本文推出了 MOSS-TTSD,这是一个支持多角色、长文本、跨语言的高质量对话语音合成模型。它基于 Qwen3-8B 和离散音频编码器,实现了单次生成长达 60 分钟且无需拼接的稳定对话声音,在 Zero-shot 声纹克隆和多角色切换上达到了 SOTA 水平。
TL;DR
由 SII-OpenMOSS 团队开发的 MOSS-TTSD 是一款专为复杂对话场景设计的语音合成(TTS)模型。它不仅能实现极长(单次 60 分钟)的稳定语音输出,更在多人角色切换、跨语言声纹克隆以及长程音色一致性上刷新了业界标准。
背景定位:这是语音生成领域从“单句合成”向“长篇叙事”跨越的里程碑式工作,在对话逻辑与声学质量的结合上达到了闭源 SOTA 的水平。
1. 对话生成的“深水区”:为什么单句 TTS 做不好对话?
传统的 TTS 模型(如常见的 VALL-E 或驱动式模型)在短句上表现出色,但一旦进入多人对话(Spoken Dialogue Generation)场景,就会陷入三大泥潭:
- 上下文断层:模型不记得 10 分钟前角色的语调,导致音色漂移。
- 切换僵硬:多人剧本中,角色 A 结束到角色 B 开始的切换往往带有明显的拼接感。
- 长文本崩溃:由于 Attention 复杂度的增长,生成超长音频(Podcast 级)时极其不稳定。
2. 核心架构:离散表征与 LLM 的深度耦合
MOSS-TTSD 采用了全离散生成的思路,其核心竞争力源于对“信息密度”的精准控制:
- Qwen3-8B 骨干:利用强大的底座模型处理多语种和复杂的对话脚本。
