The MOSS-TTS technical report introduces a foundational speech generation model based on a scalable "discrete audio tokens + autoregressive (AR) modeling" recipe. It features two specialized architectures: MOSS-TTS (optimized for long-context stability and control) and MOSS-TTS-Local-Transformer (optimized for zero-shot speaker preservation), achieving state-of-the-art results in multilingual voice cloning and ultra-long speech generation.
TL;DR
The SII-OpenMOSS team has released MOSS-TTS, a speech foundation model that moves away from the complicated "cascaded" structures of the past. By leveraging a high-performance 1.6B Transformer tokenizer and a massive multilingual dataset, MOSS-TTS achieves SOTA zero-shot voice cloning and stable speech generation for segments as long as one hour. It provides a blueprint for scaling speech models like Large Language Models (LLMs).
The Core Intuition: The "LLM" Philosophy for Audio
Historically, Text-to-Speech (TTS) involved multiple stages: text-to-spectrogram, spectrogram-to-waveform, and often external semantic guidance (like HuBERT). MOSS-TTS argues for radical simplification:
- Tokenize everything into a unified discrete space (Acoustic + Semantic).
- Predict those tokens using a standard Autoregressive (AR) Transformer.
- Scale the data to millions of hours.
This approach treats audio as just another "language," allowing the model to benefit from the same scaling laws that powered GPT-4 and Llama.
Methodology: Two Paths to Synthesis
The report highlights a fascinating architectural choice by providing two distinct generator versions:
1. The Delay-Pattern (MOSS-TTS)
A single Transformer backbone handles multi-stream RVQ (Residual Vector Quantization) tokens by shifting each layer forward in time. This creates a simple, scalable structure ideal for long-context tasks and high-throughput deployment.
2. The Local Transformer (MOSS-TTS-Local-Transformer)
This version uses a "Global-Latent + Local-Transformer" hierarchy. The global model predicts a frame representation, and a lightning-fast local model expands it into individual audio tokens. Why it works: It has a stronger inductive bias for capturing the nuance of a speaker's voice, leading to superior Voice Cloning (Similarity) scores even at a smaller parameter count.
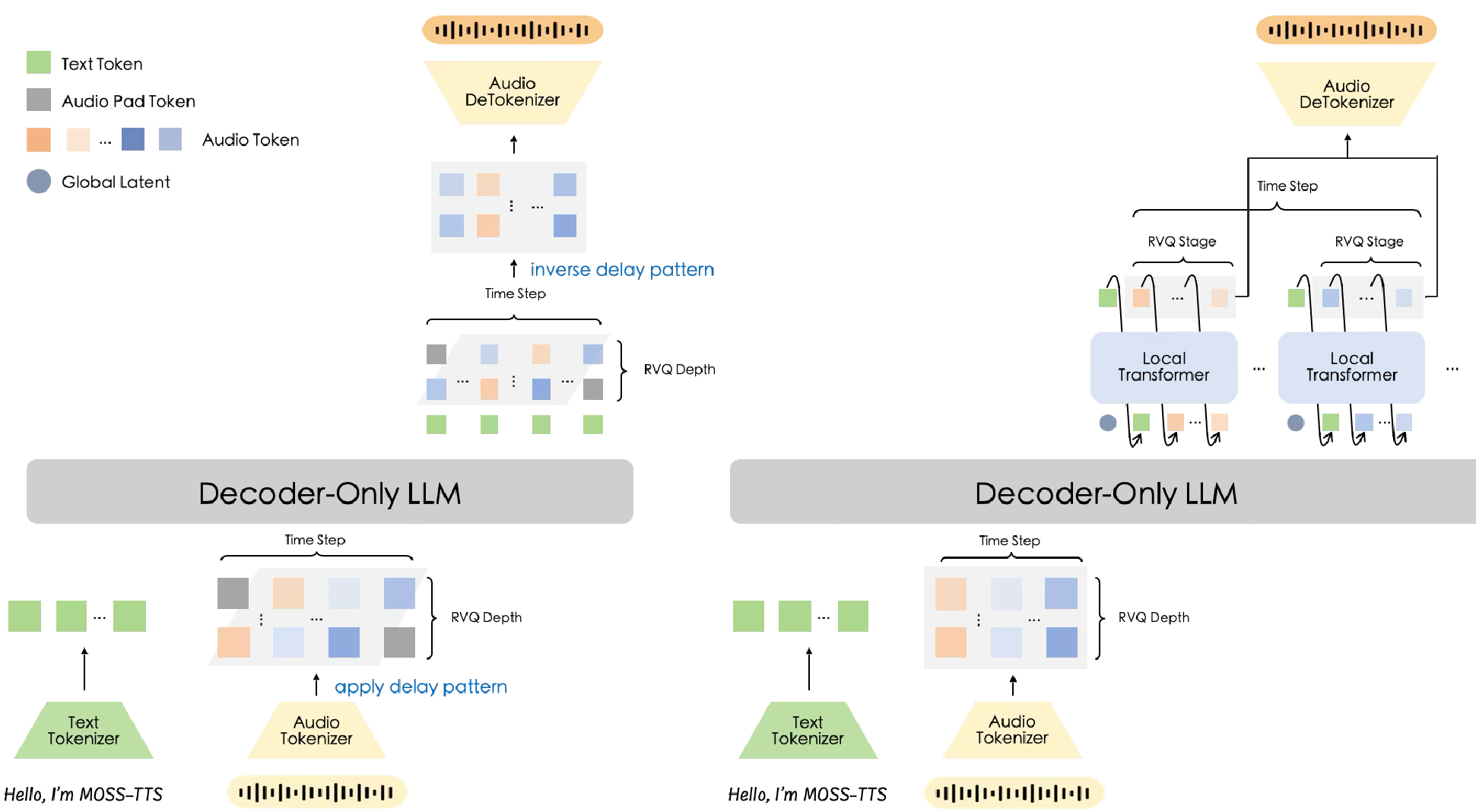 Figure: The Delay Pattern (Left) vs. Local Transformer Pattern (Right).
