本文由 NVIDIA 团队提出,证明了归一化架构 nGPT(将权重点和隐藏表示约束在单位超球面上)天生具备 4-bit 训练的鲁棒性。该方法利用 NVFP4 数据格式实现了稳定的端到端训练,并在 1.2B 稠密模型及高达 30B 参数的混合 Mamba-Transformer MoE 模型上达到了 SOTA 性能。
TL;DR
传统的 LLM 4-bit 训练就像是在碎冰上行走,需要 RHT 和动态缩放等复杂技术来防止崩溃。NVIDIA 的这项最新研究表明,nGPT(归一化 Transformer)架构天然就是“量化就绪”的。通过将权重和激活约束在单位超球面上,nGPT 不仅去除了繁琐的量化补丁,还在 NVFP4 格式下实现了极高的信号累积效率。这意味着在大维度的 LLM 时代,模型越宽,nGPT 的优势就越不可撼动。
1. 痛点:为什么 4-bit 训练这么难?
在大模型向万亿参数规模迈进时,使用物理原生的 4-bit(如 NVIDIA Blackwell 支持的 NVFP4)进行训练至关重要。然而,标准 GPT 架构在极低比特下极易“炸模型”。
- 离群值(Outliers):标准模型倾向于让少量坐标拥有极大的数值,这些离群值在 4-bit 量化下会造成巨大的截断误差。
- 补丁繁琐:为了修补这一问题,目前的主流方案是引入随机 Hadamard 变换(RHT)来打散热点,或者使用昂贵的逐张量动态缩放。
NVIDIA 团队追问了一个根本性问题:我们能否设计一种架构,不需要任何补丁就能天然抵抗量化误差?
2. 核心机制:从“噪声压制”到“信号累积”
nGPT 架构通过将隐藏状态和参数强制限制在单位超球面上,改变了这一现状。
2.1 令人惊讶的发现
研究者通过层级结构分析发现:在单个元素级别,nGPT 的量化噪声并不比 GPT 小。真正的奇迹发生在求和阶段(Summation)。
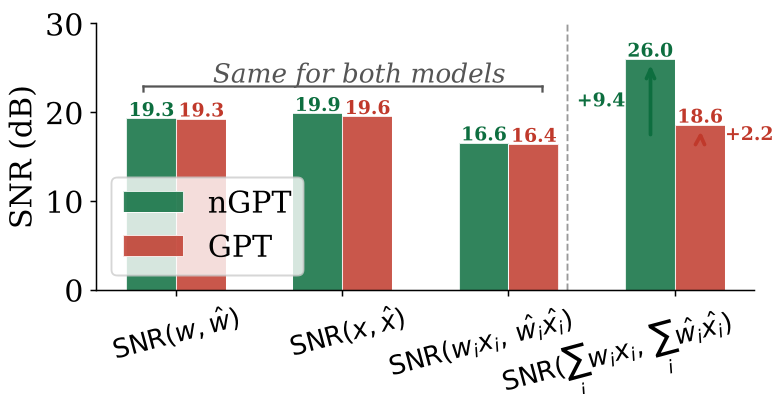 图 1:左图显示归一化信号 是信噪比的强预测因子;右图显示量化噪声在两种架构中几乎一致。
图 1:左图显示归一化信号 是信噪比的强预测因子;右图显示量化噪声在两种架构中几乎一致。
2.2 信号的“共鸣”
在标准 GPT 中,各个维度的信号是杂乱无章的。但在 nGPT 中,由于单一维度无法无限扩张(被归一化限制),优化器被迫学习出一种“集体协作”模式——成千上万个维度之间产生了微弱但一致的正相关(Positive Correlation)。 当这些正相关项在长达 或更长的向量空间内求和时,有效信号会相干累积(Constructive Accumulation),而噪声则因互不相关而相互抵消。结果是:点积运算后的信噪比(SNR)大幅提升。
