ReVal is a novel off-policy value-based reinforcement learning framework for LLM post-training that interprets model logits as Q-values to enable efficient experience replay. It combines stepwise internal consistency signals with trajectory-level outcome rewards, achieving state-of-the-art results on mathematical reasoning benchmarks like AIME and GPQA while being significantly more sample-efficient than on-policy methods like GRPO.
TL;DR
Reinforcement Learning (RL) has become the cornerstone of "O1-style" reasoning models. However, mainstream methods like GRPO are fundamentally on-policy, meaning they are "data hungry"—they generate expensive reasoning traces, use them once, and throw them away. ReVal changes this by treating LLM logits as Q-values, allowing the model to "re-read" its past experiences through a replay buffer. This approach achieves comparable or superior performance to SOTA baselines while being up to 4.3x faster in convergence.
Problem & Motivation: The "Expensive Rollout" Trap
The current paradigm of Reinforcement Learning with Verifiable Rewards (RLVR) faces a massive efficiency wall. In complex reasoning or agentic tasks, generating a single trajectory (a "rollout") is incredibly slow and computationally expensive.
Standard Actor-Only methods like GRPO or ReMax have lowered memory overhead but remain on-policy. They suffer from two major flaws:
- Low Sample Efficiency: Trajectories are discarded immediately after one gradient step.
- Coupled Generation-Update: Total training time is dominated by autoregressive generation ($T_{generation} \gg T_{update}$).
To solve this, we need Off-Policy RL, which allows the model to learn from historical data stored in a Replay Buffer.
Methodology: Unifying Policy and Value
The researchers introduce ReVal, a value-based framework built on two clever insights:
1. Logit-as-Q Parameterization
Instead of training a separate, memory-heavy Value Network (Critic), ReVal treats the LLM's own logits as soft Q-values. This means the same weights that predict the next token also estimate the long-term "value" of that token.
2. Calibrated Initialization & Reward Shaping
Previous attempts at this (like TBRM) failed a crucial test: if the reward is zero, the model should stay the same as the starting (reference) model. ReVal fixes this by introducing a specific Bellman residual loss with reward shaping:
$$L_{ReVal}( heta) = \sum_{ au \in \mathcal{D}} (V_{ heta}(s_1) - V_{ref}(s_1) + \log \pi_{ heta}( au) - \frac{r_{rule}( au)}{\beta} - \log \pi_{ref}( au))^2$$
This formula ensures that at the start of training (when $r=0$), the gradient is zero, preventing the "spurious policy drift" that plagues other value-based methods.
