本文提出了 Motion-Adapter,一个用于文本生成动作(Text-to-Motion)的即插即用型扩散模型适配器。该方法通过解耦交叉注意力机制生成结构化掩码(Structural Masks),实现了复杂组合动作(如边走边招手)的高质量生成,并在多个主流扩散底座上达到了 SOTA 性能。
TL;DR
在 3D 人体动作生成领域,让模型生成“走路”或“挥手”很容易,但让它生成“边走路边挥手”却出奇地难。西北大学的研究团队提出了 Motion-Adapter,一个即插即用的扩散模型适配器。它通过解耦交叉注意力(Decoupled Cross-Attention)生成的结构化掩码,完美解决了组合动作中的“注意力崩溃”问题,无需重训底座即可实现 SOTA 级别的复杂动作合成。
痛点深挖:为什么 AI 很难“一心多用”?
当前的文本驱动动作生成(Text-to-Motion)模型在处理单一简单动作时已经非常成熟。然而,当你给出一个组合指令(Compound Action),例如“一边倒地躲避一边向前奔跑”时,现有的扩散模型(如 MDM, MotionDiffuse)往往会陷入困境:
- 灾难性遗忘 (Catastrophic Neglect):模型在处理长文本或多指令时,后期产生的特征会将前期的运动信息覆盖,导致生成的动作不完整。
- 注意力崩溃 (Attention Collapse):由于模型内部过于激进的特征融合,交叉注意力图(Cross-attention maps)往往会弥散到全身,无法精准地将“挥手”关联到手部,将“跑步”关联到腿部。
结果就是,模型要么只做其中一个动作,要么动作扭曲变形,缺乏物理协调性。
核心逻辑:Motion-Adapter 的“手术刀式”精准控制
为了解决这些问题,作者并没有选择去暴力微调庞大的扩散模型,而是设计了一个轻量级的 Motion-Adapter。
1. 解耦交叉注意力 (Decoupled Cross-Attention)
这是系统的核心。作者构建了一个包含 5 个 STEncoder(空时编码器)的模块。该模块学习如何将文本中的动词(Token)与特定的骨骼关节(Joints)对应起来。通过自监督学习,模型能提取出清晰的注意力图。
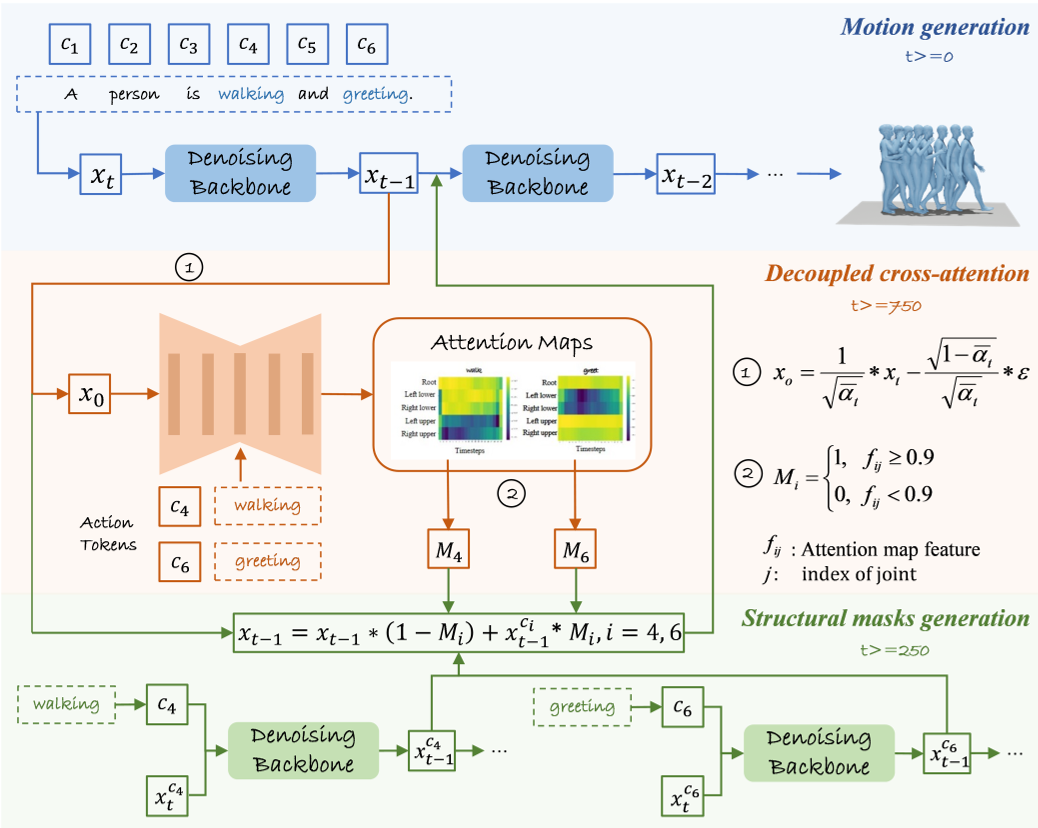 图 1:Motion-Adapter 集成到扩散模型去噪步骤中的示意图。它在每个去噪步 t 生成动态掩码。
图 1:Motion-Adapter 集成到扩散模型去噪步骤中的示意图。它在每个去噪步 t 生成动态掩码。
