MotuBrain is an advanced World Action Model (WAM) designed for high-precision robot control by jointly modeling future visual dynamics and action sequences. Built on a three-stream Mixture-of-Transformers (MoT) and the UniDiffuser framework, it achieves SOTA performance on simulated benchmarks like RoboTwin 2.0 (96.1% success rate) and the WorldArena world-modeling leaderboard.
Executive Summary
TL;DR: MotuBrain is a cutting-edge World Action Model (WAM) that treats robot control not as a simple mapping of pixels to motors, but as a joint prediction problem of "what the world will look like" and "what I must do." By integrating a three-stream Mixture-of-Transformers (MoT) with efficient inference tricks like FP8 quantization and V2A-asymmetric denoising, MotuBrain achieves SOTA results on both functional manipulation (96% success in RoboTwin) and perceptual world modeling (WorldArena lead), while being deployable in real-time at 11Hz.
Field Positioning: This work represents the shift from passive VLA (Vision-Language-Action) policies to active World Action Models. It builds on the "foundation model" philosophy, utilizing large-scale internet video priors to infuse robots with physical common sense.
1. The Core Tension: Imitation vs. Interaction
Current robotic policies (VLAs) are remarkably good at semantic generalization—they know what a "bottle" is and how to "lift" it. However, they often fail at the physics of the world. Because they are trained primarily on static snapshots, they lack a "temporal conscience." When a contact happens or an object slips, a VLA might continue its playback, whereas a human—or a World Model—predicts the physical consequence.
The authors of MotuBrain identify two main roadblocks in recent attempts to fix this:
