本文提出了 FrameCrafter,一种将预训练视频扩散模型(Video Diffusion Models)转化为稀疏视角新视点合成(Sparse NVS)模型的方法。通过将 NVS 任务公式化为一种“无序视频补全”任务,FrameCrafter 在仅使用 1k 个场景数据进行轻量级 LoRA 微调的情况下,达到了超越主流图像扩散模型(如 SEVA)的 SOTA 性能。
TL;DR
传统的稀疏新视点合成(Novel View Synthesis, NVS)一直苦于“几何一致性”难做,不得不烧掉海量多视图数据。卡内基梅隆大学(CMU)的研究团队在最新论文中提出了 FrameCrafter,其核心观点极具冲击力:视频生成模型本身就是完美的 3D 先验,我们只需要教它“忘掉时间”即可。
通过对预训练视频模型(如 Wan2.1)进行几项精巧的结构手术,FrameCrafter 仅用 1000 个场景的训练量,就吊打了那些在 80,000 个场景上训练的、基于图像扩散模型的 SOTA 方法。
痛点深挖:图像模型缺几何,视频模型带偏见
当前的生成式 NVS(如 SEVA, Zero-1-to-3)大多基于图像扩散模型(SD1.5/2.1)。但问题是,单图预训练模型根本不懂什么是“视角变换”,它们的一致性是靠后期暴力喂多视图数据硬刷出来的。
视频模型(Video Diffusion)由于见过物体旋转、相机移动带来的连续画面,天生自带空间一致性,看似是 NVS 的救星。然而,视频模型有两个“毒点”:
- Causal Bias(因果偏见):视频模型认为帧是有序的(1→2→3),但 NVS 的输入视图是无序的(Permutation Invariant)。
- Temporal Compression(时间压缩):视频 VAE 为了效率会将多帧合为一个隐向量,这会损失稀疏视图中的细微几何细节。
Methodology:如何让视频模型“去时间化”?