Figure: The Delay Pattern (Left) vs. Local Transformer Pattern (Right).
Pushing the Limits: 1-Hour Stable Generation
One of the most impressive feats of MOSS-TTS is its robustness in Ultra-Long Generation. Most AR models "collapse" or lose the speaker's identity after a few minutes.
The team implemented a staged curriculum pretraining:
- P1-P3: Mastering short-form alignment and control.
- P4: Context extension to 64k tokens specifically for long-form stability.
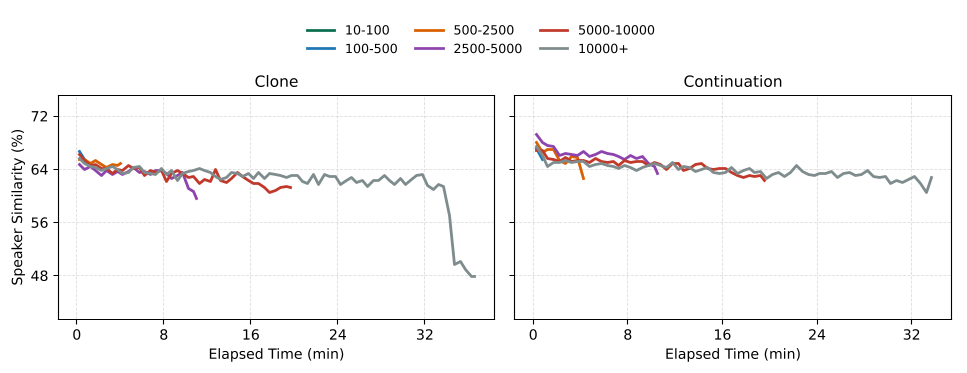 Figure: Speaker similarity (SIM) over time. Note how the 'Continuation' mode helps anchor the voice better than standard 'Clone' mode.
Figure: Speaker similarity (SIM) over time. Note how the 'Continuation' mode helps anchor the voice better than standard 'Clone' mode.
Key Results & Benchmarks
MOSS-TTS excels in Zero-Shot Voice Cloning, where it can mimic a speaker from just a few seconds of reference audio.
| Model | Params | EN SIM ↑ | ZH SIM ↑ | | :--- | :--- | :--- | :--- | | CosyVoice2 | 0.5B | 65.90 | 75.70 | | Qwen3-TTS | 1.7B | 71.45 | 76.72 | | MOSS-TTS-Local | 1.7B | 73.28 | 79.62 |
Beyond cloning, MOSS-TTS provides Token-Level Control. By specifying exact token counts, users can control the duration of speech with sub-1% error rates—a huge win for synchronization in film or advertising.
Critical Insight: Speaker Drift vs. Lexical Fidelity
The report offers a profound technical takeaway: In long-form generation, the model doesn't "forget" how to read—it "forgets" the person. Lexical fidelity (accurately pronouncing words) remains stable even after 30 minutes, but the speaker's timbre begins to drift. This suggests that future research should focus on "Timbre Anchoring" mechanisms rather than better ASR-based supervision.
Conclusion
MOSS-TTS proves that the "tokenization + AR" recipe is sufficient to build a world-class speech foundation model. By releasing both the tokenizer and the dual-architecture generators, the SII-OpenMOSS team has provided the community with a robust, scalable, and highly controllable toolkit for the next generation of AI voice applications.