Experts (MoE) 架构实现了极强的跨领域泛化能力。在 XFacta 等多个硬核榜单上,它再次刷新了 SOTA 纪录。
1. 痛点:静态检测已死,叙事正在进化
传统的虚假信息检测系统往往面临三大挑战:
- 语义鸿沟与断章取义:很多假新闻并非图片或文字本身造假,而是“旧图配新词”,这种语义冲突难以捕捉。
- 叙事的动态演化:虚假信息像病毒一样随时间变异。静态模型只能看到快照,看不到趋势。
- 领域偏移(Domain Shift):在微博上训练的模型,换到 X(原 Twitter)或 Reddit 上往往表现惨淡。
2. 核心直觉:如何让模型具备“ specialization”与“memory”?
作者认为,不同类型的造假(如讽刺、完全伪造、重新利用内容)具有完全不同的特征分布。因此,不应使用单一的编码器,而是引入 MoE(混合专家模型),让专门的“专家”处理特定的模式。同时,引入时间窗口与**动量(Momentum)**机制,赋予模型识别叙事演进的能力。
3. 架构拆解:MOMENTA 的多维防御
MOMENTA 的核心由四个关键模块组成:
3.1 模态特定 MoE 模块
针对文本和图像,模型分别设置了 个专家网络。通过门控机制(Gating Mechanism),输入会根据内容特征动态路由到最合适的专家手中,从而在保持参数效率的同时捕捉异构的造假轨迹。
3.2 双向协同注意力 (Bidirectional Co-Attention)
为了强迫模型关注“图文是否匹配”,MOMENTA 使用了共享参数的注意力矩阵,实现文本对图像、图像对文本的双向对齐。
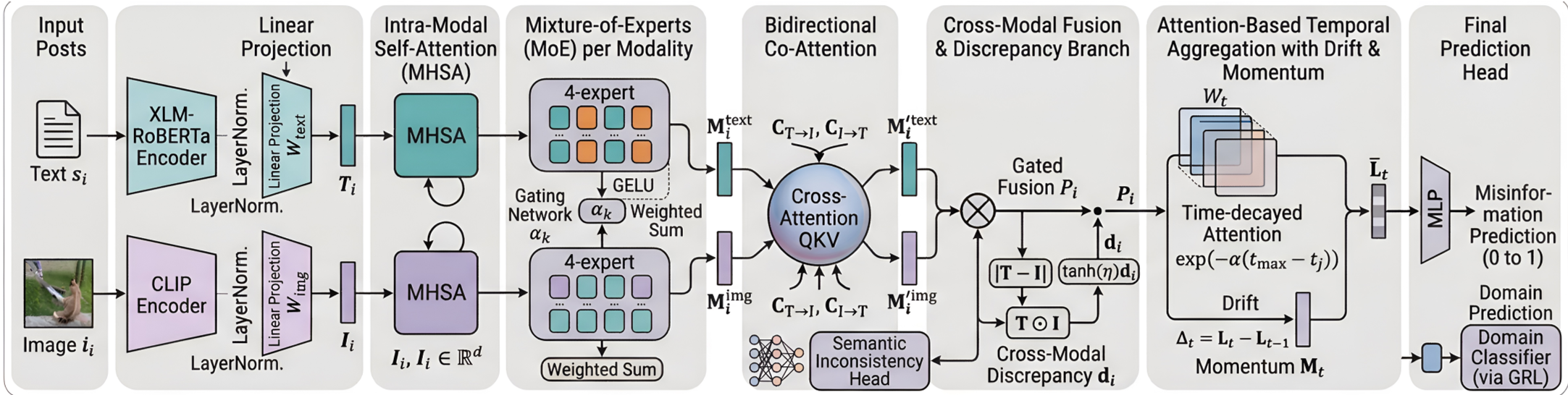
3.3 神经时间聚合 (Neural Temporal Aggregation)
这是本文的创新亮点。模型不仅聚合了时间窗口内的信息,还显式计算了两个特征:
- Drift(漂移):表征连续窗口间叙事重心的变化。
- Momentum(动量):平滑后的演化强度,捕捉长期的叙事趋势。
3.4 领域不变性训练