3. 架构优势详解
3.1 模型架构的微调
nGPT 对 Transformer 做了“减法”和“加法”:
- 减法:去掉了 RMSNorm/LayerNorm,去掉了 Learning Rate Warmup 和权重衰减(Weight Decay)。
- 加法:在每一层的残差连接位置引入了单位超球面投影。
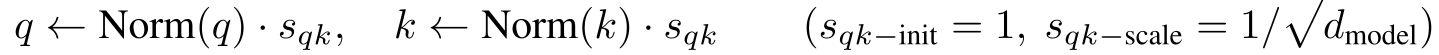
3.2 随宽度扩展的“宽度利好”
论文提出了一个关键的 Scaling 定律:nGPT 的 SNR 优势会随着维度 的增加而线性增长。在当前主流的 405B 模型规模下(),nGPT 的信噪比优势预计将达到 10 倍以上。
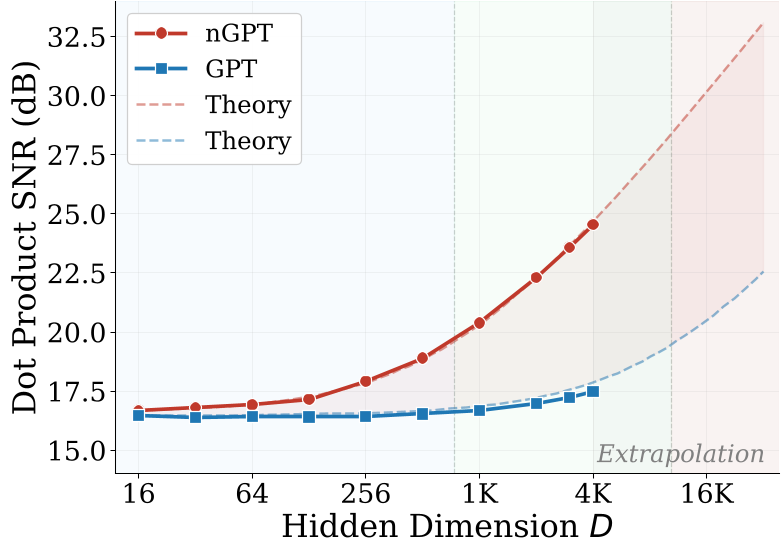 图 2:随着求和长度 的增加,nGPT 与 GPT 的 SNR 差距(右图绿色区域)线性扩大。
图 2:随着求和长度 的增加,nGPT 与 GPT 的 SNR 差距(右图绿色区域)线性扩大。
4. 实验结果:全方位的胜出
在 1.2B 稠密模型和 3B/30B 的混合 Mamba-Transformer MoE 模型上,nGPT 展现了极强的统治力:
- 损失更低:在相同 Token 数下,
n-nvfp4(无补丁)的 Loss 甚至低于带补丁的nvfp4基线。 - 超参鲁棒性:nGPT 对学习率(LR)极不敏感。实验显示,它的 BF16 最优学习率可以直接迁移到 NVFP4,无需重新调优,而标准 GPT 的最优 LR 会偏移 16 倍。
- 显著加速:在 Blackwell GPU 上,由于去掉了 RHT 等开销,nGPT 实现了 3.3x - 3.6x 的端到端推理提速。
5. 深度洞察与总结
这项工作为我们理解深度学习提供了一个新视角:几何约束(Geometric Constraint)可以转化为数值鲁棒性。
局限性与展望
尽管 nGPT 在 4-bit 上表现完美,但由于其彻底改变了残差连接和归一化的逻辑,现有的预训练权重无法直接通过简单的微调(Finetune)转换,必须从头预训练。此外,未来研究还需要进一步探索为什么归一化架构会天然诱导维度间的正相关性。
总结 (Takeaway):nGPT 证明了通过优雅的数学约束(单位超球面),我们可以让大模型在极低精度下依然保持“头脑清晰”。在低功耗算力竞逐的未来,这种“自带鲁棒性”的架构将成为主流。