- The VGM+IDM Trap: Using a video model to generate frames and then an inverse dynamics model to guess actions. Errors in the video accumulate (compounding error), making the inferred actions jittery or wrong.
- Computational Bloat: Jointly denoising video and action is computationally expensive, often running at <1Hz—far too slow for real-world reactive control.
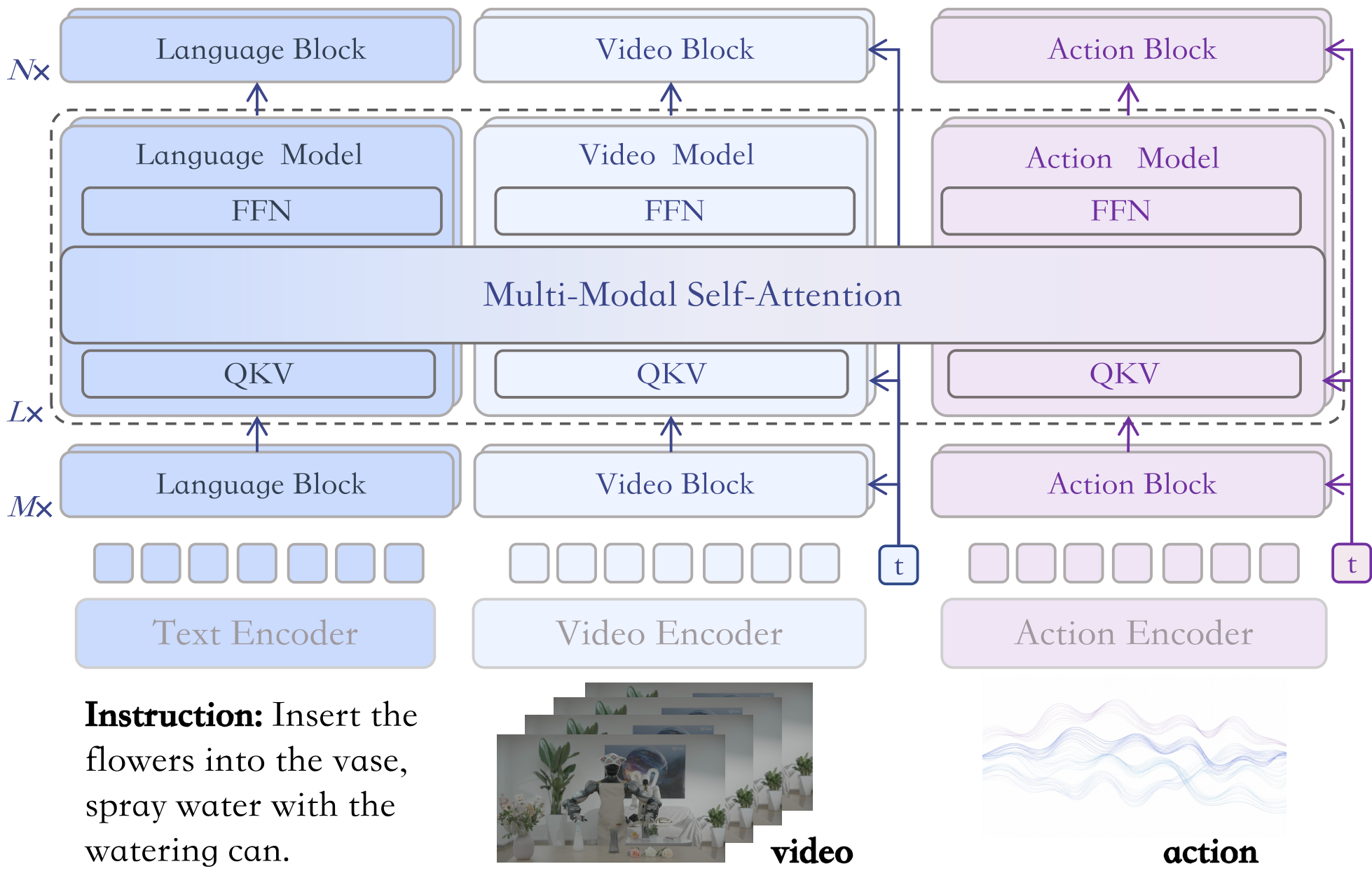
2. Methodology: The Three-Stream H-Bridge
MotuBrain solves these issues through a architectural innovation called the Mixture-of-Transformers (MoT). Unlike a monolithic transformer, it maintains dedicated streams for Text, Video, and Action.
Technical Highlights:
- H-Bridge Architecture: To avoid the "pollution" of modality-specific features, the model limits cross-modal attention to the middle 50% of the layers. The early and late layers remain decoupled, preserving fine-grained visual/action details while allowing the center "bridge" to handle semantic grounding.
- Unified Multiview 3D RoPE: A clever use of 3D Rotary Positional Embeddings allows the model to accept an arbitrary number of camera views without changing the backbone—essential for varied robot embodiments.
- V2A-Style Dependency: During inference, the action tokens attend to video tokens, but not vice versa. This asymmetry is the "secret sauce" for speed: it allows the robot to freeze the video branch after a few steps and only denoise the action branch, drastically reducing FLOPs.
3. Engineering for Real-World Deployment
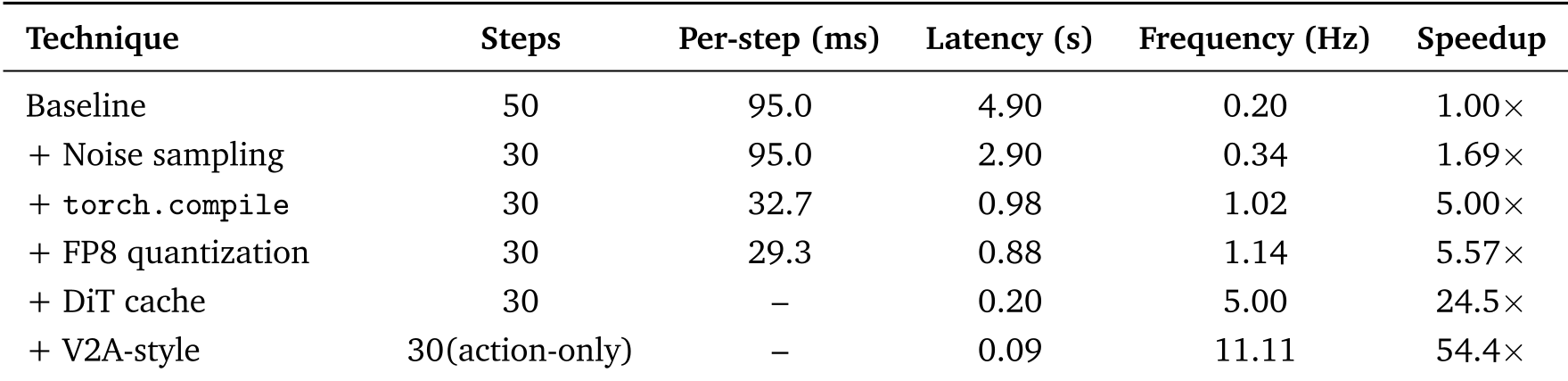
A PhD-level insight from this paper is the 50x Speedup Stack. A "pure" academic model might stop at performance, but MotuBrain focuses on "deployability":
- Denoising Step Reduction: Optimized noise sampling (SNR-based) reduces diffusion steps from 50 to 30.
