This paper introduces an offline Reinforcement Learning (RL) approach for the Traveling Salesman Problem (TSP) by adapting the Decision Transformer (DT) framework. By integrating a Pointer Network and optimistic Return-to-Go (RTG) prediction via expectile regression, the method significantly outperforms the four classical heuristics (NN, NI, FI, SA) it was trained on.
TL;DR
Researchers have successfully applied the Decision Transformer (DT) to the Traveling Salesman Problem (TSP) in an offline setting. By training on data from existing heuristics (like Simulated Annealing), the model doesn't just copy them—it outperfroms them. Key innovations include a Pointer Network head for node selection and Expectile Regression for predicting optimistic performance targets, allowing the model to "stitch together" the best parts of sub-optimal solutions.
Background & Motivation: Beyond the Online Bottleneck
Neural Combinatorial Optimization (NCO) has traditionally lived in the realm of Online Reinforcement Learning. While effective, online RL is a "data hungry" beast that ignores the treasure trove of existing heuristic algorithms (NN, FI, SA) developed over decades.
The challenge? Standard Offline RL frameworks like the Decision Transformer are built for environments with fixed action meanings (e.g., "move left"). In TSP, "Node 5" means something different in every instance. Furthermore, the "Return-to-Go" (RTG) varies wildly; a tour length of 4.0 might be amazing for one graph but terrible for another.
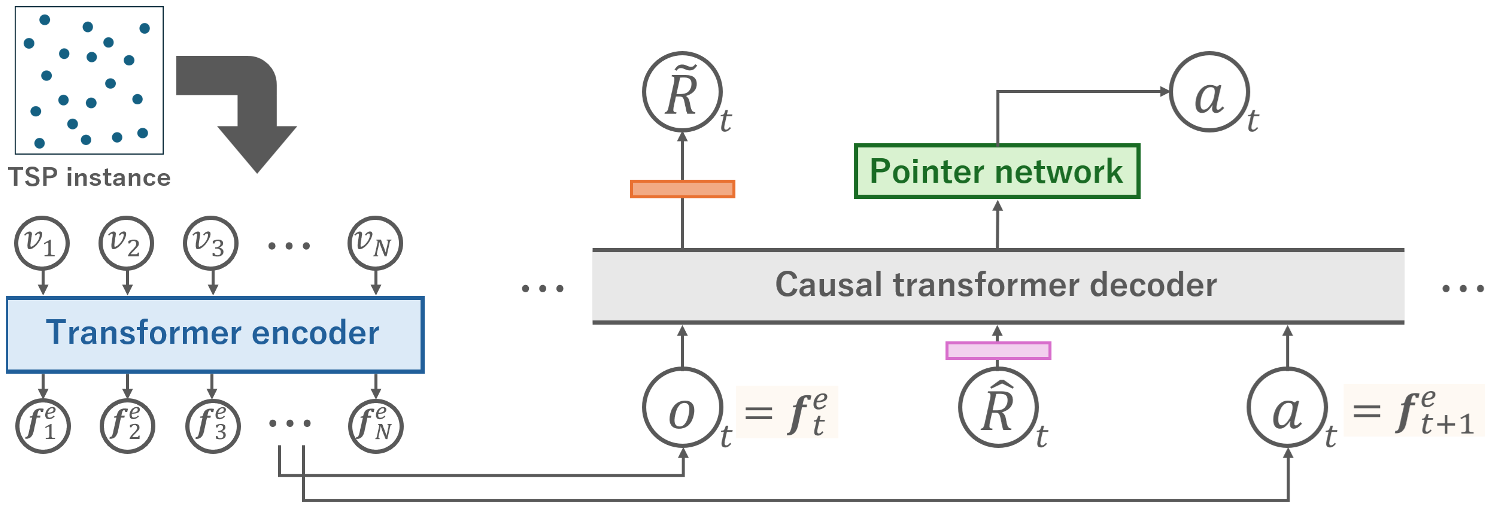
Methodology: The NCO-Decision Transformer
To bridge the gap between sequence modeling and graph optimization, the authors introduced two critical modifications:
1. Pointer Network Action Head
Instead of a fixed softmax over indices, the model uses a Pointer Network mechanism. It looks at the current Transformer state and "points" to node embeddings generated by an initial Encoder. This preserves spatial context and allows the model to handle variable graph sizes.
2. Optimistic RTG Prediction with Expectile Regression
If you tell a DT to reach a target it has never seen, it fails. If you give it an average target, it acts... average. The authors use Expectile Regression ($\alpha=0.99$) to predict the best possible return (lowest cost) for a given graph. This "optimistic conditioning" pushes the model to explore the upper bounds of the behavioral policy it observed in the training data.
