本文提出了 OFlow,一种将对象感知的时间流匹配(Object-Aware Temporal Flow Matching)注入 VLA 模型的机器人操纵框架。该方法通过在 DINOv2 语义潜空间中预测未来状态并进行层级化对象聚类,在 LIBERO、MetaWorld 等多个基准测试中刷新了 SOTA 记录。
TL;DR
复旦大学与南加州大学的研究团队提出了 OFlow。它通过在语义潜空间(DINOv2 Space)中引入对象感知的时间流匹配,解决了传统 VLA 模型缺乏预见、鲁棒性差的问题。OFlow 不仅能预测场景将如何演变,还能自动识别与任务相关的对象,在复杂动态任务中表现出极强的控制力。
背景:反应式控制的局限性
当前的具身智能大模型(VLA)虽然在指令遵循和物体定位上取得了长足进步(如 RT-2, OpenVLA),但本质上大多仍是“走一步看一步”的反应式策略。
- 缺乏预见(Foresight):无法理解动作对环境的长远影响。
- 表示鸿沟:预见模型(通常生成像素图)与动作策略模型(需要高层语义)往往在不同的潜空间工作,导致巨大的计算冗余。
OFlow 的核心直觉:像人一样理解语义预见
人类在操作物体时,大脑中勾勒的不是下一帧高清的像素画面,而是物体位置和状态的拓扑演变。
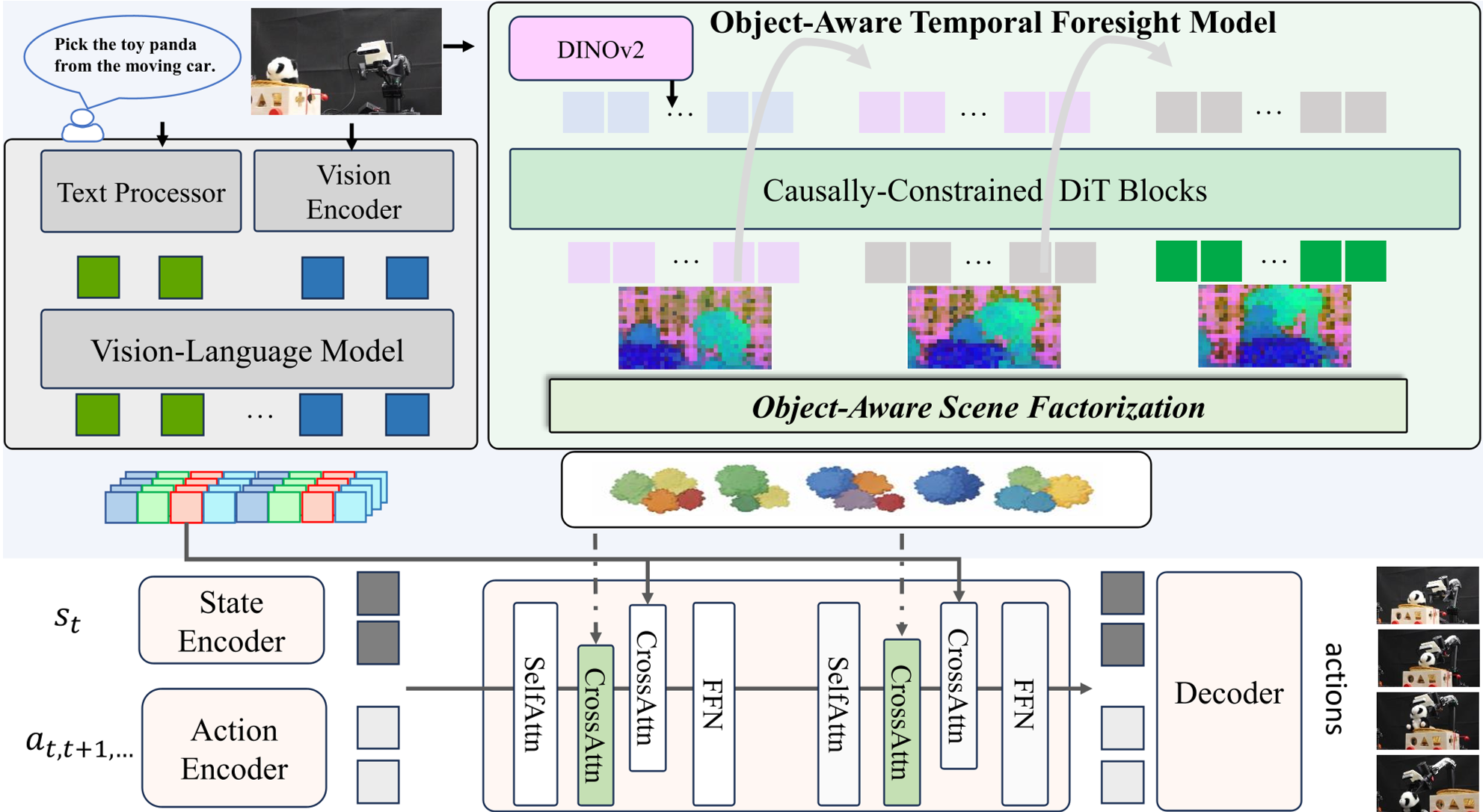
