The paper introduces Nexus, a novel second-order gradient-based optimization framework designed for Large Language Model (LLM) pretraining. It demonstrates that by maximizing gradient similarity across diverse data sources to reach a "common minima," models can achieve significantly better downstream generalization and out-of-distribution (OOD) performance while maintaining the same pretraining loss.
TL;DR
LLM pretraining usually treats all data as one big average, but this hides a geometric inefficiency. Nexus is a new optimizer wrapper that forces the model to find the "consensus" point between different data sources (code, math, text). The result? A model that achieves the same pretraining loss as AdamW but executes logic and reasoning tasks with up to 15% higher accuracy. It proves that where you land in the loss landscape matters as much as how low you go.
The Geometric Insight: Sum vs. Intersection
When training on multiple domains , we usually minimize . Mathematically, there are two ways to achieve a low total loss:
- Sum of Minima: The model finds a "middle ground" that is actually far from the ideal point of any single task. (High variance, poor OOD generalization).
- Intersection of Minima (Nexus): The model finds a point that is geometrically close to the specific minimizers of all tasks. (Low variance, superior generalization).
The authors hypothesize that Closeness—the distance between these task-specific minima—is a key second-order property for generalization, alongside the well-known property of Flatness.
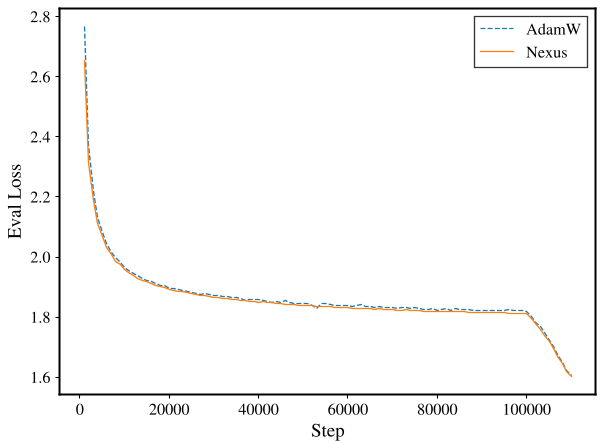 Figure 1: (a) Distant minima lead to poor OOD performance; (b) Close/Intersecting minima lead to a common low-loss region for downstream tasks.
Figure 1: (a) Distant minima lead to poor OOD performance; (b) Close/Intersecting minima lead to a common low-loss region for downstream tasks.
Methodology: How Nexus Finds the Sweet Spot
Directly calculating the distance to every task's ideal minimum is computationally impossible. Nexus circumvents this by using Gradient Similarity as a proxy.
The Intuition: If the gradients of Task A and Task B always point in the same direction, their minima must be in the same place.
Nexus implements this via a Dual-Loop Mechanism:
- Inner Loop: Performs a few steps of Normalized SGD to see where the gradient is "heading" across different mini-batches.
- Outer Loop: Uses the "displacement" (the difference between the start and end of the inner loop) as a pseudo-gradient. This displacement naturally contains the Hessian-gradient product, which effectively maximizes the cosine similarity between task gradients.
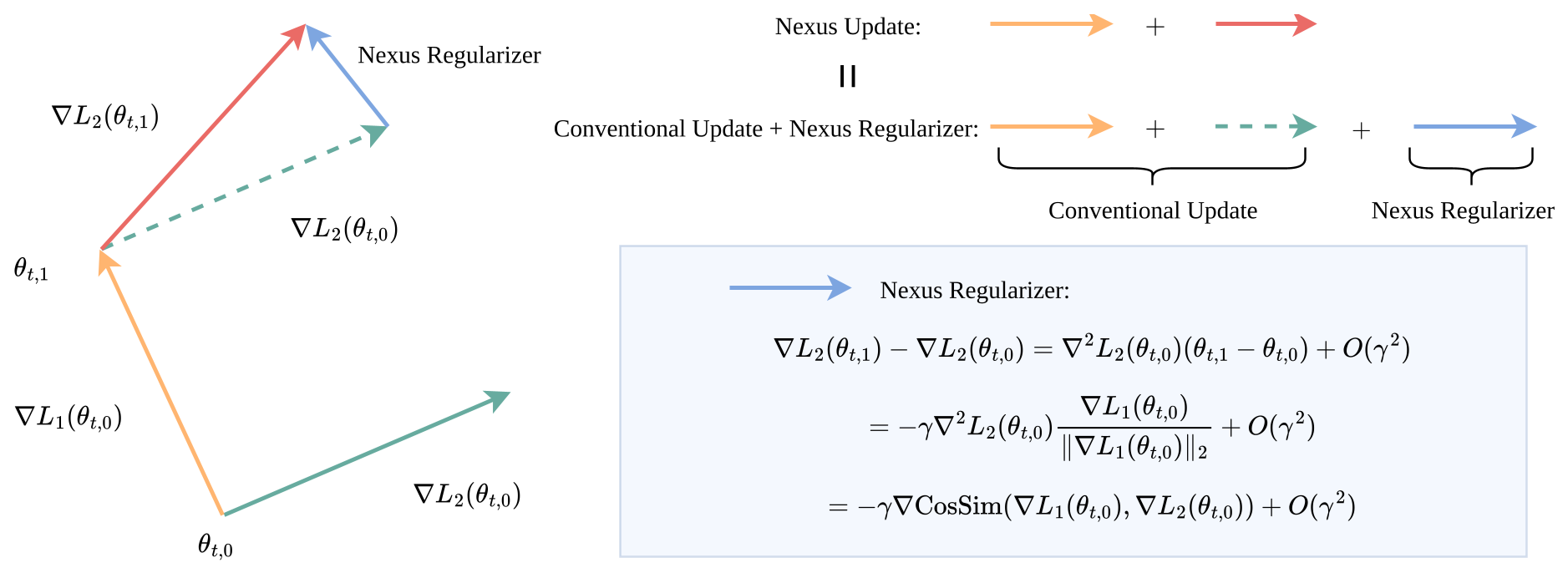 Figure 2: The inner loop displacement (red) acts as a regularizer that pulls the model toward the axis of consensus.
