本文提出了 OmniJigsaw,一个通用的自监督强化学习(RL)后训练框架,旨在通过时间重排序任务(Jigsaw)提升全模态模型(Omni-modal Models)的视频、音频及协作推理能力。该方法通过三种模态编排策略,在无需人工标注的情况下,将海量无标签全模态数据转化为高质量推理训练素材。
TL;DR
OmniJigsaw 是一项开创性的工作,它通过**自监督的时间重排序(Jigsaw)任务,解决了全模态模型(Omni-modal LLMs)在后训练阶段缺乏高质量推理数据的问题。通过巧妙的“剪辑级模态掩码(CMM)”**策略,它不仅提升了模型对视频和音频的独立理解能力,更强化了跨模态的协作逻辑。在 Qwen3-Omni 上的实验显示,该方法在多个视频和音频推理榜单(如 MLVU, MMAR)上取得了显著增长。
1. 核心动机:当全模态遇到“捷径”
大语言模型通过 RLHF 或 R1 这种强化学习后训练(Post-training)获得了惊人的推理能力。但在全模态(文本+音频+视频)领域,由于缺乏像数学题那样具有“自动验证(Verifiable)”属性的高质量推理标签,RL 的应用一直受限。
作者发现,如果简单地让模型对打乱顺序的音视频片段进行排序(联合模态集成,JMI),模型会产生**“双模态捷径效应”**:
- 场景:如果音频里有人说话,视觉上有动作。
- 现状:模型可能只听音频就能排好序,从而不再去仔细观察视觉层面的细微动作演变。
- 后果:这导致模型在推理上“偷懒”,无法真正建立起跨模态的深层关联。
2. OmniJigsaw:全模态推理的重塑
为了解决上述问题,OmniJigsaw 提出了三种模态编排(Orchestration)策略,将简单的排序任务升级为复杂的逻辑博弈:
2.1 三大编排策略(Orchestration Strategies)
- Joint Modality Integration (JMI):全模态开放。实验证明这往往适得其反,容易触发“捷径”。
- Sample-level Modality Selection (SMS):根据全样本判断哪种模态最有信息量,然后只保留该模态。
