This paper introduces MSFT, an iterative roll-out and roll-back algorithm designed for multi-task Supervised Fine-Tuning (SFT). It addresses the sub-optimality of homogeneous compute allocation by dynamically excluding sub-datasets as they begin to overfit, achieving SOTA performance across 10 benchmarks and 6 base models.
TL;DR
Standard Supervised Fine-Tuning (SFT) treats all data equally, giving every task the same number of epochs. MSFT (Multi-task SFT) proves this is a mistake. By treating dataset mixtures as heterogeneous entities and "ejecting" tasks the moment they start to overfit via an iterative roll-back mechanism, MSFT boosts accuracy by up to +5.4% while often reducing total training FLOPs.
Background: The Hidden Conflict in Data Mixtures
In the race to build frontier models like Qwen, DeepSeek, and Llama, practitioners have converged on a "Homogeneous" training paradigm: mix all your instruction data together and train for a fixed 2 or 3 epochs.
However, the authors of MSFT point out a critical physical intuition: different tasks learn at different speeds. A simple reasoning task might peak at 0.5 epochs, while a complex coding task might need 5. When you force both to 3 epochs, you get a model that is simultaneously overfitted on the former and under-fitted on the latter. This creates gradient conflict, where over-specialized noise from overfitted tasks sabotages the remaining learning tasks.
Methodology: The "Search & Revert" Strategy
The core of MSFT is its Iterative Overfitting-Aware Search. Instead of a naive single-pass search (which fails because removing data changes the optimization trajectory), MSFT uses a more rigorous "Roll-out and Roll-back" loop.
The MSFT Loop:
- Roll-out: Train the model on the current active mixture for a short compute budget $C$.
- Identify: Find the specific sub-dataset $D_{i}$ that reached its peak generalization earliest.
- Roll-back: Revert the entire model parameters $ heta$ to the checkpoint where that specific dataset was at its best.
- Exclude: Remove that dataset from the mixture and repeat until all tasks have peaked.
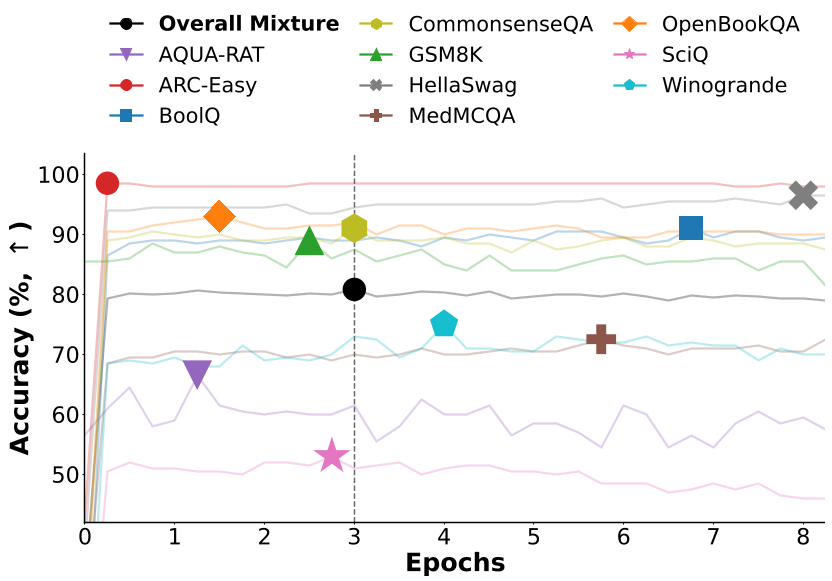 Figure: Evidence of Heterogeneous Overfitting. (a) shows different tasks peaking at vastly different epochs. (b) shows the gap between the global peak and individual task peaks.
Figure: Evidence of Heterogeneous Overfitting. (a) shows different tasks peaking at vastly different epochs. (b) shows the gap between the global peak and individual task peaks.
Experimental Proof: Better Performance, Lower Cost
The authors tested MSFT against established models (OLMo 2, Qwen2.5, Qwen3) across 10 benchmarks.
1. Robust Gains Across Scales
MSFT consistently beat baselines like DynamixSFT (which uses multi-armed bandits) and IES (Instance-dependent Early Stopping). It was particularly effective in Mathematical and Quantitative reasoning, showing a +3.0% absolute gain.
2. Efficiency Paradox
Usually, better performance requires more FLOPs. MSFT breaks this. At a compute budget of $C=1$, MSFT actually lowers the net training cost because it stops training on "completed" tasks early, yet it still outperforms standard SFT.
