本文提出了 OA-WAM,一种基于对象寻址机制(Object-Addressable)的世界动作模型。通过将场景分解为结构化的 Slot 状态并在 Transformer 架构层面解耦对象身份与时变内容,OA-WAM 在 LIBERO 和 SimplerEnv 等机器人操控基准测试中刷新了 SOTA 纪录。
TL;DR
清华大学、上海交大等机构的研究团队推出了 OA-WAM (Object-Addressable World Action Model)。该工作指出,当前机器人策略在面对相机视角变换、背景替换等轻微扰动时极易崩溃,核心原因在于模型将物体身份与环境上下文“纠缠”在一起。OA-WAM 通过在 Transformer 架构内部引入硬性的对象寻址约束,实现了物体定位与状态建模的张量级解耦,在多个基准测试中刷新了 SOTA。
痛点深挖:为什么 VLA 模型在“搬家”后就失效了?
当前的 Vision-Language-Action (VLA) 模型(如 OpenVLA, π0)虽然在标准任务上表现惊人,但在面对场景扰动(Scene Perturbations)时异常脆弱。
研究者发现,当相机位置稍作移动或多出几个无关的干扰物体时,基于 Patch 的整体化表示(Holistic Representation)会将目标物体的特征与周围环境混合。这就导致动作解码器在处理“把红杯子放到托盘”指令时,无法在变换后的特征空间里稳定地“索引”到那个红杯子。
核心方法:OA-WAM 的“身份-内容”解耦术
OA-WAM 的核心逻辑是将场景视为一组可寻址的 Slot(槽位)。
1. 结构化 Token 设计
每一帧被分解为 个 Slot token。每个 token 由两部分组成:
- Identity Address (addr):由语言指令和初始特征计算,在整个回合中保持冻结。它代表“这是哪个物体”。
- Content (cnt):随时间变化的特征,记录物体的位姿和外观。它代表“这个物体目前怎么样”。
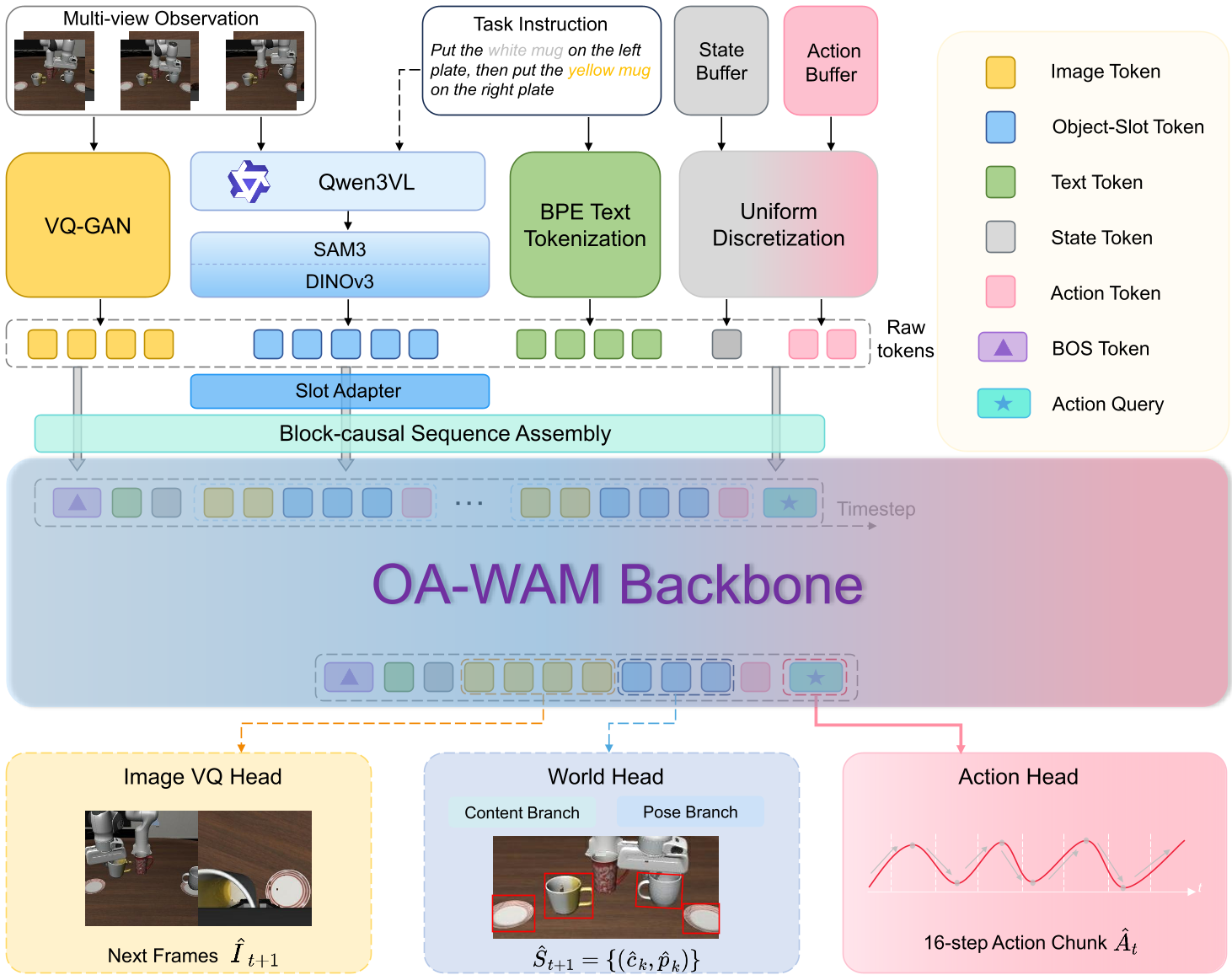
2. OA (Object-Addressable) 注意力约束