- Clip-level Modality Masking (CMM) [核心贡献]:在同一视频的不同片段中,有的只给看画面,有的只给听声音,有的都给。这强制模型必须像做拼图一样,通过声音去推测被遮挡的画面内容,再结合画面推测声音的顺序。
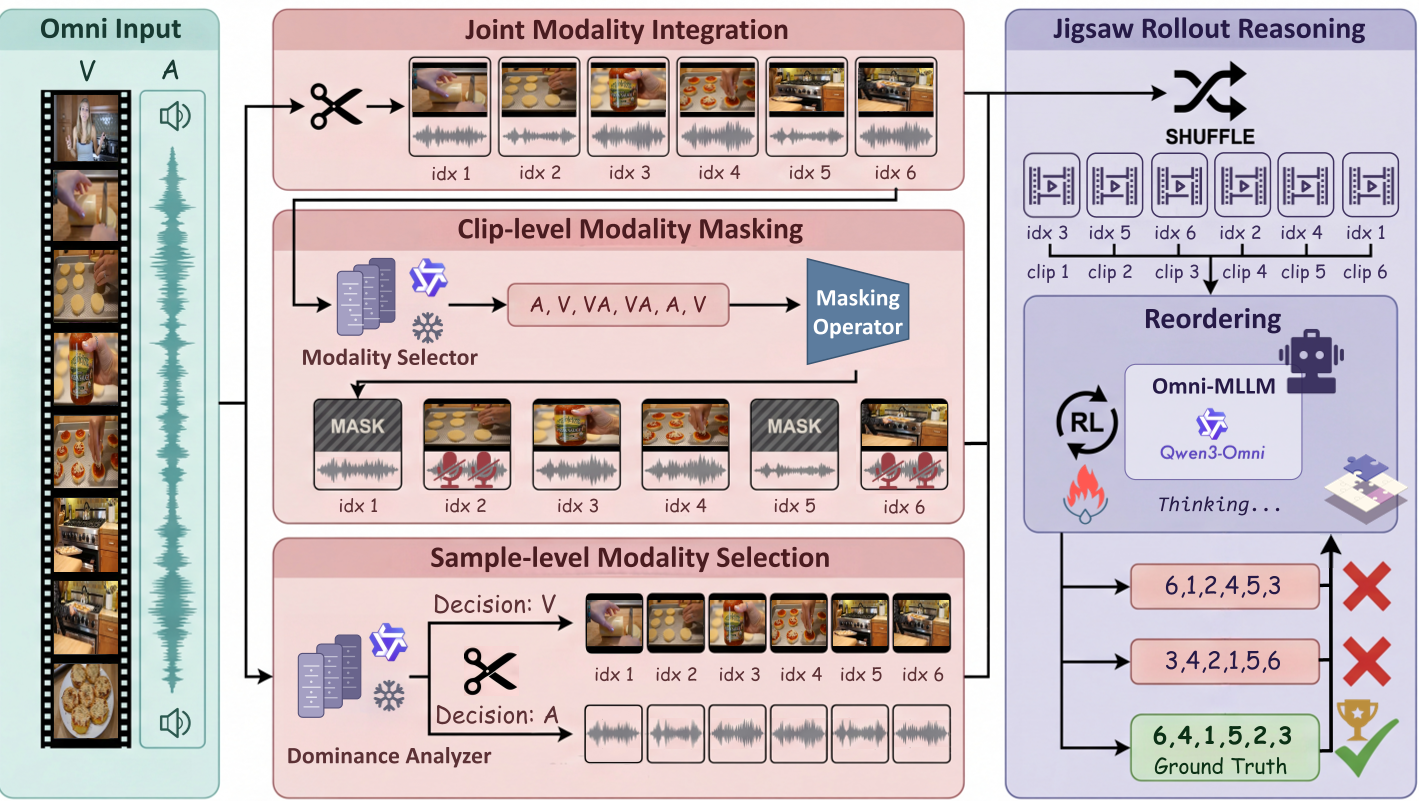 图1:OmniJigsaw 框架展示了三种策略。CMM(中间部分)通过制造信息瓶颈,迫使模型利用跨模态线索。
图1:OmniJigsaw 框架展示了三种策略。CMM(中间部分)通过制造信息瓶颈,迫使模型利用跨模态线索。
3. 方法论深度解析
3.1 两阶段数据过滤
Jigsaw 任务的质量高度依赖于原始视频是否有**“时间不可逆性”**。如果一个视频是重复的循环动作(如点头),打乱顺序后根本无法还原。
- 第一阶段(信号过滤):通过 MAD 算法检测视觉运动,通过 VAD 检测人声比例,剔除静态或纯底噪视频。
- 第二阶段(语义筛选):使用一个轻量级 MLLM(如 Qwen2.5-VL-7B)通过 Chain-of-Thought (CoT) 判断视频是否存在清晰的因果链条(例如:加面粉 -> 揉面 -> 进烤箱)。
3.2 复合奖励机制(Reward Design)
除了基本的排序正确率奖励,作者引入了一个关键设计:准确率依赖折扣因子 。
- 如果模型预测结果不完全匹配 ground-truth(即使只差一个位置),奖励会大幅打折。
- 这种“全对才得高分”的设计,极大地压制了局部最优解,迫使模型在 RL 过程中追求完美的逻辑还原。
4. 实验结果:全方位的性能飞跃
OmniJigsaw 在 15 个基准测试中表现卓越,尤其是在需要复杂逻辑推理的任务上。
| 任务类型 | 基准测试 | 提升幅度 (相对于 Qwen3-Omni) | | :--- | :--- | :--- | | 视频逻辑推理 | MLVU-Test | +4.38 | | 基础时间感知 | AoTBench | +4.02 | | 音频层次推理 | MMAR | +2.50 | | 全模态协作 | OmniVideoBench | +1.70 |