1. 语义潜空间中的流匹配
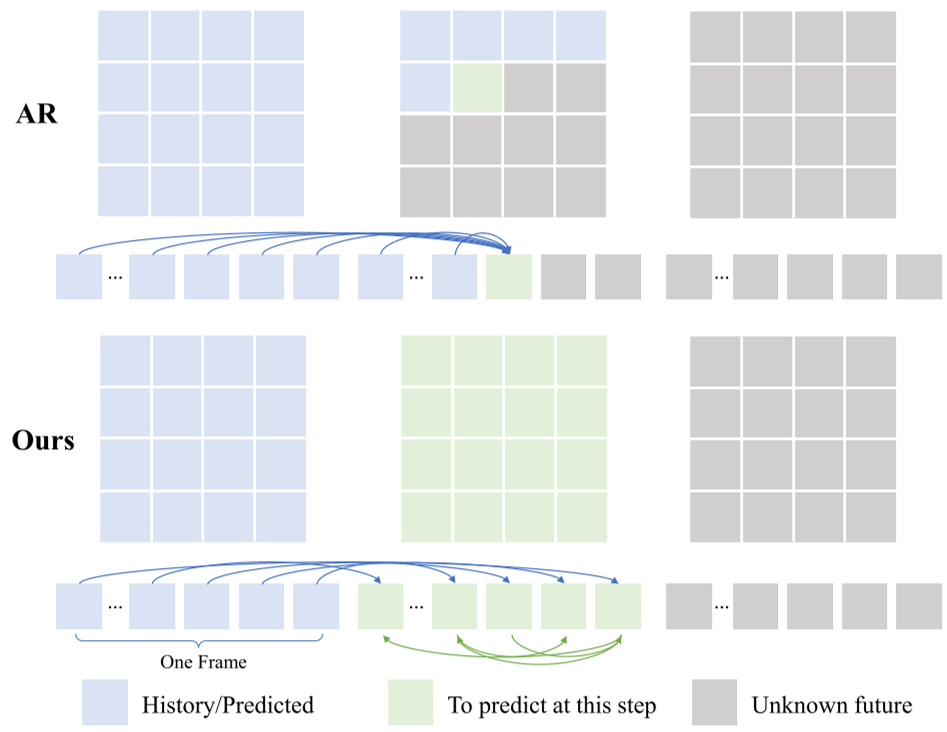
OFlow 选择在 DINOv2 的特征空间进行预测。相比于像素生成,特征预测更关注语义一致性,且对光照和纹理变化更鲁棒。它使用了一种带有**因果掩码(Causal Mask)**的自回归流匹配模型(Flow Matching),能够并行训练并高效生成未来的特征序列。
2. 对象感知场景分解 (Object-Aware Factorization)
为了进一步消除噪声,作者利用了 DINOv2 特征天然的聚类特性,通过 K-Means 将预测的未来特征分解为多个“对象原型”。
- 层级化表示:通过改变聚类中心数量 (如 2, 4, 8, 12),模型既能捕捉宏观布局,也能定位精细的物体部件。
- 过滤干扰:将背景等任务无关的变动从状态表示中剔除。
3. 受控的动作生成
利用 ControlNet 的思想,OFlow 将这些预见的“对象特征”注入到预训练的 VLA 框架中。通过零初始化的交叉注意力机制(Zero-initialized Cross-Attention),模型可以在保留原有 VLM 知识的同时,学会利用预见信息。
实验与战绩
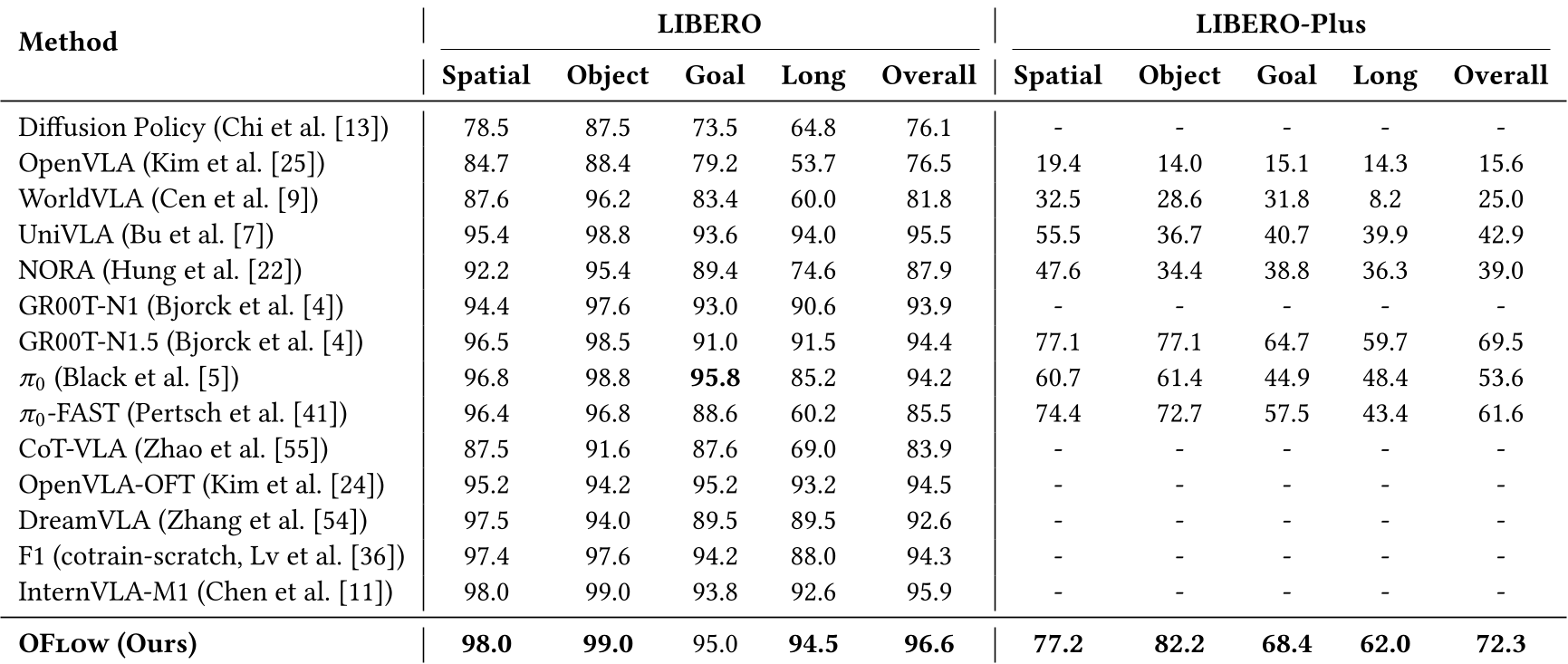