这是论文最精妙的设计。为了防止 Transformer 在加深过程中将两类特征重新混淆,作者实施了两个操作:
- 只读地址的 Key 投影:在计算注意力时,Key 向量仅由
addr部分投影生成。这意味着模型在“寻找”物体时,只能依据物体的身份地址进行路由,不受其当前位置或背景影响。 - 残差流重置(Reset Hook):在每一层 Transformer 结束后,强制将残差流中的地址部分重置为初始值,彻底切断梯度对身份信息的改写。
实验战绩:硬核鲁棒性
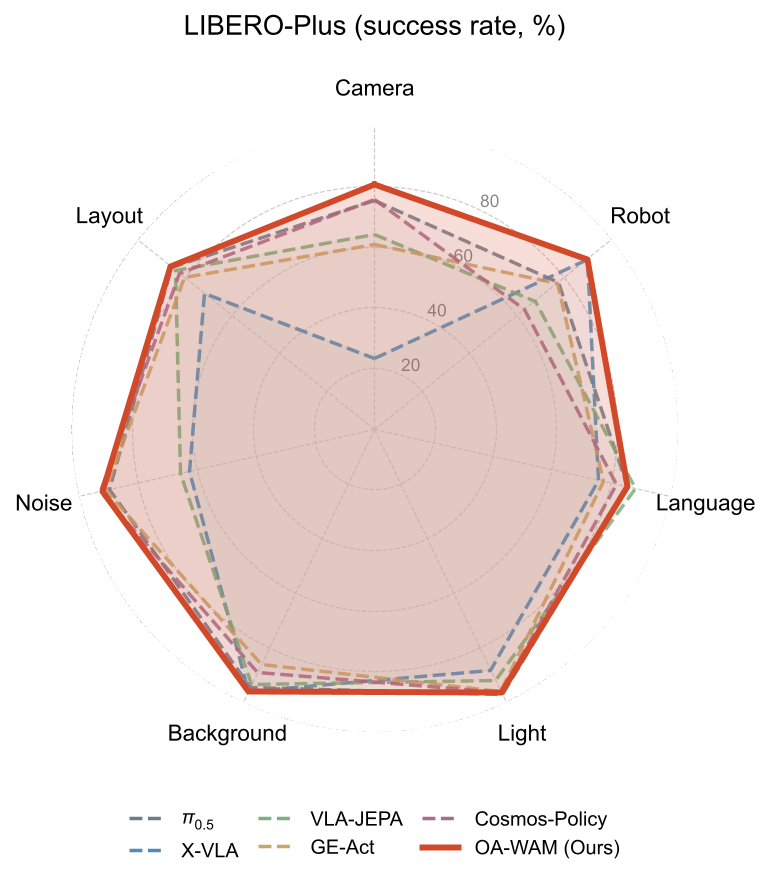
在针对鲁棒性的 LIBERO-Plus 测试中,OA-WAM 表现出了极强的几何稳定性:
- 相机视角变换 (Camera):成功率 80.5%,比之前最强的 Cosmos-Policy 提升了 4.7%。
- 机器人初态偏移 (Robot init):达到 89.6%。
- 几何平均 (Geo Avg):领先 π0.5 近 5 个百分点。
最有力的证据来自因果插值实验 (Causal Slot Intervention)。当研究者手动交换两个 Slot 的地址向量时,OA-WAM 的动作方向会立即随之偏向被交换的目标,绑定余弦相似度高达 0.87。而传统的整体式模型在面对这种干预时几乎没有反应(< 0.1),说明它们根本没有建立起稳固的物体寻址逻辑。
深度洞察与总结
OA-WAM 的成功证明了一个深刻的直觉:物理世界的动作应当锚定在对象之上,而非像素之上。 通过在模型架构设计中显式地隔离“对象身份”子空间,我们能够为机器人提供一个即便在动态变幻的环境中也依然稳定的“操作接口”。
局限性: 目前的 OA-WAM 仍依赖于 SAM 3 和 DINOv3 等预训练感知模块,这带来了约 100ms 的推理延迟。虽然对于 4.3Hz 的闭环控制已经足够,但在处理高速运动或极端遮挡时,感知层依然是系统的“软肋”。此外,针对感光噪声(Sensor Noise)的性能下滑也提示我们,前端感知的鲁棒性与后端策略的鲁棒性同样重要。
未来,这种“可寻址”的概念可以进一步扩展到多模态学习中,让机器人不仅能“听懂”指令,更能“死死盯住”任务背后的物理实体。