Figure 2: The inner loop displacement (red) acts as a regularizer that pulls the model toward the axis of consensus.
Experimental Results: Scaling the Generalization Gap
The most striking aspect of Nexus is that it offers a "free lunch" in terms of pretraining loss. Across various model sizes (130M to 3B), the pretraining loss curve for Nexus is virtually indistinguishable from AdamW, yet the downstream benchmarks tell a different story.
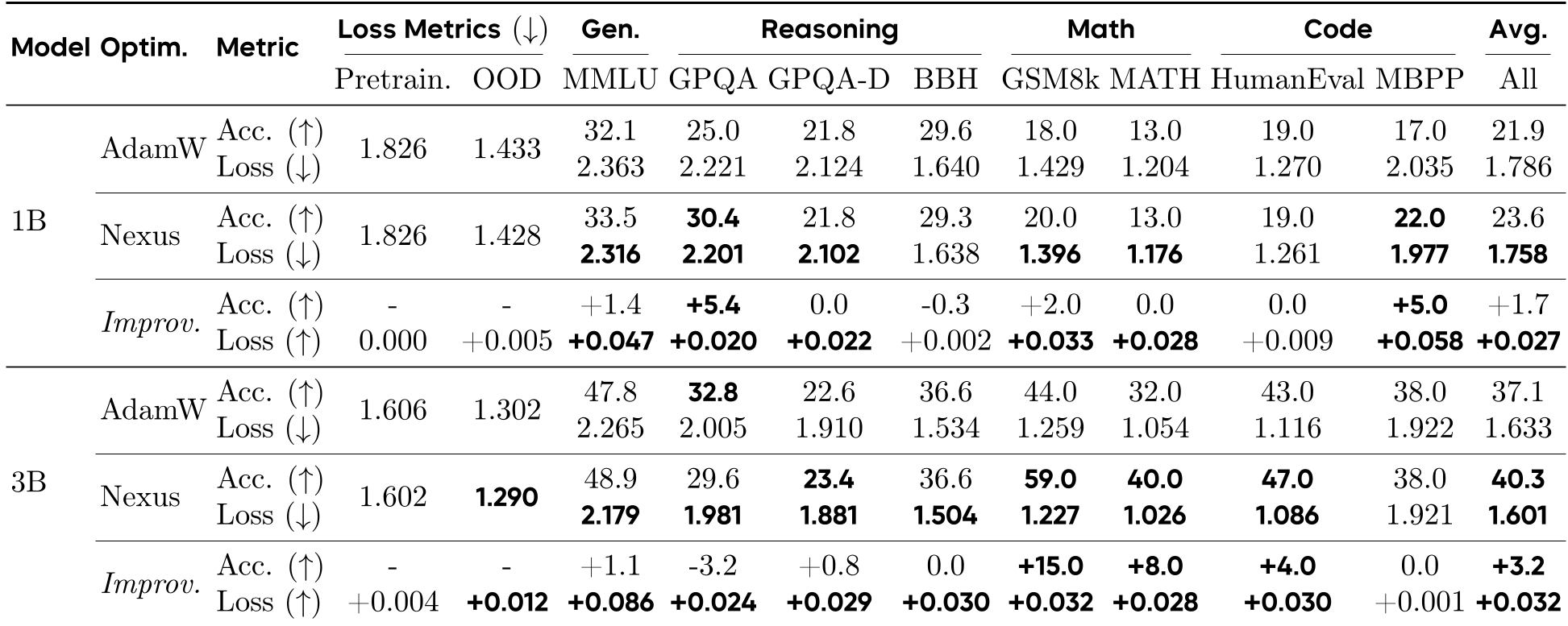
Key Performance Metrics (3B Model):
- GSM8k (Math Reasoning): +15.0% Accuracy.
- MATH500: +8.0% Accuracy.
- HumanEval (Coding): +4.0% Accuracy.
- OOD Validation Loss: -0.012.
Scaling Findings
The advantage of Nexus amplifies with scale. As models get larger and are trained on more tokens (up to 4x Chinchilla), the gap between Nexus and standard AdamW widens. This suggests that as models become more over-parameterized, they have more "geometric freedom" to choose a consensus-based path without sacrificing training efficiency.
Critical Analysis & Conclusion
The success of Nexus challenges the industry's reliance on "Validation Loss" as the definitive metric for model progress during pretraining. It reveals that two models with the exact same loss can have vastly different capabilities depending on the implicit bias of the optimizer.
Limitations:
- Optimizer Incompatibility: Nexus currently doesn't play well with Muon (a recent orthogonal optimizer), possibly due to complex interactions with Newton-Schulz iterations.
- Memory Overhead: It requires maintaining an auxiliary
inner_model, though the authors suggest this can be mitigated with CPU offloading.
Future Outlook: As LLM pretraining moves from being compute-bound (waiting for GPUs) to data-bound (finding high-quality data), optimizing the path the model takes through that data becomes paramount. Nexus is a significant step toward a generation of optimizers that don't just memorize data, but find the shared logic between domains.