MFS (Multi-stage Flow Scheduling) is a holistic communication orchestrator for disaggregated LLM serving. It treats KV-cache retrieval, collective communication, and P2D transfers as interdependent stages, achieving a 1.2x–2.4x improvement in TTFT SLO attainment over state-of-the-art baselines.
TL;DR
As LLM serving transitions to disaggregated prefill-decode architectures, the network has become the new bottleneck. MFS (Multi-stage Flow Scheduling) recognizes that generating the first token is not a single event but a multi-stage workflow. By introducing a Reverse Multi-Level Queue (RMLQ) and a "Defer-and-Promote" strategy, MFS prioritizes flows that block GPU computation while deferring non-urgent data transfers, boosting SLO attainment by up to 2.4x.
Background: The Hidden Cost of Disaggregation
To improve throughput, modern systems like vLLM and DistServe separate the Prefill phase (compute-heavy) from the Decode phase (memory-heavy). However, this creates a "communication storm" during the prefill stage:
- Stage 1 (KV-Cache Reuse): Fetching previous context from remote nodes.
- Stage 2 (Collective Comm): Heavy-duty All-to-All or All-Reduce for model parallelism.
- Stage 3 (P2D Transfer): Moving the newly generated KV-cache to decode workers.
Existing schedulers (like SJF or Fair Sharing) are stage-agnostic. They might give high priority to a small P2D transfer (Stage 3), unknowingly starving a critical All-to-All flow (Stage 2) that the GPU is currently idling for. This mismatch between network priority and computational dependency is the primary cause of TTFT (Time-to-First-Token) spikes.
Methodology: The Defer-and-Promote Intuition
The core innovation of MFS is the Reverse Multi-Level Queue (RMLQ). Unlike traditional MLFQ which demotes long-running flows, RMLQ starts flows at low priority and promotes them only as their "laxity" (time remaining before a deadline violation) vanishes.
1. Handling Explicit Deadlines (Stage 3)
For Prefill-to-Decode (P2D) transfers, the deadline is known (the TTFT SLO). MFS uses a metric called Minimal Link Utilization (MLU). If a flow can meet its deadline using only 20% of the link, it is kept in a low-priority queue. As the clock ticks, if it now requires 90% of the link to finish on time, MFS promotes it. This "just-in-time" completion leaves maximum bandwidth for early-stage flows.
2. Handling Implicit Deadlines (Stages 1 & 2)
Early stages don't have a fixed "finish-by" time, but they have a structural dependency. MFS introduces the Relative Layer Index (RLI):
- RLI = 0: The data is needed for the current layer.
- RLI > 0: The data is needed for a future layer.
MFS strictly prioritizes flows with the smallest RLI. This ensures that the GPU never waits for data that could have been transferred earlier.
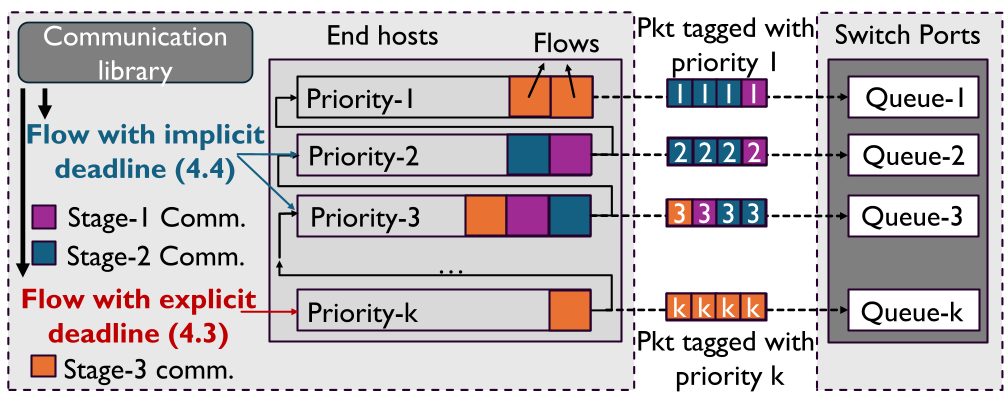 Figure: The RMLQ Architecture, illustrating how different stages are mapped to priority queues based on urgency.
Figure: The RMLQ Architecture, illustrating how different stages are mapped to priority queues based on urgency.
Evaluation: Efficiency at Scale
The authors tested MFS on a 32-GPU cluster and scaled simulations. The results are striking:
- Collective Completion Time (CCT): Reduced by ~50%. By protecting Stage 2 flows, MFS keeps the GPUs saturated.
- SLO Attainment: MFS handles 1.2x to 1.4x higher request rates than Karuna (the previous state-of-the-art) while maintaining the same SLO hit rate.
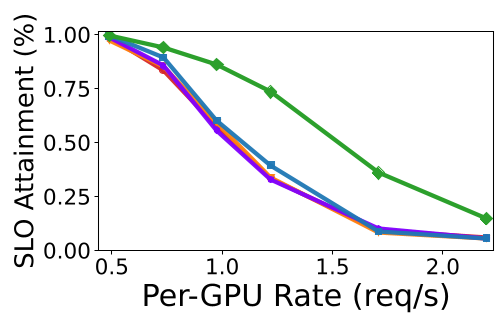 Figure: MFS consistently outperforms SJF, EDF, and Karuna across different MoE models (Mixtral, DBRX, Grok).
Figure: MFS consistently outperforms SJF, EDF, and Karuna across different MoE models (Mixtral, DBRX, Grok).
Critical Insight: Why it Works
The "magic" of MFS isn't just about speed; it's about regulating earliness. Traditional schedulers try to finish every flow as fast as possible. MFS realizes that finishing a Stage 3 flow "too early" is actually harmful if it creates contention that delays a Stage 2 flow. By "delaying the non-urgent," MFS creates a "communication lane" for the critical path of the prefill DAG.
Conclusion
MFS proves that as AI models grow, the distinction between "network engineering" and "ML systems" is blurring. To achieve sub-second TTFT in global-scale LLM clusters, our network switches must become aware of the Transformer's layer-by-layer execution logic. MFS provides the blueprint for this transition.
Limitations: The current implementation relies on a centralized coordinator for inter-node tie-breaking, which might face scalability challenges in clusters with tens of thousands of GPUs. Future work could explore decentralized laxity estimation.