MoRight is a unified controllable video generation framework that achieves disentangled camera-object control and motion causality reasoning. By utilizing a dual-stream DiT-based architecture, it enables users to specify object trajectories in a canonical static view while independently adjusting target camera viewpoints, achieving SOTA performance on benchmarks like DynPose-100K and WISA.
TL;DR
MoRight is a breakthrough in controllable video generation that finally separates How the camera moves from How objects interact. Unlike previous models that just "track pixels," MoRight understands Motion Causality—it can predict that pushing a ball will make it roll (Forward Reasoning) or figure out what hand movement caused a cloth to move (Inverse Reasoning). It uses a dual-stream architecture to keep camera and object controls independent, setting a new SOTA for physically grounded video synthesis.
The Problem: The "Pixel Tracking" Trap
Current SOTA models (like WanMove or Motion Prompting) operate essentially as high-end "pixel-warpers." They face two critical hurdles:
- The Entanglement Problem: In these models, a trajectory is just a path on a 2D screen. If you change the camera angle, the entire trajectory changes. You cannot simply say "move the object left" and "zoom in" separately without the math breaking down.
- The "Puppet" Problem: They lack physical intuition. If a user draws a trajectory for a hand, the model might move the hand but leave the object it's touching static. It doesn't realize that Action leads to Consequence.
Methodology: The Dual-Stream & Causal Engine
MoRight's architecture is built on the Wan2.1-14B backbone but introduces a clever Dual-Stream configuration.
1. Disentangled Camera-Object Control
Instead of one video stream, MoRight processes two:
- Canonical Stream: Generates the video from a fixed, static viewpoint. Here, the object motion is "pure" and unambiguous.
- Target Stream: Generates the video from the user's requested camera path. The magic happens in the Temporal Cross-View Attention blocks, where the Target Stream "looks" at the Canonical Stream to understand the object's physical displacement, then applies its own camera transformation.
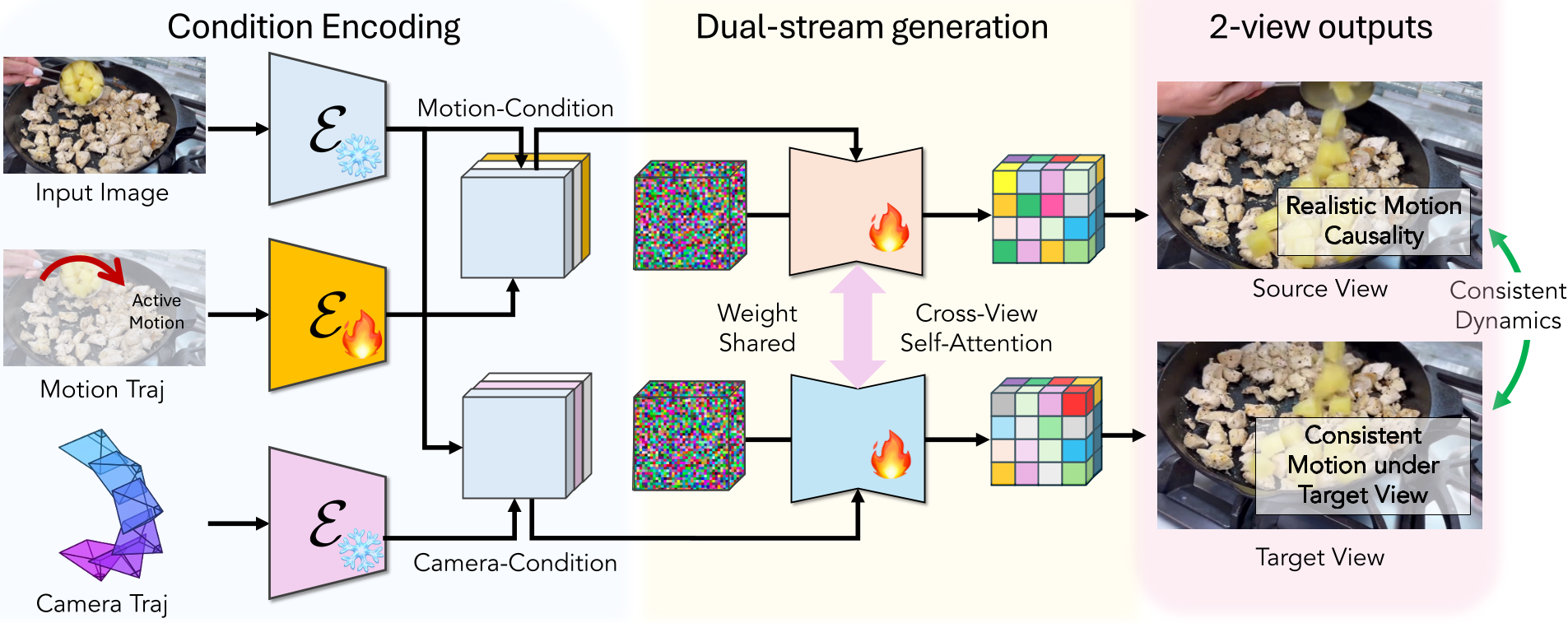 Figure 1: The dual-stream DiT architecture allows motion to be anchored in a canonical view while the target view handles camera dynamics.
Figure 1: The dual-stream DiT architecture allows motion to be anchored in a canonical view while the target view handles camera dynamics.
2. Motion Causality (Active vs. Passive)
To teach the model physics, the authors curated data by labeling objects as Active (the "input" like a hand) or Passive (the "result" like a moving teapot). During training, they use Motion Dropout: sometimes they hide the hand's path and ask the model to generate it based on the teapot's movement, and sometimes they do the opposite.
This enables two powerful modes:
- Forward Reasoning: You draw a "push" and the model predicts the "slide."
- Inverse Reasoning: You draw the desired path of a ball, and the model hallucinates the hand or force that must have caused it.
 Figure 2: MoRight can reason about consequences (Forward) and underlying causes (Inverse).
Figure 2: MoRight can reason about consequences (Forward) and underlying causes (Inverse).
Experiments & Evaluation
MoRight was tested on the DynPose-100K (dynamic cameras), WISA (physical interactions), and a custom Cooking benchmark.
- Performance: It outperformed baselines in "Physical Commonsense" (PC) and "Semantic Adherence" (SA). In human studies, it was preferred over existing SOTA methods (ATI, WanMove) across all categories: Controllability, Motion Realism, and Photorealism.
- Refining the Input: Unlike other models that require "privileged information" (knowing the future 3D path), MoRight works with simple 2D strokes on the first frame.
 Figure 3: Qualitative results show how MoRight maintains object consistency even as the camera orbits or zooms.
Figure 3: Qualitative results show how MoRight maintains object consistency even as the camera orbits or zooms.
Critical Insight & Future Outlook
The most impressive part of MoRight isn't just the "pretty pixels"; it's the shift towards Interactivity. By decomposing motion into active and passive components, NVIDIA is moving closer to a "Foundation World Model" that can be used by robots to simulate "What if I do X?"
Limitations: The model can still hallucinate (e.g., extra hands appearing) or fail in extremely high-speed, chaotic ego-motion scenes. However, as an I2V (Image-to-Video) control framework, it sets the current gold standard for how we should think about 3D space in a 2D diffusion world.
Conclusion
MoRight proves that for video generation to be useful for AI agents and creators, we must respect the laws of physics and the geometry of cameras. By disentangling these factors, we gain a tool that doesn't just animate—it reasons.