本文提出了 Nora,一种针对大语言模型(LLM)训练设计的矩阵优化器。该方法通过将动量投影到权重的行正交补空间并进行行归一化,实现了类 Muon 的预处理效果,同时严格遵循神经网络的尺度不变性(Scale-invariance)。
TL;DR
在 LLM 训练领域,追求极致的数据效率已成为共识,Muon 等矩阵优化器虽强但计算昂贵。本文介绍的 Nora (Normalized Orthogonal Row Alignment) 优化器,通过简洁的行向投影与归一化,在保持 线性复杂度的同时,完美解决了训练稳定性与尺度不变性(Scale-invariance)的问题。实验表明,Nora 不仅在最终收敛指标(Loss/PPL)上超越了 Muon 和 RMNP,其运行速度更是比 Muon 快了数十倍。
背景定位:为何现有的矩阵优化器不够理想?
现代神经网络广泛使用归一化层(RMSNorm/LayerNorm),这使得模型权重具备尺度不变性——即权重的模长变化不会改变输出函数,有效的学习其实是发生在一个球面或流形上的“角度运动”。
目前的矩阵优化器存在显著缺陷:
- Muon:依赖 Newton-Schulz 迭代进行正交化,计算耗时巨大(),难以在大规模 MLP 层中扩展。
- RMNP:虽然通过简单的行归一化加速了预处理,但它忽略了径向(Radial)噪声,导致权重模长剧烈震荡,破坏了有效学习率。
Nora 的核心直觉在于:既然只有角度运动才对 Loss 有贡献,我们干脆把所有不在切空间内的更新分量全部裁掉,并且利用 Hessian 矩阵的结构特性来极速近似预处理。
核心算法:两行代码的几何美学
Nora 的设计遵循三个核心原则:效率(效率预处理)、稳定性(尺度不变性)和速度(低复杂度)。
1. 投影(Stability)
首先,将动量 投影到与权重 行向垂直的空间: 这一步过滤掉了无效的径向噪声,确保更新不会引起权重模长的无序膨胀。
2. 预处理与归一化(Efficiency & Speed)
利用 Transformer Hessian 矩阵具有“行块对角占优”的先验知识,Nora 证明了复杂的矩阵预处理在数学上可以等价简化为简单的行归一化(Row Normalization):
(上图展示了 Nora 如何通过行投影保持更新方向与权重的正交性)
实验结果:速度与质量的双重飞跃
1. 更好的收敛曲线
在 135M 模型的训练中,Nora 在训练后期展现出了明显的后发优势。相比 Muon 和 Mano,Nora 的 Loss 下降更加平滑且最终达到的水平更低。
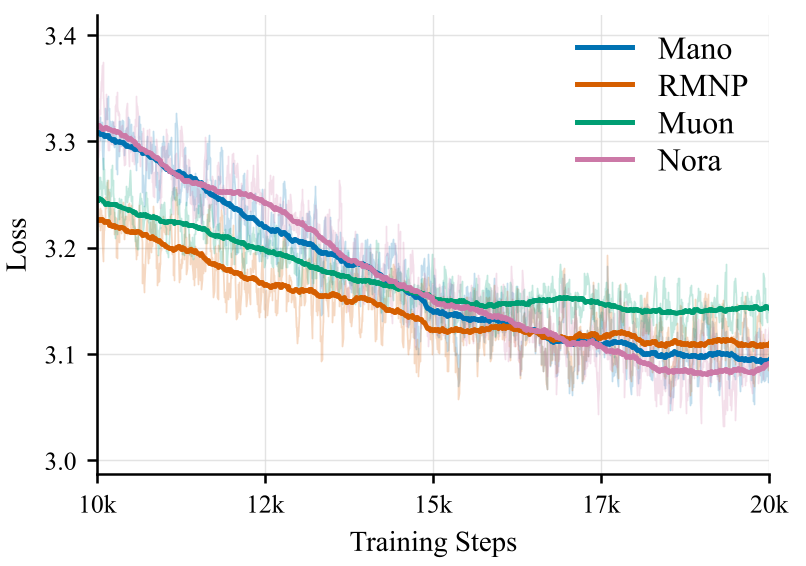
2. 压倒性的运行速度
在 1B 规模模型的测试中,Muon 的 Newton-Schulz 迭代成为了显著的瓶颈,而 Nora 维持了极低的计算开销。在某些层中,Nora 的效率比 Muon 提升了 73 倍。
| 模型规模 | 代表层类型 | Nora 行归一化耗时 (ms) | NS(5) 耗时 (ms) | 速度提升倍数 | | :--- | :--- | :--- | :--- | :--- | | 1B | MLP (intermediate × hidden) | 0.0985 | 6.9985 | 71.02× | | 1B | MLP (hidden × intermediate) | 0.1084 | 7.9678 | 73.51× |
理论支柱:从数学到扩展定律
Nora 不仅仅是一个工程 Trick。作者基于 Maximal Update Parametrization (µP) 框架,严谨地论证了 Nora 的学习率缩放法则(Scaling Law):
- 结论:为了保持激活值的更新强度在模型宽度 增加时保持稳定,Nora 的学习率应遵循 的缩放规律。
- 收敛保证:论文在非凸环境下证明了 Nora 的收敛性,并指出了行正交投影算子的非扩张性。
深度洞察与总结
Nora 的成功揭示了:在高维神经网络训练中,尊重参数空间的几何几何结构往往比使用复杂的数学迭代更有效。
Takeaways for Practitioners:
- 即插即用:Nora 仅需两行代码即可集成到现有训练流程。
- 无需权重衰减:实验中 Nora 即使在 Weight Decay = 0 的情况下依然表现稳健。
- 局限性:目前的实验主要集中在 1B 以下规模,更大规模(7B, 70B)上的稳定性仍待进一步验证。
总的来说,Nora 是目前 matrix-based 优化器路线中一个极具竞争力的选手,它用最简单的行列对齐操作,实现了比肩甚至超越复杂二阶优化器的性能。