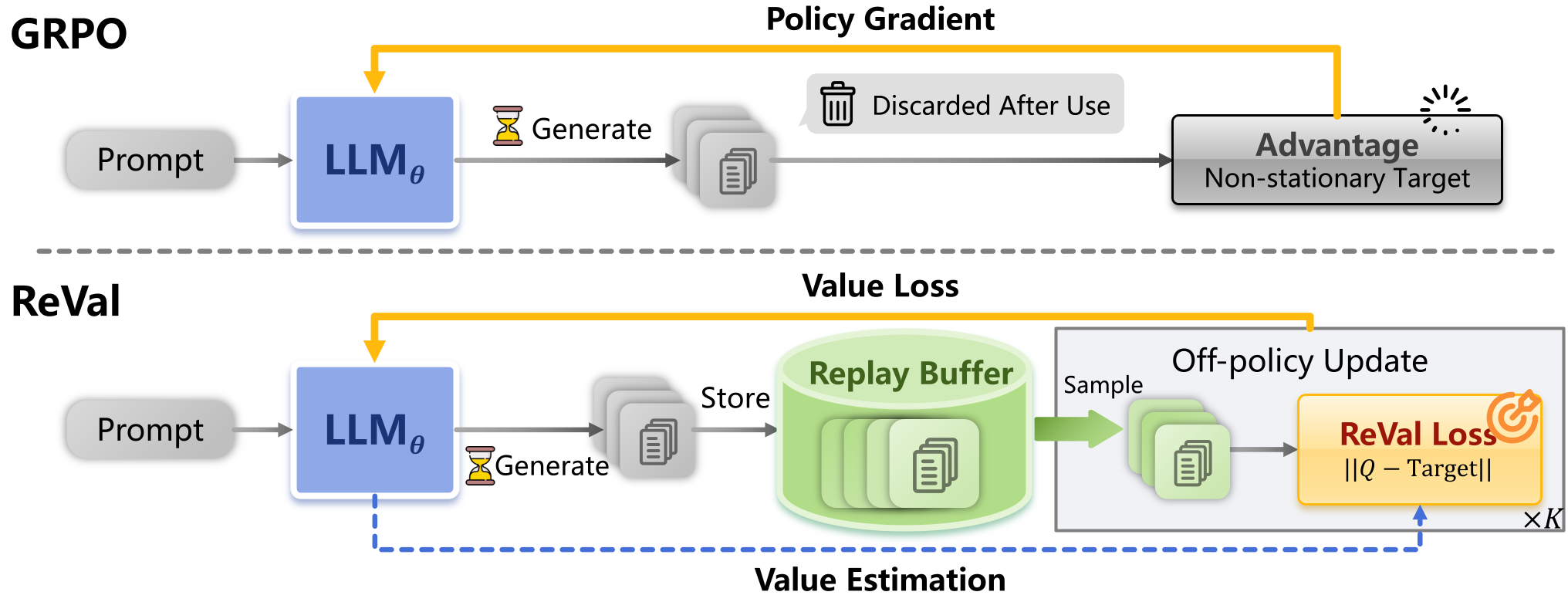 Figure 1: ReVal Framework. By unifying policy and value via logits, it enables the use of an off-policy Replay Buffer.
Figure 1: ReVal Framework. By unifying policy and value via logits, it enables the use of an off-policy Replay Buffer.
Experiments: Speed Meets Stability
ReVal was tested against GRPO and TBRM on various reasoning benchmarks using DeepSeek-R1-Distill-1.5B and Qwen2.5-Math-7B.
Dramatic Convergence Speedup
Across easy, medium, and hard tasks, ReVal reaches peak performance significantly faster than GRPO. On "Hard" tasks, it achieves the same threshold in ~10 updates compared to GRPO's 33, representing a 3.6x to 5.2x speedup.
Superior Reasoning Performance
In final accuracy, ReVal consistently beats on-policy baselines:
- AIME24: +2.7% improvement over GRPO.
- GPQA (Out-of-Domain): +4.5% improvement, showcasing better generalization.
- Performance @ N=1: When rollouts are strictly limited (one sample per prompt), ReVal's lead grows even further (up to +4.8% on AIME), proving that the ability to reuse data is a "superpower" in data-constrained environments.
 Figure 2: Performance curves on DPSK-R1-Distill-1.5B. ReVal (purple) maintains a clear lead in accuracy and stability throughout training.
Figure 2: Performance curves on DPSK-R1-Distill-1.5B. ReVal (purple) maintains a clear lead in accuracy and stability throughout training.
Critical Analysis & Insights
The success of ReVal hinges on three "Tuning Secrets" revealed in the paper:
- Periodic Reference Reset: The KL penalty $\log \pi_ heta/\pi_{ref}$ grows over time, which eventually "muffles" the gradient signal. Periodically updating $\pi_{ref}$ to the current $\pi_ heta$ "refreshes" the learning signal.
- The Right $\beta$: Longer responses (like those from DeepSeek-R1) need a smaller $\beta$ (0.002) because log-ratios accumulate over more tokens.
- Negative Samples: Using Normalized Advantage (standardizing rewards across a batch) is significantly more effective than simple +1/-1 binary rewards for value learning.
Limitations
While ReVal is powerful, it currently uses a simple FIFO (First-In-First-Out) buffer. Future iterations could likely extract even more performance by using Prioritized Experience Replay (PER)—focusing the model on the most "surprising" or educational failures.
Conclusion
ReVal proves that we don't need to choose between memory efficiency and data efficiency. By treating an LLM as its own value model, we can finally stop the wasteful "sample-and-discard" cycle of on-policy RL, paving the way for more complex, long-horizon AI agents.