- RVQ 的取舍艺术:不同于常规模型对所有量化层进行建模,MOSS-TTSD 仅选择 前 16 层 RVQ。这种低比特率(2kbps)的设计不仅保证了语音的自然度,更让 LLM 能够处理长达 3600 秒的序列窗口。
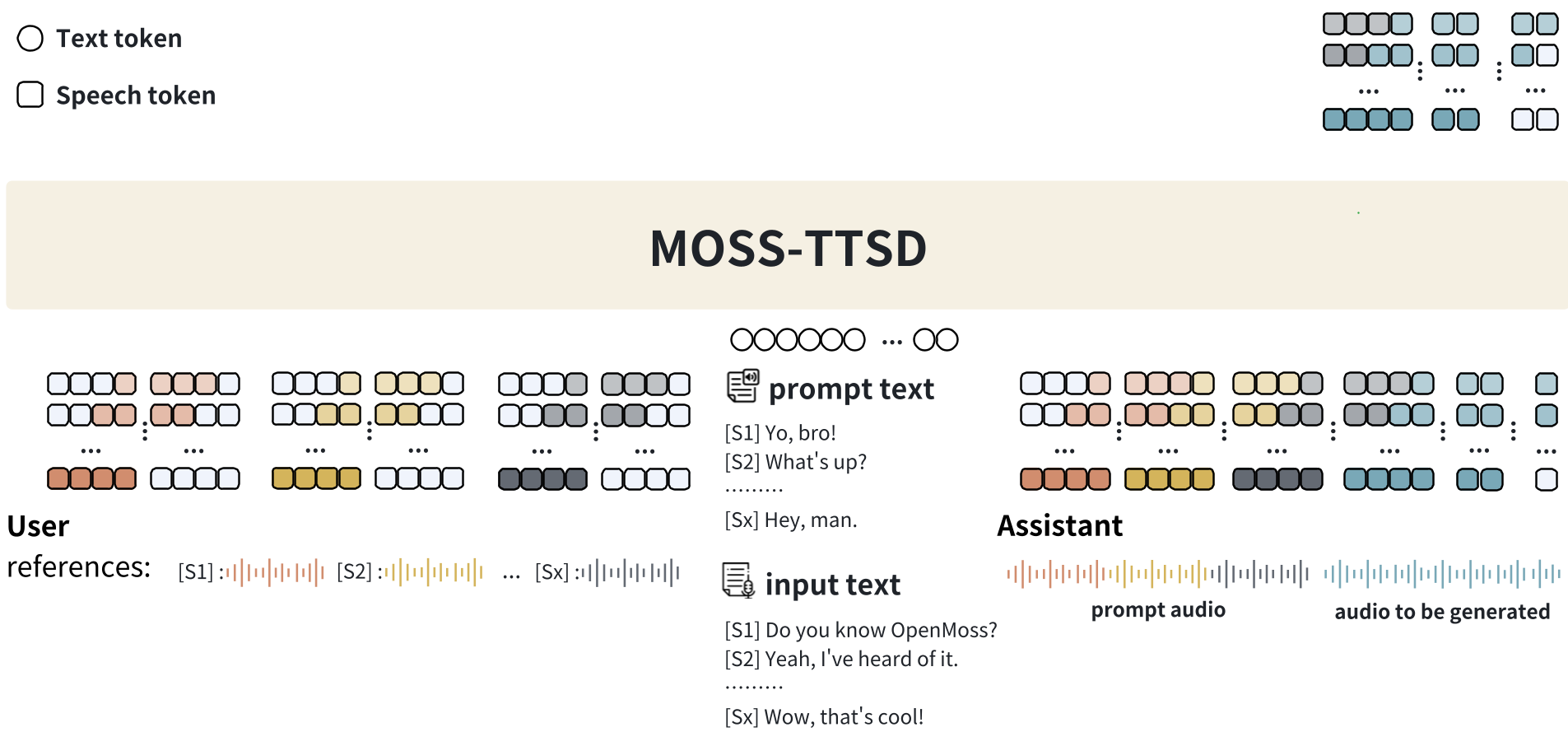 上图展示了 MOSS-TTSD 的推理逻辑:通过 [S1]/[S2] 标签显式控制角色,并结合参考音频实现 Zero-shot 声纹克隆。
上图展示了 MOSS-TTSD 的推理逻辑:通过 [S1]/[S2] 标签显式控制角色,并结合参考音频实现 Zero-shot 声纹克隆。
3. 课程学习:如何让模型学会“聊天”?
为了让模型从只会“朗读”变成会“演戏”,团队设计了三阶段的课程学习(Curriculum Learning):
- 续训阶段:从单人 TTS 转变为双人对话,让模型学会处理角色标签。
- 高保真阶段:精选 DNSMOS ≥ 3.4 的数据,强化音质。
- 多人混合阶段:加入 3-5 人的真实及合成数据,彻底解决多人场景下的身份识别混乱问题。
4. TTSD-eval:更客观的评价体系
过去评测对话 TTS 需要依赖第三方“说话人日志(Diarization)”工具,但这往往导致“错上加错”。团队提出了 TTSD-eval,利用**强制对齐(Forced Alignment)**技术:
- 将生成的音频与脚本中的单词精确对齐。
