本文提出了 MuRF (Multi-Resolution Fusion),一种针对视觉基础模型 (VFMs) 的简单且普适的推理阶段增强策略。该方法通过在推理时融合不同分辨率的图像特征,在 DINOv2 和 SigLIP2 等模型上实现了多项视觉任务的 SOTA 成就。
TL;DR
在计算机视觉进入大模型时代后,我们习惯于直接调用冻结的视觉基础模型(VFM)特征。然而,传统的推理流程通常采用单一分辨率。来自威斯康星大学麦迪逊分校的研究团队提出 MuRF (Multi-Resolution Fusion),通过在推理时融合不同尺度的特征图,巧妙地解决了“全局识别”与“局部修复”之间的固有权衡。实验证明,这一策略在语义分割、深度估计、VQA及异常检测等任务中均表现出显著的增益。
1. 痛点:单尺度的“顾此失彼”
当前的视觉感知系统存在一个被长期忽视的痛点:Resolution Dilemma (分辨率困境)。
- 低分辨率 (Low-res):较大的感受野能提供清晰的物体全貌,擅长语义识别,但边界模糊。
- 高分辨率 (High-res):提供丰富的边界细节,但在处理大面积物体内部时,由于缺乏全局上下文,往往会产生预测漏洞(Holes)或噪声。
现有的方法(如 DINOv2)虽然允许输入变长,但在推理时多选择某一固定尺度,这导致要么丢了全局,要么失了细节。
2. 核心直觉:Recognition vs. Refinement
作者提出的核心构思在于“分工”。如下图所示,在不同分辨率下,模型生成的特征图表现出截然不同的特性:
 Figure 1: 较低分辨率确保全局一致性(识别),较高分辨率确保边缘锐化(细化)。
Figure 1: 较低分辨率确保全局一致性(识别),较高分辨率确保边缘锐化(细化)。
3. 方法论详解:Simple is Advanced
MuRF 的架构流程可以用“金字塔采样 -> 冻结提取 -> 通道拼接”来概括:
3.1 多分辨率特征融合
- 构建金字塔:将输入图像缩放为不同比例(如 0.5x, 1.0x, 1.5x)。
- 特征提取:将这些图像输入同一个冻结的视觉编码器(如 DINOv2 或 SigLIP2)。
- 对齐与拼接:将不同尺度的特征图通过双线性插值上采样到同一空间尺寸,并进行 Channel-wise Concatenation。
为什么要用 Concatenation 而不是相加? 作者给出了极具深度的物理直觉:ViT 的特征是高度本地化的。如果直接物理相加(Summation),可能会导致“破坏性干涉(Destructive Interference)”,即宏观语义信号与微观边缘信号产生干扰。而通道拼接在更高维空间保留了信号的独立性,让下游的感知头(Head)自己去做“路由”。