FrameCrafter 的核心思路是将 NVS 任务重定义为一个 低帧率的视频补全任务,但通过以下三个手段强行抹除模型的时间感:
1. 独立 VAE 编码 (Per-View Independent Encoding)
传统的视频 VAE 使用因果 3D 卷积。FrameCrafter 强制将每一个输入视图都当做“视频的第一帧”进行独立编码。这样做有两个好处:
- 保证了无论输入视图怎么排序,得到的隐空间特征完全一致(置换不变性)。
- 避免了时间维度的下采样,保留了每一张输入图的原始空间精度。
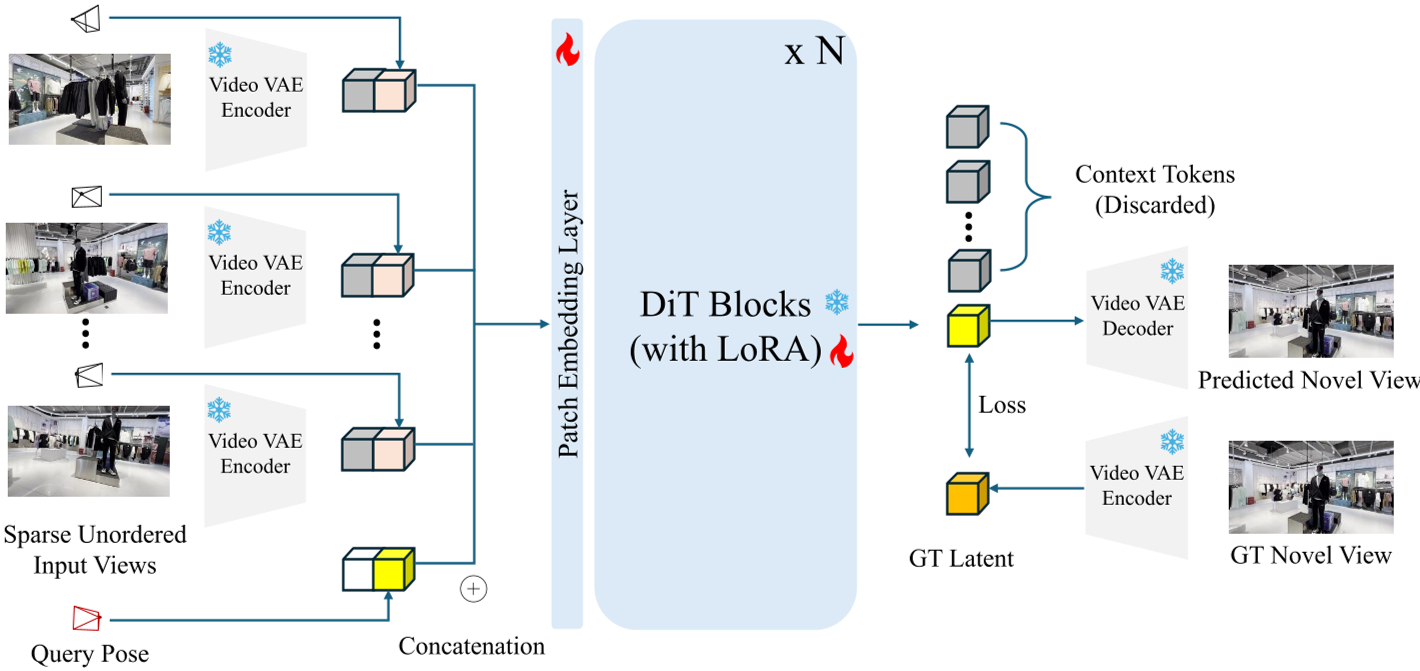 Fig. 1: FrameCrafter 整体架构。注意到输入视图经过独立的 VAE 编码后,与 Plücker 射线图拼接,送入去除了时间位置编码的 Transformer。
Fig. 1: FrameCrafter 整体架构。注意到输入视图经过独立的 VAE 编码后,与 Plücker 射线图拼接,送入去除了时间位置编码的 Transformer。
2. 精准的相机控制:Plücker Raymaps
为了让模型知道查询视角在哪里,作者引入了 Plücker 射线表示。特别的是,他们抛弃了以“第一帧为原点”的标准做法,转而采用以“目标查询视图”为中心的坐标系对齐。这不仅进一步确保了无序性,还让模型推理更聚焦于当前要生成的视角。
3. 移除时间位置编码 (Zero-Temporal RoPE)
视频模型常用的 3D Rotary Positional Embeddings (RoPE) 会给每一帧打上时间戳。FrameCrafter 直接扔掉了时间戳,只保留空间位置编码。这意味着模型在 Transformer 层中只能依靠“相机射线”来分辨不同视图的几何位置,从而彻底从“时间流”中解放出来。
实验与结果:数据效能的降维打击
FrameCrafter 的实战表现令人震惊。在使用相同的 6 视图输入条件下,对比结果如下表:
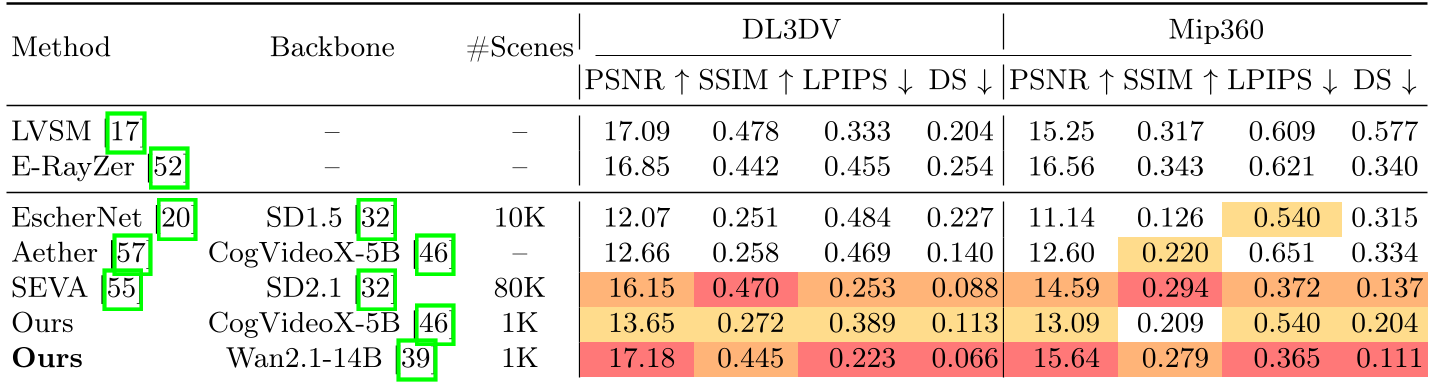
- 以少胜多:基于 Wan2.1-14B 的模型仅用 1K 场景训练,在 DL3DV 榜单上的 PSNR (17.18) 超过了用 80K 场景训练的 SEVA (16.15)。
- 极简泛化:即便只用 20 个场景 进行 LoRA 微调(见下图),它的表现居然也比在 10,000 个场景上训练的 EscherNet 强。这有力地证明了:几何知识早已在视频预训练阶段就在模型脑子里“长”好了,微调只是在教它如何表达。
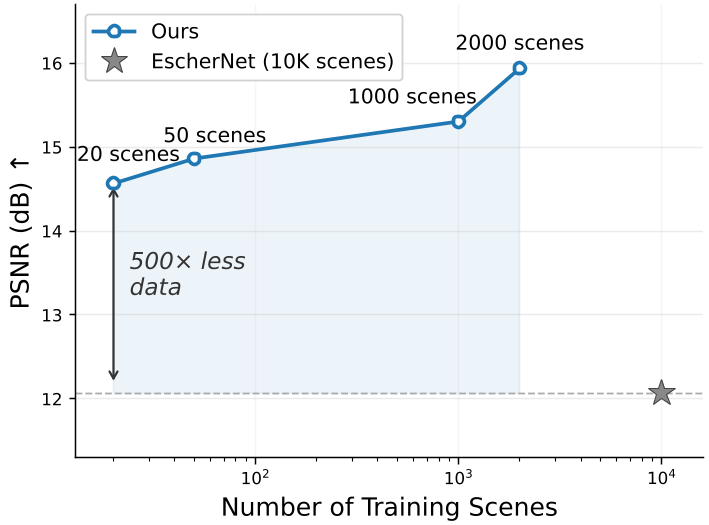 Fig. 2: 训练场景数量与性能的关系。即便极少量数据,视频模型展现出的先验力量也极其惊人。
Fig. 2: 训练场景数量与性能的关系。即便极少量数据,视频模型展现出的先验力量也极其惊人。
深度洞察:视频模型是“世界模型”吗?
本文最引人深思的观点在于:现在的视频生成模型,比起“理解运动”,似乎更擅长“理解几何”。
作者发现,轻而易举地就能让视频模型“忘掉”时间逻辑转而处理纯粹的空间几何,这暗示了视频模型在处理海量互联网视频时,由于必须维持跨帧一致性,其内部隐式地学到了一套 3D 表征。对于 NVS 领域来说,这可能意味着以后不再需要昂贵的多视图数据集(如 Objaverse-XL),只需在大规模无标注视频上预训练,再辅以少量 3D 标注进行“激活”即可。
总结
FrameCrafter 成功地将视频扩散模型的强大生成能力迁移到了稀疏 NVS 任务中。它不仅刷新了数据效率的纪录,更揭示了视频大模型作为 3D 几何先验的巨大潜力。
局限性:虽然精度极高,但毕竟是 Diffusion 架构,推理速度(特别是 14B 参数级别)相比于传统的回归方法(如 LVSM)仍然偏慢,且对于极端的视角外扩(Exterpolation),仍可能出现幻觉。
未来的研究方向很明确:如何将这种视频先验进一步轻量化,并引入到实时渲染(如 3DGS 结合)的管线中。