OVIE is a groundbreaking monocular novel-view synthesis framework that eliminates the need for multi-view image pairs during training. By leveraging a metric depth estimator to create "pseudo-target" views from 30 million unpaired internet images, it achieves state-of-the-art zero-shot generalization and operates at over 100 FPS.
TL;DR
Novel view synthesis (NVS) from a single image has finally broken free from the "multi-view pair" bottleneck. OVIE (One View Is Enough) proposes a training paradigm that uses a metric depth estimator to turn any single image into a training pair. Trained on 30 million "in-the-wild" images, OVIE achieves SOTA out-of-domain generalization while being 600x faster (100+ FPS) than existing high-performance baselines.
Background: The Scarcity of Multi-View Data
For years, monocular NVS models were "trust-fund babies"—they inherited their geometric understanding from expensive, specialized datasets like RealEstate10K or DL3DV. These datasets require calibrated, multi-view setups that simply don't exist for the vast majority of the internet's visual content.
Previous attempts to solve this involved:
- Synthetic data: High diversity but a massive "domain gap" from real photos.
- Generative Priors (Diffusion): Excellent quality but painfully slow (often taking seconds to generate one frame) and prone to "forgetting" the target pose.
- Warp-and-Inpaint: Highly dependent on the depth estimator at inference time; if the depth fails, the whole scene falls apart.
OVIE changes the game by proving that we can use monocular depth estimation as a training-time scaffold and then throw it away at inference.
Methodology: Mining 3D Knowledge from 2D Images
The core intuition behind OVIE is that monocular depth estimation has reached a tipping point of accuracy. While not perfect, it is "good enough" to act as a teacher.
1. The Pseudo-Pair Factory
At training time, the authors take an unlabelled image, lift it into a 3D point cloud using MoGe-2, and sample a new camera pose. By reprojecting the points, they create a pseudo-target. This target is sparse (it has holes where the camera "sees" behind objects), but it provides a ground-truth signal for the pixels that are visible.
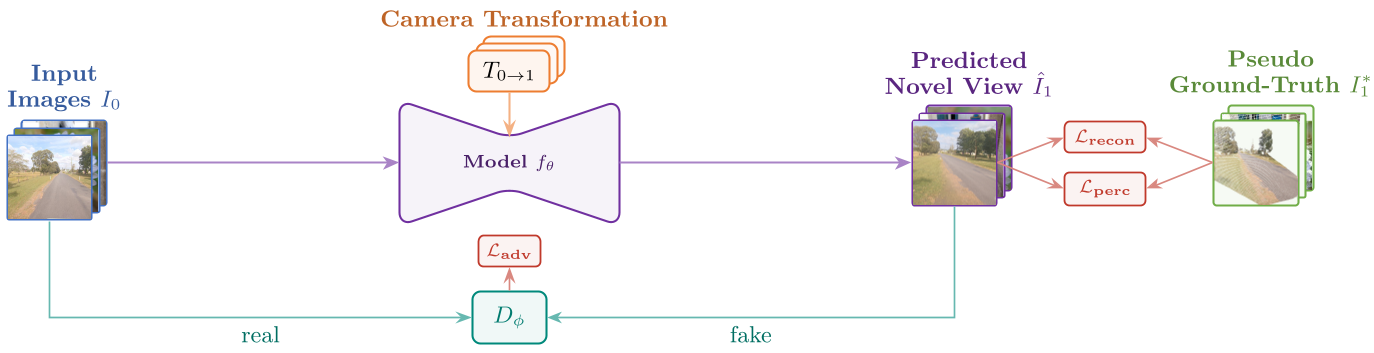
2. Geometry-Free Inference
Unlike warping-based methods, OVIE's model (a Transformer-based architecture) takes only the source image and a target pose (7D vector). It doesn't look at depth maps or point clouds during inference. This "geometry-free" design allows the model to learn the underlying physics of parallax and occlusion implicitly.
3. The Loss Trinity
To make the model robust to the "noisy" pseudo-targets, the authors use:
- Masked Reconstruction Loss: Only penalizes the model on pixels that were successfully reprojected.
- Masked Perceptual Loss (P-DINO/LPIPS): Ensures semantic consistency.
- Adversarial PatchGAN: Forces the model to hallucinate realistic textures in the "holes" (disocclusions) that the point cloud couldn't fill.
Experiments: Speed Meets Generalization
The results are clear: OVIE isn't just a research curiosity; it's a practical powerhouse.
SOTA Performance
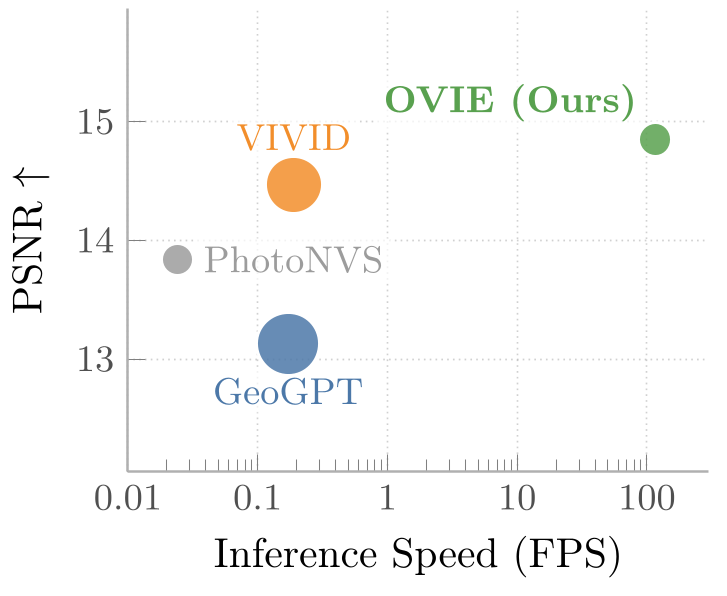
On the DL3DV benchmark—a fair "blind test" for all models because none were trained on it—OVIE outperformed VIVID (a strong diffusion baseline) on every metric, including a 24% improvement in FID (realism).

Breakthrough Speed
The most impressive feat is the throughput. While diffusion models crawl at 0.02 to 0.19 FPS, OVIE blazes at 116 FPS. This makes real-time, interactive exploration of a single photograph possible for the first time.
Qualitative Analysis
OVIE demonstrates a remarkable "metric scale awareness." Since it was trained using a metric depth estimator, it understands that nearby objects should move faster than distant ones when the camera translates—a property often lost in models that treat scale as ambiguous. It even generalizes to paintings and historical archives where no 3D data could ever exist.

Critical Insight & Conclusion
OVIE proves a fundamental thesis in modern AI: Scaling data is more important than specialized architectures. By converting the "abundance" of single images into "synthetic" multi-view pairs, the authors have tapped into a virtually infinite training signal.
Limitations: The model's quality is still tied to the quality of the offline depth estimator used for training. If the depth teacher is consistently wrong about a certain type of geometry, the model inherits that bias.
Future Work: Imagine this model combined with a world model for long-term consistency. OVIE provides the local 3D "common sense" that could empower the next generation of generative AI agents and interactive digital twins.