2. 结构化掩码引导 (Structural Masks)
生成的注意力图被转化为“结构化掩码”。这些掩码就像是动作的“施工蓝图”,告知扩散模型:在当前的去噪步骤中,哪些关节应该受哪个动作词的影响。
- 身体部位约束:为了防止动作“异形”,作者加入了生物力学约束(如上肢关节联动,根节点与下肢联动)。
- 动态步数控制:研究发现,掩码并非在所有去噪阶段都有效。作者精准地设定了策略:仅在 到 的关键区间内应用掩码,确保了动作既有语义准确性,又有自然的物理过渡。
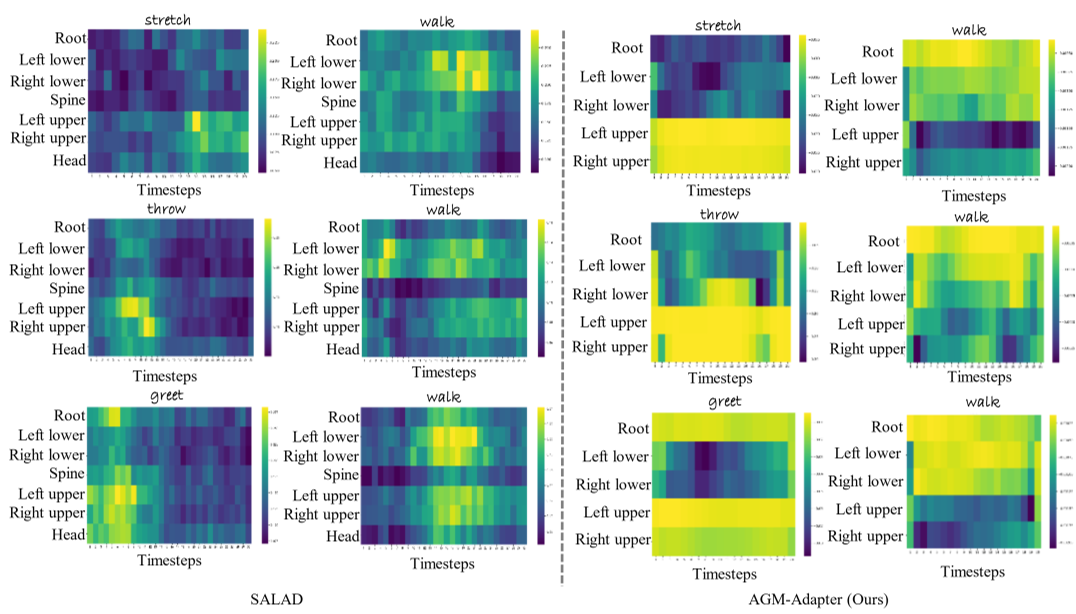 图 2:SALAD (左) 与 Motion-Adapter (右) 的注意力图对比。可见本方法能更精准地定位到受控部位。
图 2:SALAD (左) 与 Motion-Adapter (右) 的注意力图对比。可见本方法能更精准地定位到受控部位。
实验战绩:全方位碾压基线
研究人员在自定义的组合动作 Benchmark(包含 484 种独特动作组合)上进行了测试。结果令人惊叹:
- 保真度 (Fidelity):在 65 人的用户评估中,Motion-Adapter 得分超过 9.0,而之前的 SOTA 方法如 SALAD 或 MDM 均未超过 6.0。
- 语义对齐 (R-Precision):在复杂的 32 类动作识别测试中,识别准确率从基线的 50% 左右提升至近 90%。
- 视觉效果:即便面对“边转圈边跳跃”这种高难度协同动作,生成的 sequence 依然丝滑,没有过度僵硬的拼接感。
 图 3:针对复杂提示词(如:边圆周行走边打拳)的生成效果对比,Motion-Adapter 表现出极强的肢体协调性。
图 3:针对复杂提示词(如:边圆周行走边打拳)的生成效果对比,Motion-Adapter 表现出极强的肢体协调性。
深度洞察与总结
Motion-Adapter 的成功给研究界带来了重要的启发:在生成复杂内容时,与其指望一个全能底座自动学到时空解耦,不如引入一个结构化的“中介器”来显式分配注意力。
局限性与未来
尽管该方法在组合动作上表现优异,但它目前将上肢和下肢作为统一区域处理,还无法精细到“手指抓取”级别的细微动作。此外,它的性能上限依然受限于所挂载的扩散模型底座。未来,如何将这种解耦思想扩展到更细粒度的部位控制(Fine-grained parts),将是该领域值得关注的赛道。
Verdict: 如果你正在寻找一种无需重训模型就能大幅提升 3D 动作生成精确度的方法,Motion-Adapter 无疑是目前最值得尝试的方案。