OmniCodec is a universal neural audio codec designed for low frame rate (12.5Hz/6.25Hz) modeling across speech, music, and general sound. It introduces a hierarchical semantic-acoustic disentanglement framework by leveraging the pre-trained Qwen3-Omni-AuT-Encoder to provide robust discrete representations for downstream Large Language Model (LLM) generation tasks.
TL;DR
OmniCodec is a universal audio tokenizer that achieves high-fidelity reconstruction at ultra-low frame rates (as low as 6.25Hz). By leveraging the Qwen3-Omni-AuT-Encoder, it decouples semantic content from acoustic texture, providing LLMs with "cleaner" tokens for generating speech, music, and general sound. It outperforms the Mimi codec and UniCodec in both reconstruction quality and downstream semantic perplexity.
Exploring the Semantic-Acoustic Conflict
The rise of Audio Large Language Models (Audio LLMs) has created a high demand for Audio Tokenizers. However, there is an inherent tension in codec design:
- Acoustic Fidelity requires high bitrates and high frame rates to capture every nuance of the waveform.
- Downstream Generation requires low frame rates and high semantic density to make sequence modeling tractable for Transformers.
Prior works like SpeechTokenizer or Mimi tried to bridge this gap, but they often struggle with music or general environmental sounds because their semantic supervisors (often WavLM) are biased toward speech. OmniCodec addresses this by using a more "universal" foundation: a supervised audio encoder trained on 20 million hours of diverse audio data.
Methodology: The Art of Disentanglement
OmniCodec's architecture is a masterclass in hierarchical modeling. It splits the representation into two distinct paths:
1. The Semantic Branch
Instead of learning semantics from scratch, OmniCodec uses the fixed Qwen3-Omni-AuT-Encoder. This encoder compresses 16kHz audio into a 12.5Hz semantic hidden layer. These features are then quantized (VQ) to serve as the "backbone" of the audio content.
2. The Acoustic Branch & Self-Guidance
The acoustic branch handles the residual information. The authors employ a decoupling adapter that essentially subtracts the semantic representation from the acoustic hidden features, forcing the acoustic branch to focus only on fine-grained textures.
To stabilize training and improve codebook utilization (which reached an impressive 98.2%), they introduced a Self-Guidance mechanism.
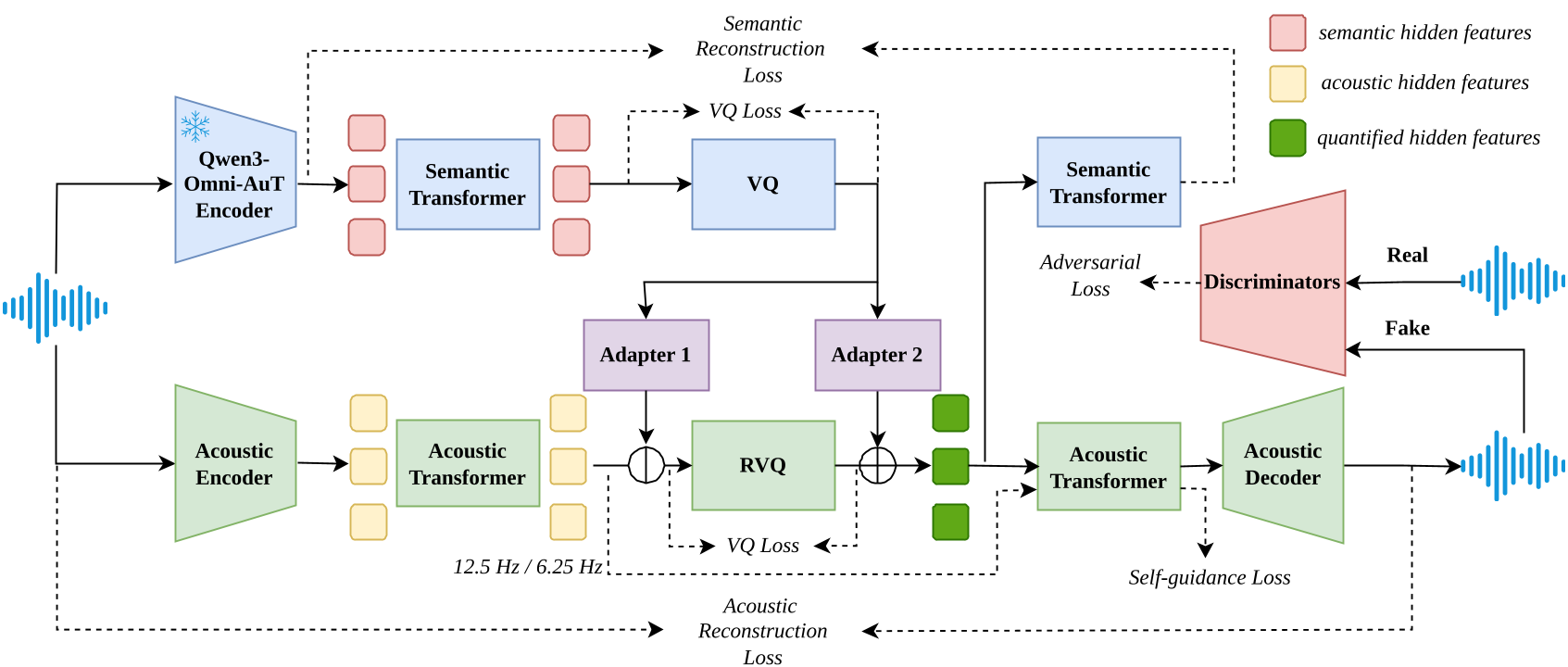
The self-guidance loss (Equation 2 in the paper) ensures the decoder can produce high-quality output even when dealing with the "noise" introduced by quantization by mimicking the continuous latent output.