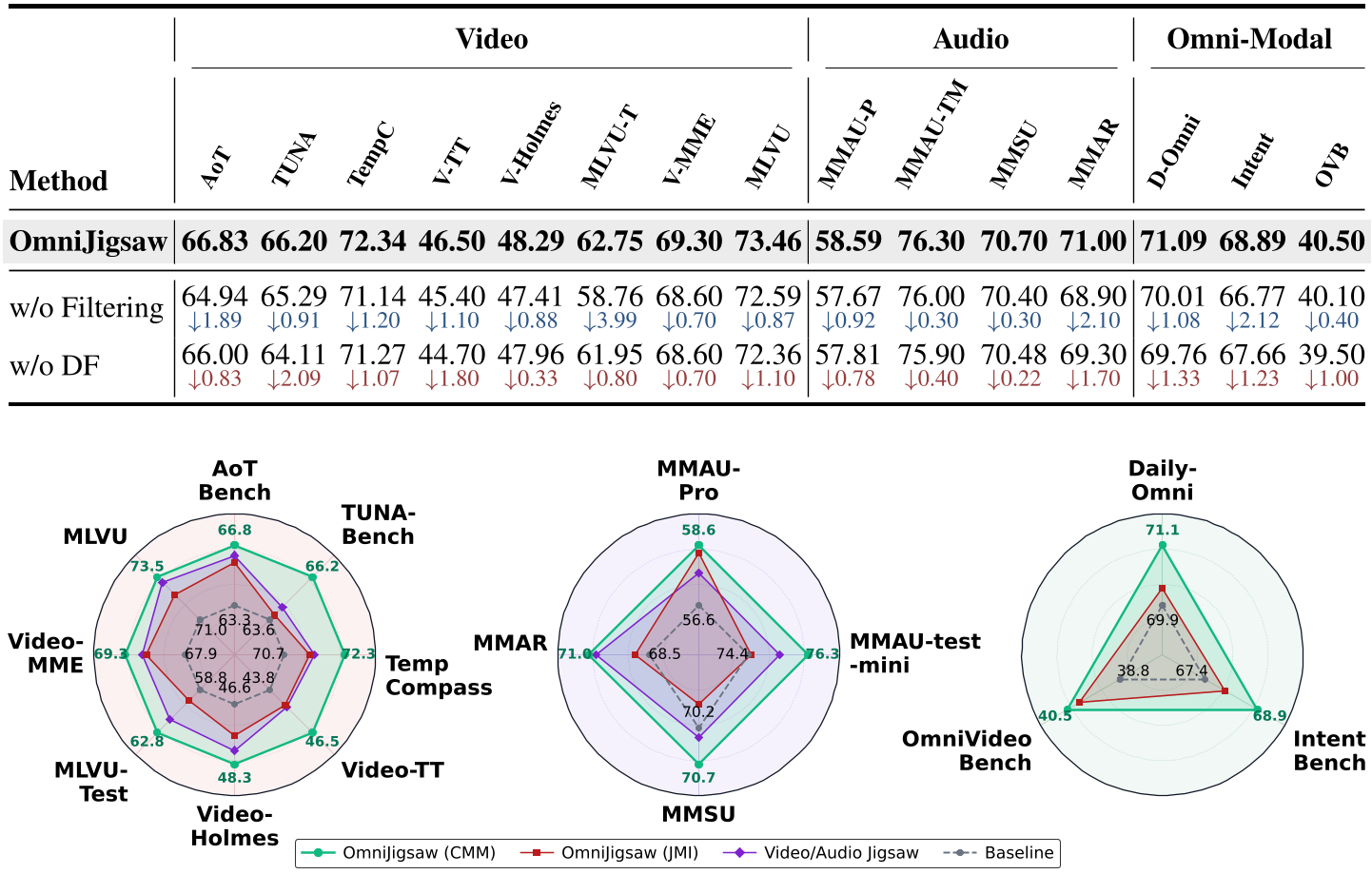 图2:JMI vs CMM 的对比分析。可以看到 CMM 策略在所有模态维度上都显著优于基础的拼图任务(VideoJigsaw/AudioJigsaw)。
图2:JMI vs CMM 的对比分析。可以看到 CMM 策略在所有模态维度上都显著优于基础的拼图任务(VideoJigsaw/AudioJigsaw)。
5. 深度洞察:为什么 CMM 这么强?
在消融实验中,作者揭示了一个有趣的直觉:粒度决定推理深度。
- SMS(样本级) 虽然去除了噪声,但因为它只关注全局最强的模态,导致模型丢失了局部的、互补的细微线索。
- CMM(剪辑级) 制造了**“跨模态语义缝合”**的需求。由于信息在时间轴上是不对称分布的,模型必须在 <thinking> 过程中进行这种推导:“片段 A 的这一段对话似乎在回应片段 B 中的一个动作,所以 A 一定在 B 之后”。这种推理过程极大地增强了模型对长程因果逻辑的建模能力。
6. 局限性与展望
尽管 OmniJigsaw 在自监督推理后训练上迈出了一大步,仍有提升空间:
- 谜题设计的丰富度:目前使用等长片段,未来可尝试变长片段、重叠片段甚至时空混合拼图。
- 在线自适应训练:目前的过滤是离线的,如果能根据模型当前的推理水平动态调整“拼图”的难度(课程学习),效果可能会更进一步。
总结
OmniJigsaw 证明了:不需要昂贵的人工标注,仅仅通过物理世界本身的时间拓扑结构(Time Reordering),辅以合理的“信息屏障”设计,就能有效催化出全模态大模型的推理之光。 这种自监督 RL 范式为构建具备真正世界模型(World Models)能力的 AI 代理指明了道路。
本博客由资深学术技术主编重构。原文引用: Yiduo et al, "OmniJigsaw: Enhancing Omni-Modal Reasoning via Modality-Orchestrated Reordering", arXiv:2604.08209, 2026.