- 直接基于时间戳提取片段,通过 Embedding 对比计算 Speaker Attribution Accuracy (ACC)。
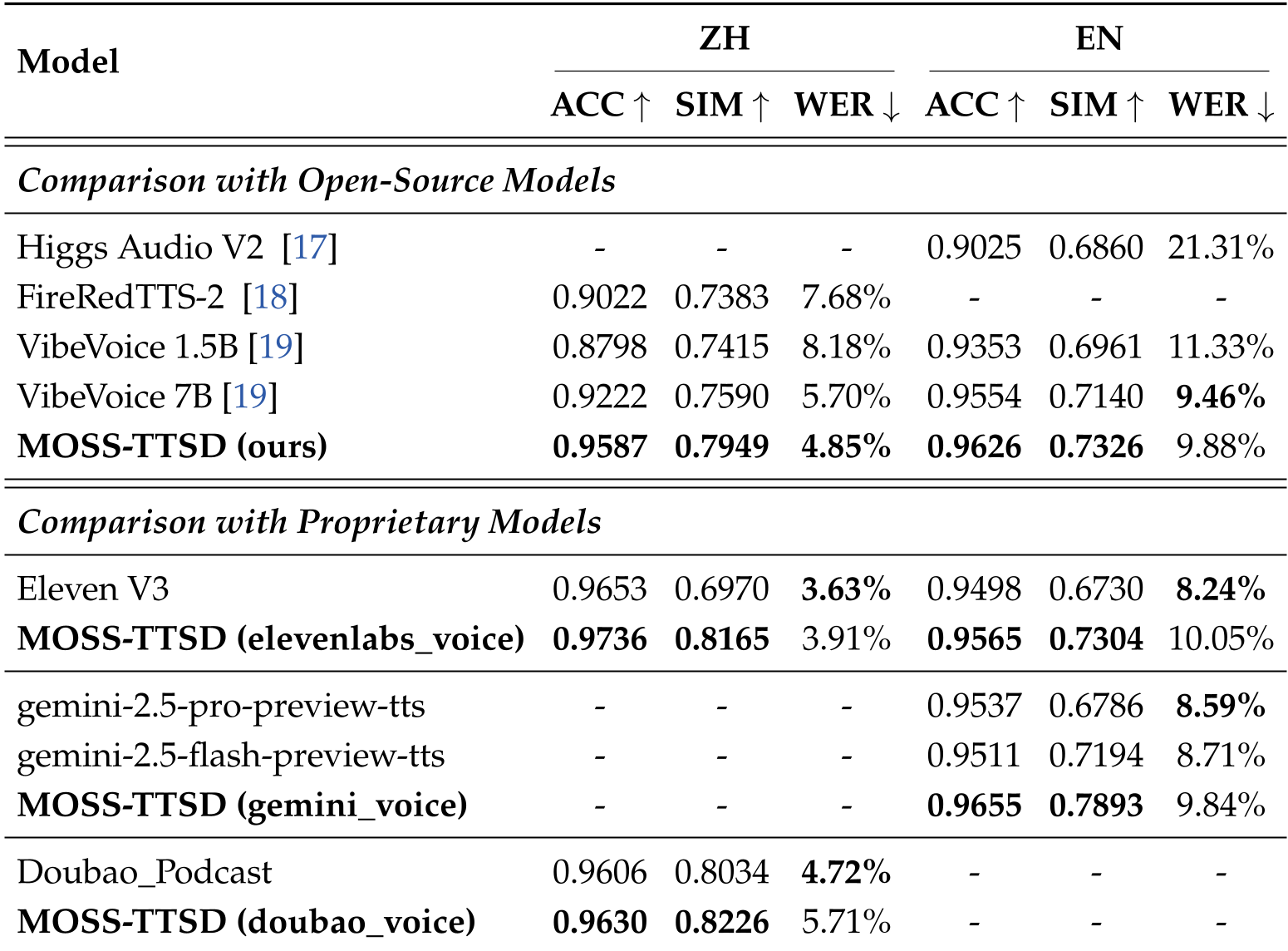 表格 1 指出,MOSS-TTSD 在各项指标上均全面压制了包含 Eleven V3、Gemini 在内的最强基线。
表格 1 指出,MOSS-TTSD 在各项指标上均全面压制了包含 Eleven V3、Gemini 在内的最强基线。
5. 深度洞察:为什么它有效?
MOSS-TTSD 成功的本质在于 “由繁入简” 的方法论。
- Voice Clone & Continuation:这是本文的一个神来之笔。模型不仅看参考音频(Reference),还参考刚才生成的音频(Continuation)。这种“双重锚定”机制极大地增强了音色的稳定性。
- 数据合成的智慧:针对缺乏多人对话数据的问题,团队并没有盲目爬取低质量音频,而是通过拼接高质量单人片段并辅以特殊的文本增强(Punctuation Diversity),让生成的对话听起来更像真人。
6. 局限与展望
虽然 MOSS-TTSD 在长文本和多人控制上表现惊艳,但在极端非平稳背景音(如嘈杂的竞技场)下的分离表现仍有提升空间。此外,目前模型对于剧本中蕴含的情感(如“愤怒地”、“小声嘀咕”)尚未实现全自动的语义解耦生成。
总结:MOSS-TTSD 的开源标志着超长对话合成技术进入了普惠时代。无论是制作 AI 播客、虚拟主持人,还是为游戏实现动态多人配音,它都提供了一个目前看来最强大且稳定的技术栈。