Experimental Mastery: Low Frame Rate, High Fidelity
The most striking result is the comparison against UniCodec and Mimi.
- Efficiency: OmniCodec operates at 6.25Hz to 12.5Hz. Even at 6.25Hz (16 layers), it outperforms UniCodec (which runs at 75Hz) in metrics like MCD and STOI.
- Universal Performance: Unlike previous codecs that degrade outside of speech, OmniCodec maintains high Audiobox Aesthetics scores for music and general sound.
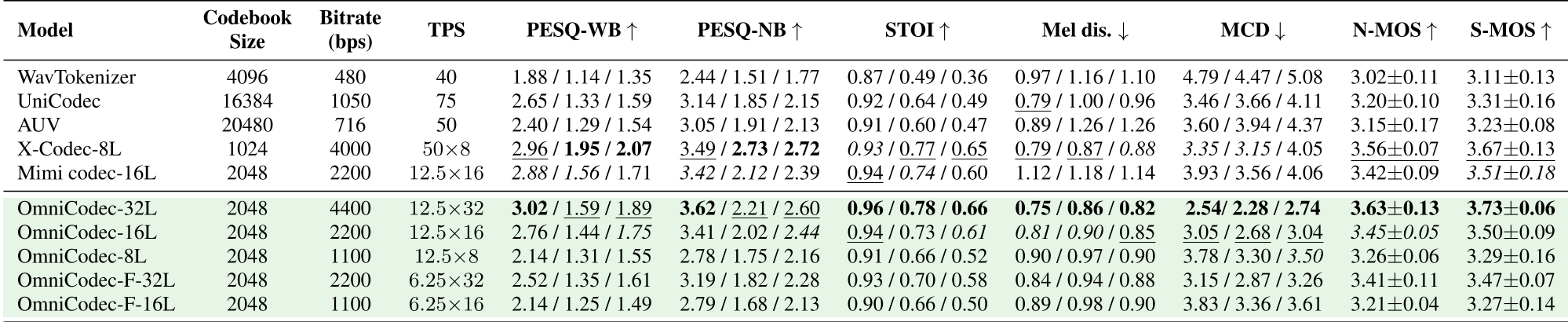
As shown in Table 1, OmniCodec-32L at 12.5Hz achieves a PESQ-WB of 3.02 for speech, significantly higher than the Mimi codec at the same bitrate.
Critical Insights: Why it Works
The success of OmniCodec hinges on the Inductive Bias provided by the supervised pre-trained encoder. While WavLM (unsupervised) is great for phone-level details, the supervised Qwen3 encoder understands high-level audio concepts across domains.
The Ablation Study verified that:
- Semantic Branch is vital for downstream LLM performance (removing it spikes Perplexity/PPL).
- Self-Guidance is the secret sauce for codebook utilization.
- Domain Ratios matter: The model's slight disadvantage in speech PPL compared to Mimi (WavLM-based) suggests that phonetic-heavy tasks still benefit from SSL-distillation, which the authors plan to address in future "joint distillation" work.
Conclusion
OmniCodec represents a significant step toward a Unified Audio Tokenizer. By moving away from speech-only semantic supervisors and embracing multi-domain pre-trained encoders, it provides a robust foundation for the next generation of Omni-modal LLMs. For developers of real-time streaming AI, its purely causal receptive field and low computational overhead make it a highly practical choice.