- DiT Caching: Since consecutive denoising steps are highly similar, the model "skips" redundant evaluations of the transformer blocks using a similarity threshold.
- FP8 + CUDA Graphs: Aggressive quantization and kernel fusion via
torch.compileensure the hardware is fully saturated. - Asynchronous RTC Fusion: To prevent "jitter" at the boundary of action chunks, MotuBrain uses an exponential decay fusion strategy, effectively "stitching" the old and new action sequences together smoothly.
4. Evaluation: Proving Both Perceptual and Functional Power
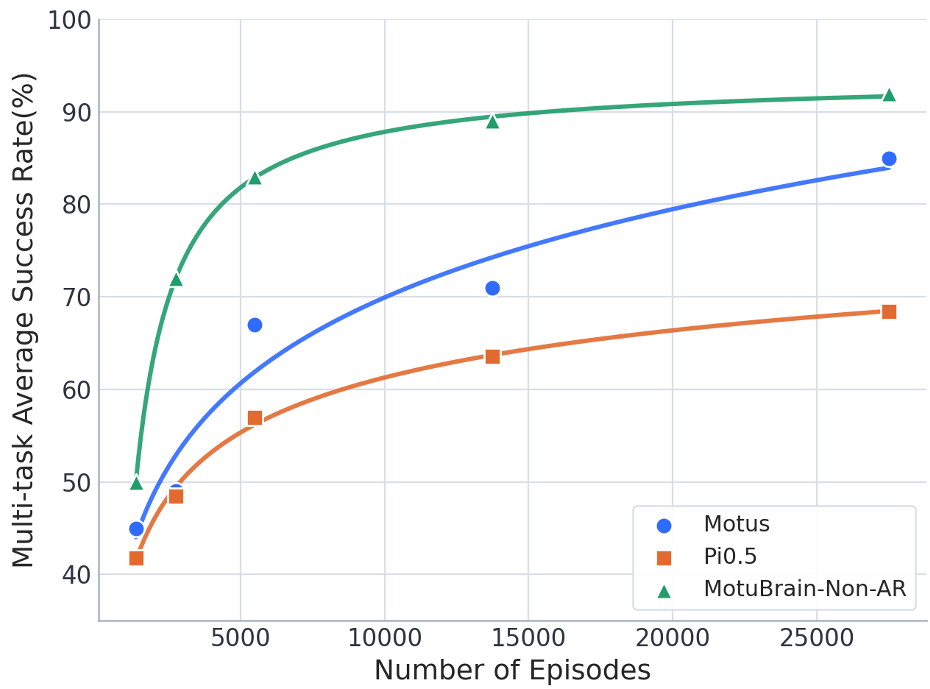
Simulated Dominance
On the RoboTwin 2.0 benchmark, MotuBrain outperformed competitors like π0.5 and LingBot-VA significantly. It is notably the only model to maintain >95% success even in highly randomized scenes, suggesting that its internal "world model" makes it robust to visual noise.
Leading WorldArena
Perhaps the most impressive result is the EWMScore (63.77) on WorldArena. MotuBrain ranks #1 globally, particularly excelling in Motion Quality. It doesn't just generate pretty images; it generates physically plausible motion that transitions naturally from frame to frame.
Real-World Humanoid Versatility
The model was tested on complex, long-horizon tasks such as Mixing Cocktails (124 seconds, 15 atomic actions) and Flower Arrangement. In these trials, the model demonstrated zero-shot retry capabilities. If it failed to insert a flower, it didn't crash; it visually "saw" the failure and re-attempted the action based on its predictive world-state.
5. Critical Analysis & Future Outlook
Takeaways: MotuBrain proves that the future of robotics lies in foundation models of movement. By training on web videos, the robot learns that "gravity exists" and "liquid pours" before it ever touches a real-world cup.
Limitations:
- Data Scarcity: While it reduces the need for robot data, it still requires 50-100 task-specific trajectories for new embodiments.
- Tactile Gap: Visual world models still lack the haptic/tactile feedback loop that high-dexterity manipulation (like threading a needle) requires.
Future Work: We expect to see this framework expanded into Mobile Manipulation (LLM planners + WAM executors) and the integration of broader sensory inputs like tactile sensors or audio to further flesh out the "World Model."