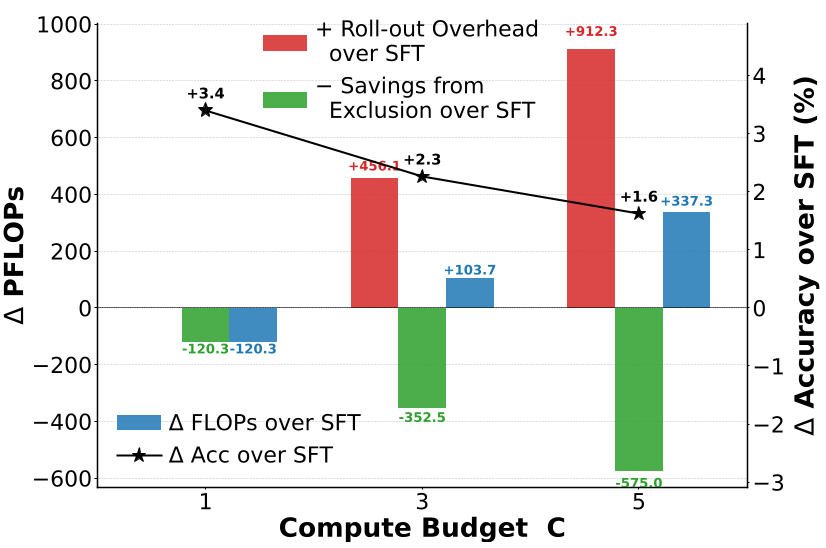 Figure: MSFT (green) provides consistent accuracy gains across various dataset sizes while reducing the standard deviation of performance across tasks.
Figure: MSFT (green) provides consistent accuracy gains across various dataset sizes while reducing the standard deviation of performance across tasks.
Critical Insight: Gradient Conflict Relief
Why does MSFT work so well? The authors hypothesize that it's more than just "early stopping." By removing overfitted tasks, they unburden the optimizer. Once a task passes its optimal point, its gradients become "noisy" and "over-specialized." Excluding these tasks provides a step-wise loss descent for the remaining tasks, as shown in the training loss curves.
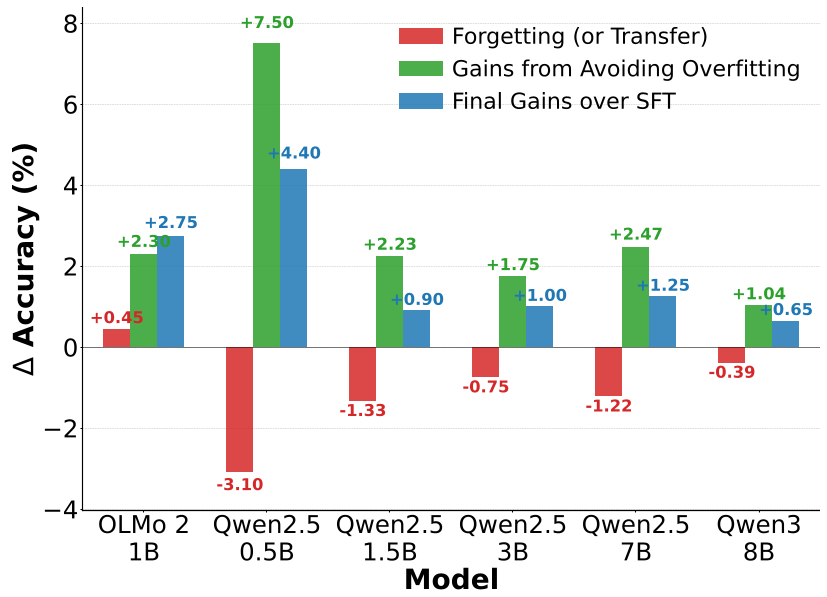 Figure: The "Step-wise" descent. Notice how the loss (red) drops or stabilizes significantly right after a roll-back and exclusion (dashed lines).
Figure: The "Step-wise" descent. Notice how the loss (red) drops or stabilizes significantly right after a roll-back and exclusion (dashed lines).
Conclusion & Takeaways
MSFT reveals a major inefficiency in how we currently train LLMs. The study suggests that:
- Heterogeneity is a Feature, not a Bug: We should embrace the different learning speeds of tasks rather than forcing them into a uniform epoch schedule.
- Disk for Compute Trade-off: MSFT requires saving more intermediate checkpoints (approx. 4.4x more storage), but in modern infra, disk space is cheap while H100 compute time is precious.
For any practitioner looking to squeeze the last 2-3% of performance out of an SFT run, MSFT offers a robust, easy-to-implement alternative to the standard "mix-and-forget" approach.
Limitations
The primary hurdle is the storage overhead. Iterative roll-backs require keeping multiple checkpoints in wait. While the authors proposed an "Efficient Disk Management" variant, it remains more complex to orchestrate than a standard single-run training script.