通过 梯度反转层 (GRL) 进行对抗训练,并配合一个 EMA 原型记忆库,确保模型学到的特征是分类本质(真 vs 假),而不是特定数据集的噪声。
4. 实验战绩:全线突破
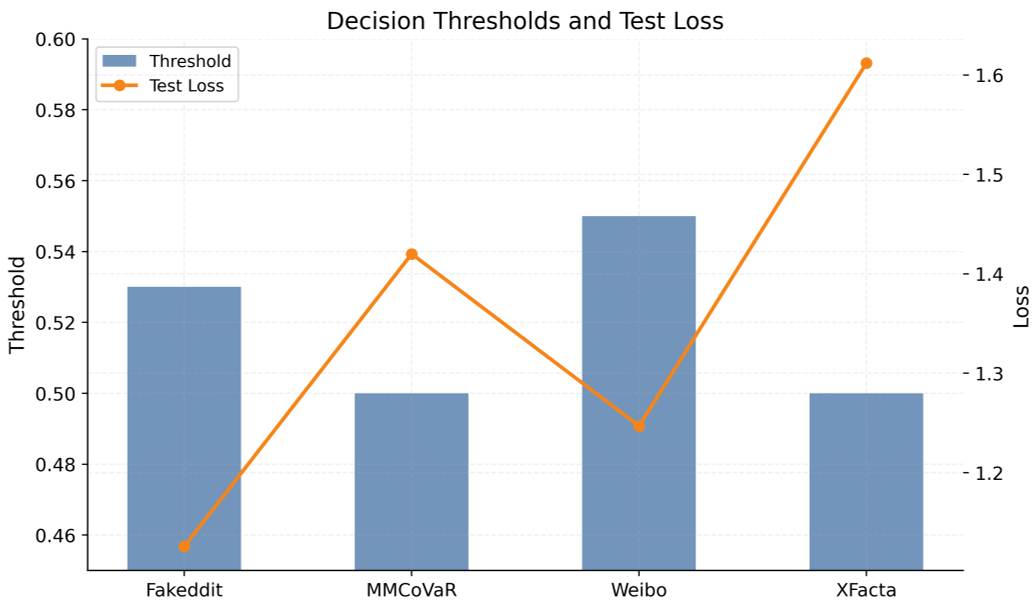
在 Fakeddit, Weibo, MMCoVaR, 以及针对 LLM 极具挑战性的 XFacta 数据集上,MOMENTA 均表现卓越。
| 数据集 | 准确率 (Acc) | F1-Score | AUC | | :--- | :--- | :--- | :--- | | Fakeddit | 0.965 | 0.959 | 0.982 | | Weibo | 0.956 | 0.956 | 0.981 | | XFacta | 0.905 | 0.905 | 0.928 |
特别是在跨领域场景下(XFacta),MOMENTA 比之前的最强基线提升了 1.7个百分点,这证明了原型对齐和领域对抗策略的有效性。
5. 深度洞察
- 为什么 MoE 有效? 在消融实验中,去除 MoE 会导致模型在混杂语境下的 F1 值显著受损。专家特化成功解决了单一强模型难以兼顾“讽刺”与“事实伪造”多种分布的问题。
- 时间维度的价值:通过引入“漂移”特征,模型能够识别出那些刻意制造的、突然改变舆论走向的协调性造假活动(Coordinated Campaigns)。
6. 总结与展望
MOMENTA 成功地在一个架构中解决了异构性、不一致性、时间性和领域泛化四大难题。尽管目前的架构复杂度较高(MoE + 多个辅助 Head),但其在真实、动态社交媒体环境下的表现,为下一代实时虚假信息监控系统提供了清晰的蓝图。
未来的研究方向可能在于引入知识图谱或外部证据库,以解决那些图文完全一致但内容本身违背客观事实的“硬核”造假。
关键词:Misinformation Detection, Mixture-of-Experts, Temporal Modeling, Domain Adaptation.