OFlow 在四大仿真基准(LIBERO, LIBERO-Plus, MetaWorld, SimplerEnv)上进行了全面测试,并开展了 7 项真实场景任务。
- LIBERO-Long (长程任务):成功率提升至 94.5%,显著高于不具备预见能力的模型。
- 动态环境表现:在“从移动小车上抓取熊猫”任务中,OFlow 表现出了极高的协调速度,成功率为 70%,而基线模型仅为 20% 左右。这是因为 OFlow 提前预测了小车的运动轨迹。
深度洞察:为什么 OFlow 有效?
- 特征预见的稳定性:像素生成往往会因为一点伪影导致动作策略崩溃,但 DINOv2 特征即便稍有偏差,其语义核心依然稳定。
- 动作块(Action Chunk)的协同:OFlow 每 16 步推演一次未来,这与动作分块执行完美契合,既降低了延迟(约 120ms),又保证了动作的连贯性。
总结与展望
OFlow 的成功表明,语义级别的视频预见是机器人走向复杂任务的关键。它跳出了“生成精美视频”的怪圈,回归到“辅助决策”的本质。 局限性:尽管其预见模型相对轻量,但在资源极其受限的端侧设备上仍有优化空间。此外,对于高度形变的物体(如流体),当前的聚类分解可能还不够精细。
未来,这种将“预见性”与“对象中心化表示”结合的思路,很可能会成为通用具身智能的标准配置。