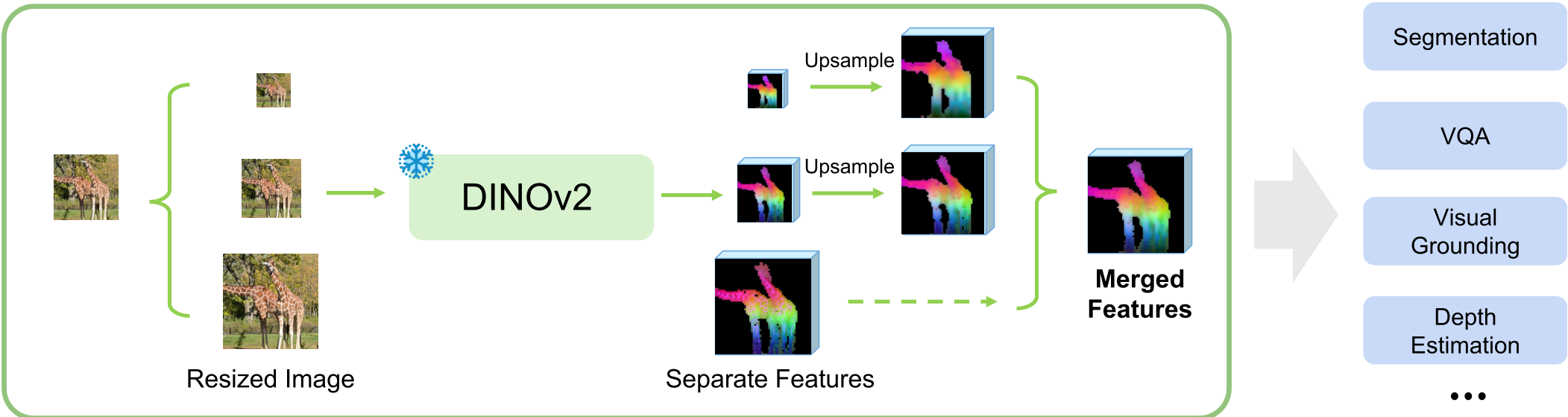 Figure 2: MuRF 架构概览,展示了从特征提取到多任务适配的过程。
Figure 2: MuRF 架构概览,展示了从特征提取到多任务适配的过程。
4. 实验战绩
MuRF 的强大之处在于其** universality (普适性)**。研究团队在四个完全不同的赛道上验证了其有效性:
4.1 密集预测(分割与深度)
在 ADE20K 和 Pascal VOC 上,MuRF 的线性 Probe 精度大幅超越单尺度 DINOv2。在 NYU Depth V2 深度估计中,MuRF 的 RMSE 误差通过多尺度互补降到了最低水平。
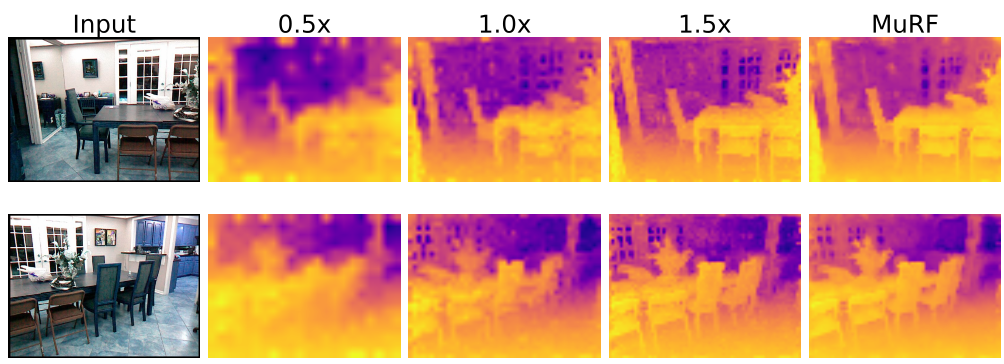 Figure 3: 定性结果显示,MuRF(右侧)在保持全局结构完整的同时,边界处理比单尺度版本更干净。
Figure 3: 定性结果显示,MuRF(右侧)在保持全局结构完整的同时,边界处理比单尺度版本更干净。
4.2 多模态 LLM 增强
在 MLLM(如 LLaVA)中,MuRF 将多尺度特征拼接到视觉 Token 的通道中。关键创新是:这种做法不增加序列长度! 这意味着它不会给 LLM 带来额外的计算负担,却让模型获得了同时观察微观细节和宏观场景的能力。
4.3 工业异常检测 (Training-free)
在 MVTec AD 2 数据集上,MuRF 无需任何参数微调,通过简单的多分辨率异常分值平均,即在检测微小划痕和大面积结构缺陷之间找到了完美平衡。
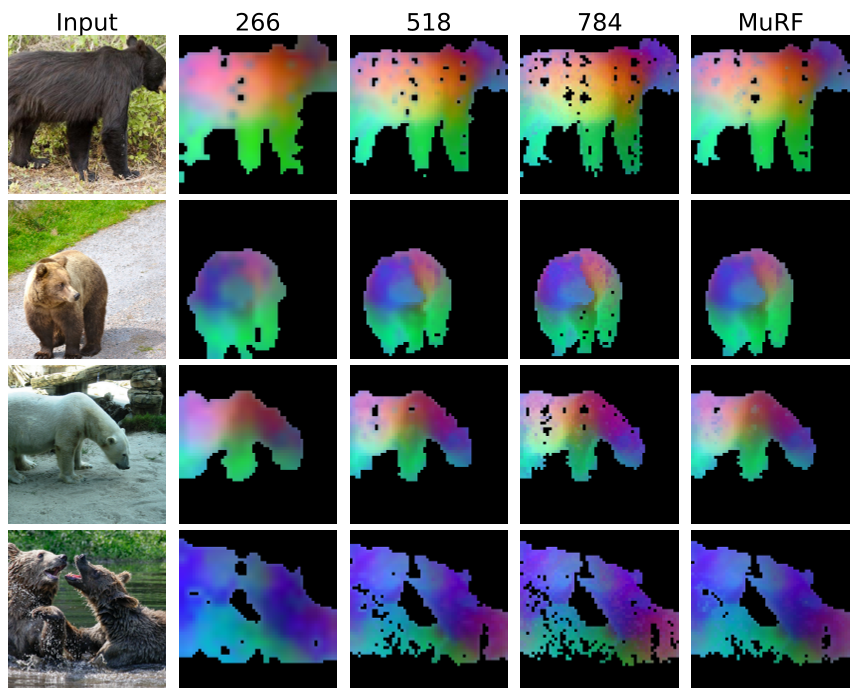 Figure 4: MuRF AD 成功合并了低分辨率的稳健定位与高分辨率的精准掩膜。
Figure 4: MuRF AD 成功合并了低分辨率的稳健定位与高分辨率的精准掩膜。
5. 局限性与展望
尽管 MuRF 效果显著,但其主要局限在于推理时的显存占用和延迟。由于需要多次前向传递,其推理延迟约为单尺度的 2.6 倍。未来的研究方向可能涉及:
- 计算修剪:如何识别不必要的分辨率区域。
- 架构集成:将 MuRF 的思想直接融入 VFM 的初始设计中,实现在单次前向传递中完成多分辨率融合。
6. 总结
MuRF 的意义在于它重新审视了视觉感知中最朴素的“金字塔”原理,并将其带入了 VFM 时代。它告诉我们,与其追求更复杂的模型架构,不如通过更智能的推理策略来充分挖掘现有模型的潜力。