Experimental Breakthroughs
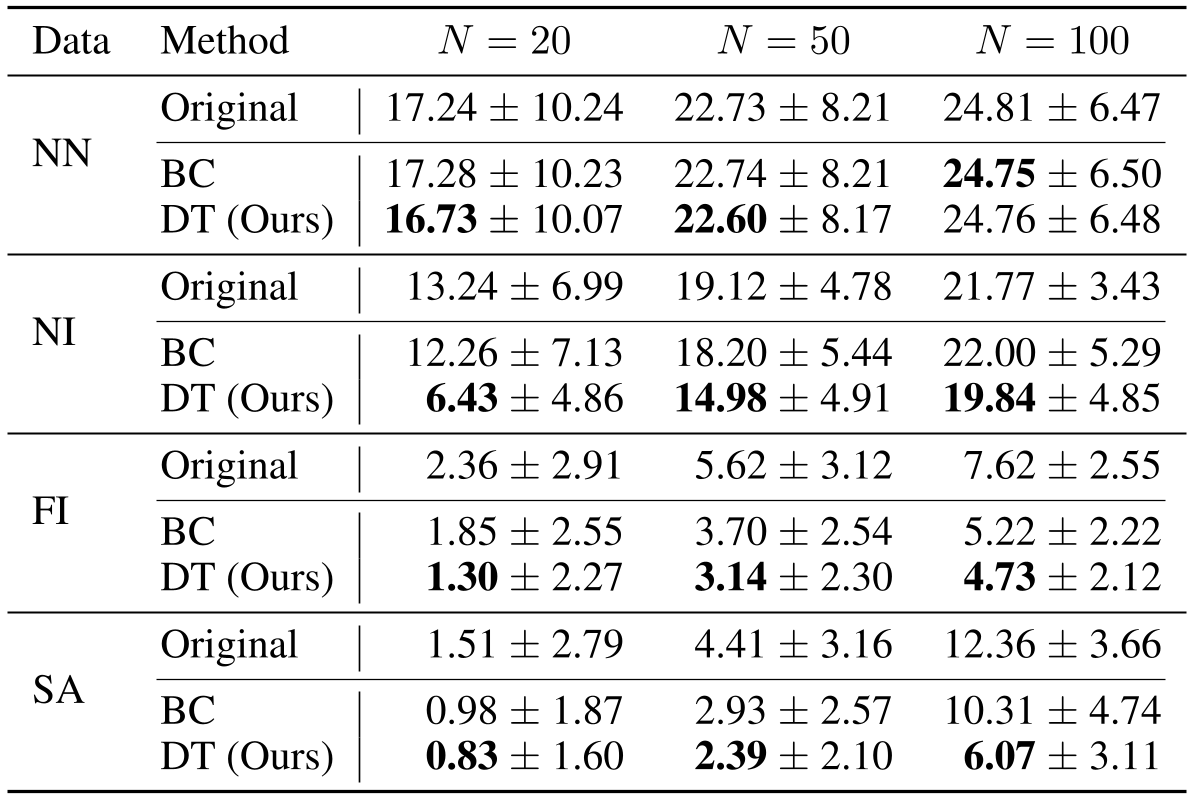
The results are striking. Across various heuristics, the DT model consistently achieved a lower Optimality Gap than the data it was trained on.
- The "Stitching" Effect: On Simulated Annealing (SA) data for N=100, the original heuristic had a 12.36% gap. The DT reduced it to 6.07%. This suggests that the Transformer is learning to identify high-quality sub-tours and recombine them more effectively than the stochastic SA process.
- RTG vs. Behavior Cloning (BC): Simple imitation (BC) failed to match the DT's performance. Without the RTG "goal," the model lacks the guidance to choose the trajectory leading to the global optimum.
Deep Insight: The Value of "Optimism"
The ablation study on the expectile parameter $\alpha$ reveals a core truth: higher $\alpha$ values (putting more weight on under-prediction errors) lead to better solutions. By training the model to expect better-than-average returns, we transform a sequence predictor into an optimizer. However, the authors noted that even their "optimistic" predictions were sometimes conservative—adding a manual offset to the RTG during inference yielded even better results in some cases.
Conclusion & Future Outlook
This work repositioned the Decision Transformer as a powerful tool for Combinatorial Optimization. It proves that we don't always need to "reinvent the wheel" with expensive online RL; instead, we can use the "wheels" we already have (heuristics) to train models that are faster and smarter.
Limitations: The model is still sensitive to the diversity of training data. As seen with the Nearest Neighbor (NN) heuristic, if the training data lacks variety, the DT has no "better paths" to discover. Future research will likely focus on mixing multiple heuristics to create a "Super-Heuristic" via Offline RL.